


By intertwining the development of artificial intelligence combined with large language models with reinforcement learning in high-performance computation, the newly developed Reasoning Language Models may leap beyond traditional ways of limitation applied to processing by language systems toward explicit and even structured mechanisms, enabling complex reasoning solutions across diverse realms. Such model development achievement is the next significant landmark for better contextual insights and decisions.
The design and deployment of modern RLMs pose a lot of challenges. They are expensive to develop, have proprietary restrictions, and have complex architectures that limit their access. Moreover, the technical obscurity of their operations creates a barrier for organizations and researchers to tap into these technologies. The lack of affordable and scalable solutions exacerbates the gap between entities with access to cutting-edge models, limiting opportunities for broader innovation and application.
Current RLM implementations rely on complex methodologies to achieve their reasoning capabilities. Techniques like Monte Carlo Tree Search (MCTS), Beam Search, and reinforcement learning concepts like process-based and outcome-based supervision have been employed. However, these methods demand advanced expertise and resources, restricting their utility for smaller institutions. While LLMs like OpenAI’s o1 and o3 provide foundational capabilities, their integration with explicit reasoning frameworks remains limited, leaving the potential for broader implementation untapped.
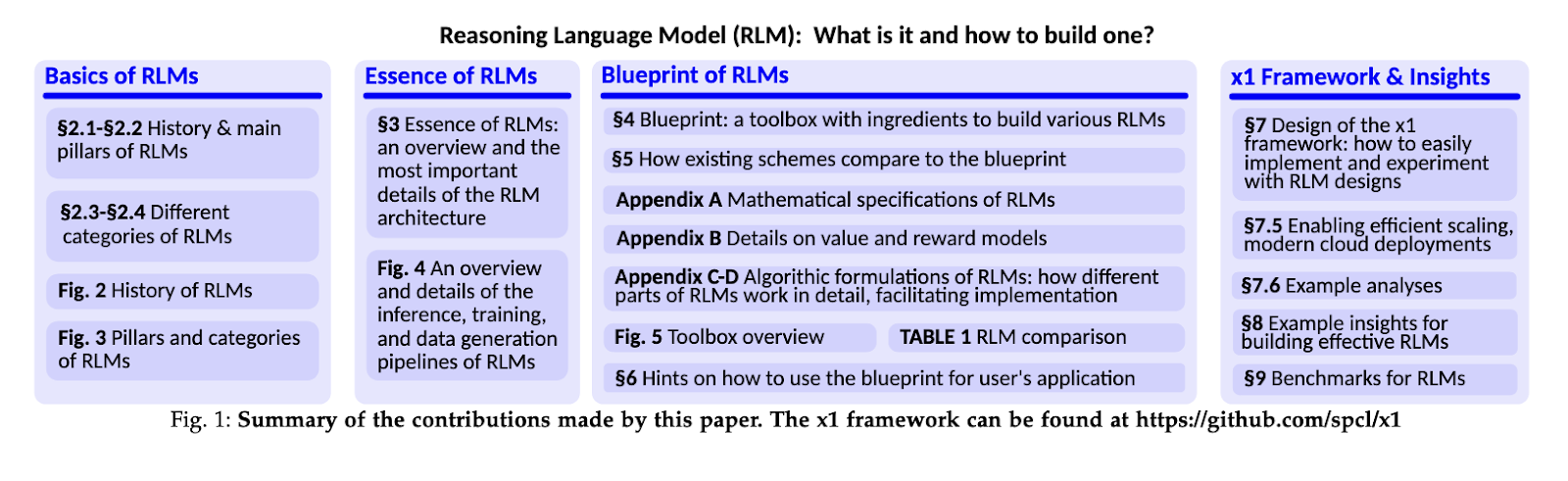
Researchers from ETH Zurich, BASF SE, Cledar, and Cyfronet AGH introduced a comprehensive blueprint to streamline the design and development of RLMs. This modular framework unifies diverse reasoning structures, including chains, trees, and graphs, allowing for flexible and efficient experimentation. The blueprint’s core innovation lies in integrating reinforcement learning principles with hierarchical reasoning strategies, enabling scalable and cost-effective model construction. As part of this work, the team developed the x1 framework, a practical implementation tool for researchers and organizations to prototype RLMs rapidly.
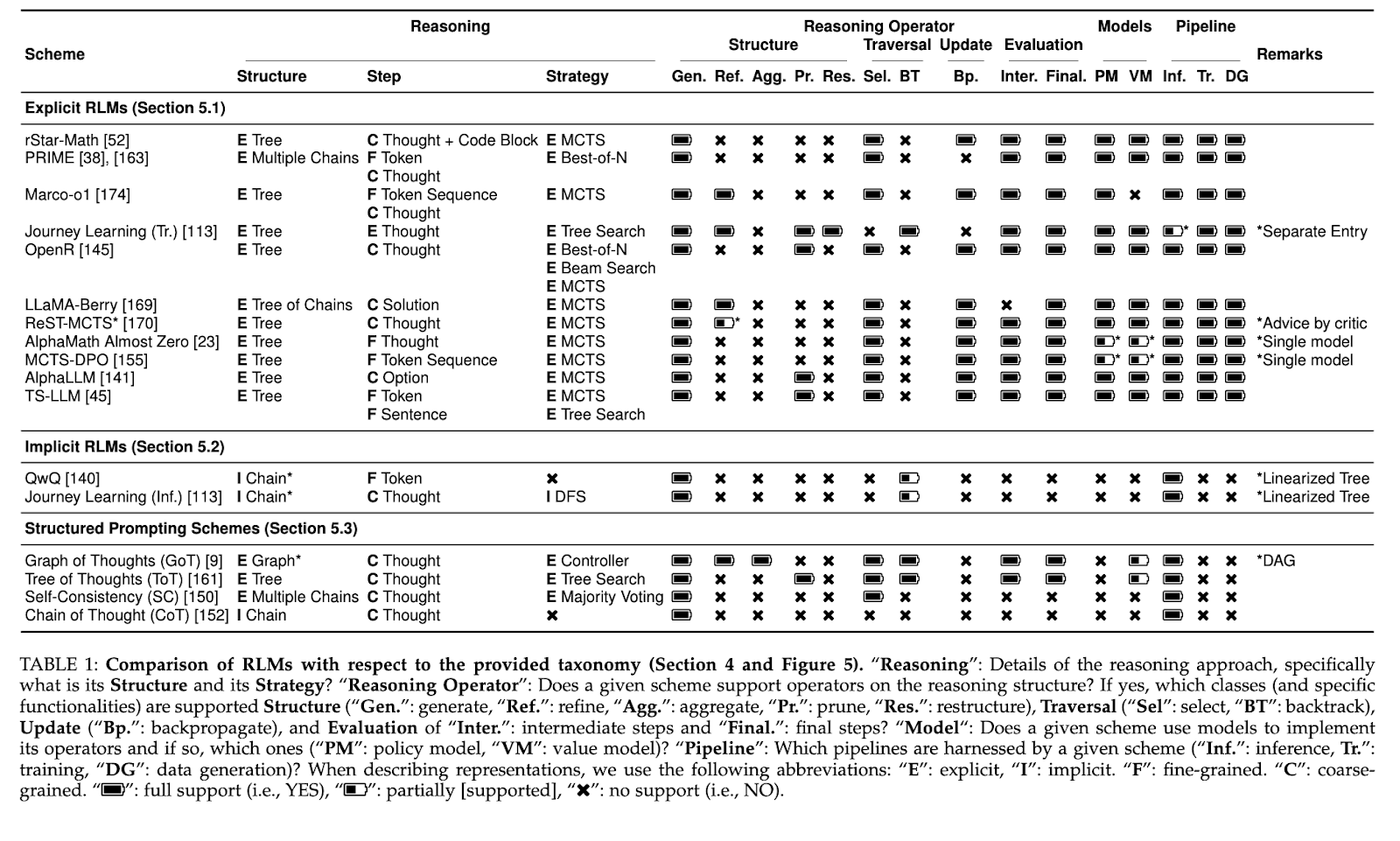
The blueprint organizes the construction of RLM into a clear set of components: reasoning schemes, operators, and pipelines. Reasoning schemes define the structures and strategies for navigating complex problems ranging from sequential chains to multi-level hierarchical graphs. Operators control how these patterns change so that operations can smoothly include fine-tuning, pruning, and restructurings of reasoning paths. Pipelines allow easy flow between training, inference, and data generation and are adaptable across applications. This block-component structure supports individual access while models can be fine-tuned to a fine-grained task such as token-level reasoning or broader structured challenges.
The team showcased the effectiveness of the blueprint and x1 framework using empirical study and real-world implementations. This modular design provided multi-phase training strategies that could optimize policy and value models, further improving reasoning accuracy and scalability. It leveraged familiar training distributions to maintain high precision across applications. Noteworthy results included large efficiency improvements in reasoning tasks attributed to the streamlined integration of reasoning structures. For instance, it demonstrated the potential for effective retrieval-augmented generation techniques through experiments, lowering the computational cost of complex decision-making scenarios. Such breakthroughs reveal that the blueprint allows advanced reasoning technologies to be democratized to even low-resource organizations.
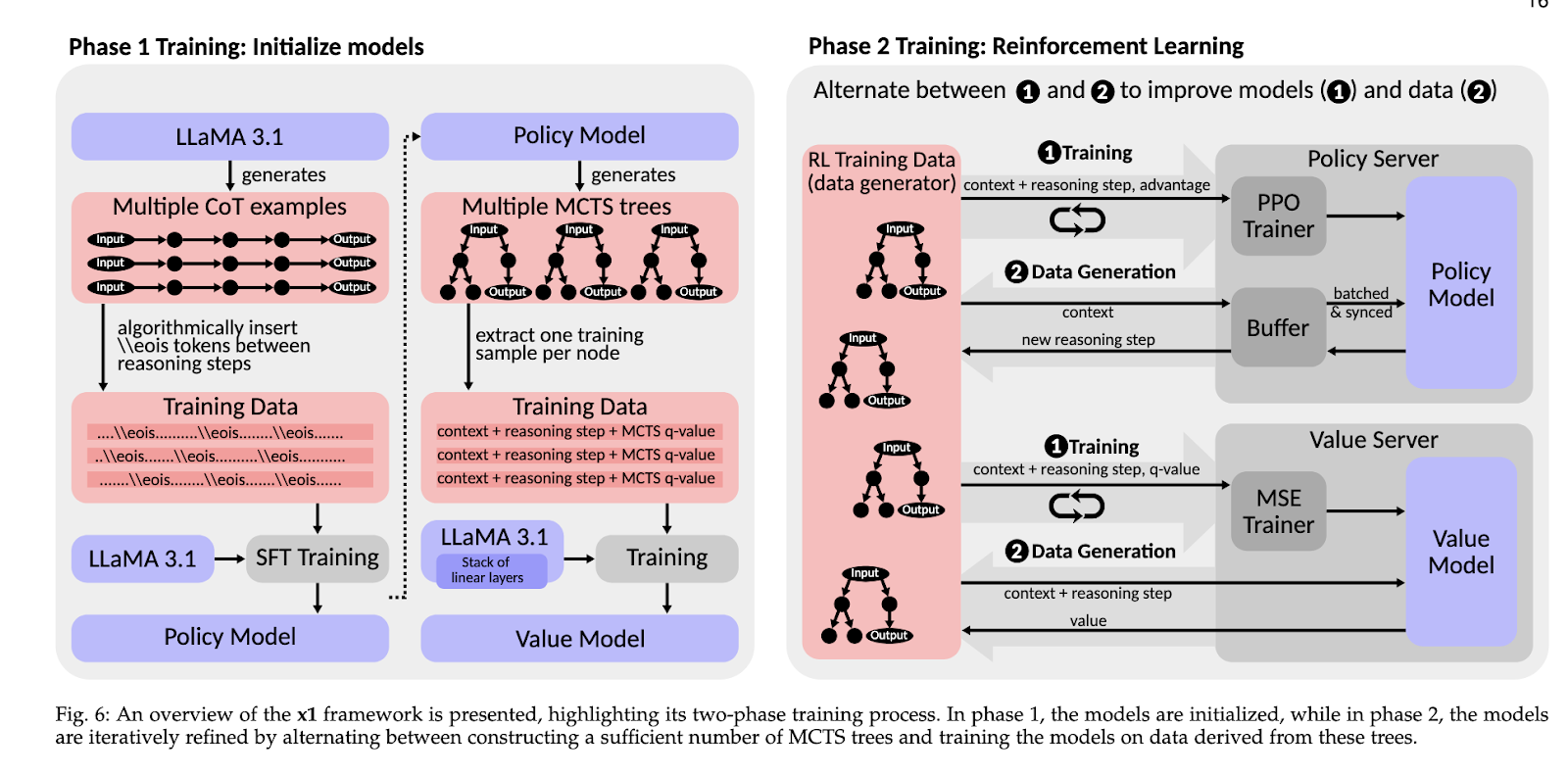
This work marks a turning point in the design of RLMs. This research addresses important issues in access and scalability to allow researchers and organizations to develop novel reasoning paradigms. The modular design encourages experimentation and adaptation, helping bridge the divide between proprietary systems and open innovation. The introduction of the x1 framework further underscores this effort by providing a practical tool for developing and deploying scalable RLMs. This work offers a roadmap for advancing intelligent systems, ensuring that the benefits of advanced reasoning models can be widely shared across industries and disciplines.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post This AI Paper Introduces a Modular Blueprint and x1 Framework: Advancing Accessible and Scalable Reasoning Language Models (RLMs) appeared first on MarkTechPost.
