


The advent of advanced AI models has led to innovations in how machines process information, interact with humans, and execute tasks in real-world settings. Two emerging pioneering approaches are large concept models (LCMs) and large action models (LAMs). While both extend the foundational capabilities of large language models (LLMs), their objectives and applications diverge.
LCMs operate on abstract, language-agnostic representations called “concepts,” enabling them to reason at a higher level of abstraction. This facilitates nuanced understanding across languages and modalities, supporting tasks like long-context reasoning and multi-step planning. LAMs, on the other hand, are designed for action execution, translating user intentions into actionable steps in both digital and physical environments. These models excel in interpreting commands, automating processes, and adapting dynamically to environmental feedback.
LCMs and LAMs offer a comprehensive framework for bridging the break between language understanding and real-world action. Their integration holds immense potential for agentic graph systems, where intelligent agents require robust reasoning and execution capabilities to operate effectively.
Large Concept Models (LCMs): An In-Depth Overview
Large Concept Models (LCMs) by FAIR at Meta elevate reasoning from token-based analysis to an abstract, language-agnostic, and modality-agnostic conceptual level. These models aim to generalize and process information with unparalleled adaptability and scalability, addressing some limitations of traditional LLMs. Their innovative architecture and approach to handling information offer unique opportunities for advanced AI applications.
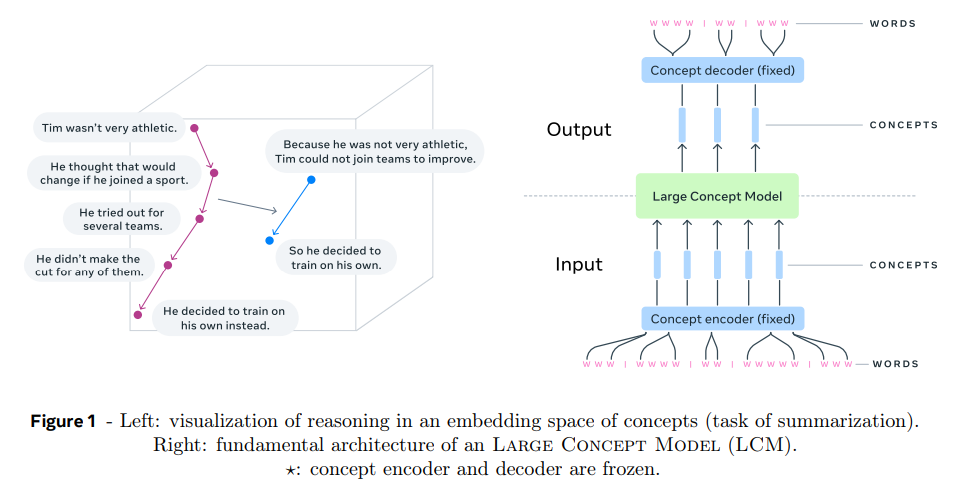
Abstract and Modality-Agnostic Reasoning
At the core of LCMs lies their ability to operate on “concepts” rather than specific language tokens. This abstraction enables LCMs to engage in reasoning that transcends linguistic or modality barriers. Instead of focusing on the intricacies of a particular language or mode of input, these models process underlying meanings and structures, allowing them to generate accurate outputs across diverse linguistic and modal contexts.
For instance, an LCM trained on English data can seamlessly generalize its capabilities to other languages or modalities, including speech and visual data, without additional fine-tuning. This scalability is attributed to its foundation in the SONAR embedding space, a sophisticated framework that supports over 200 languages and multiple modalities.
Key Characteristics of LCMs
- Hierarchical Structure for Clarity: LCMs employ an explicit hierarchical structure, enhancing long-form outputs’ readability. This design supports generating logically structured content, making it easier to interpret and modify as needed.Handling Long Contexts: Unlike traditional transformer models, whose computational complexity scales quadratically with sequence length, LCMs are optimized to handle extensive contexts more efficiently. By leveraging shorter sequences in their conceptual framework, they mitigate processing limitations and enhance long-form reasoning capabilities.Unmatched Zero-Shot Generalization: LCMs excel in zero-shot generalization, enabling them to perform tasks across languages and modalities they have not explicitly encountered during training. For example, their ability to process low-resource languages like Pashto or Burmese demonstrates their versatility and the robustness of their conceptual reasoning framework.Modularity and Extensibility: By separating concept encoders and decoders, LCMs avoid the interference and competition seen in multimodal LLMs. This modularity ensures that different components can be independently optimized, enhancing their adaptability to specialized applications.

Applications and Generalization
LCMs are useful in tasks requiring comprehensive understanding and structured reasoning, such as summarization, translation, and planning. Their ability to handle various modalities, including text, speech, and visual data, makes them ideal candidates for integration into complex AI systems. Moreover, their generalization capabilities have been proven through extensive evaluations. For example, LCMs outperform comparable models in generating coherent outputs for multilingual summarization tasks, particularly in low-resource languages.
Large Action Models (LAMs): A Comprehensive Overview
Microsoft, Peking University, Eindhoven University of Technology, and Zhejiang University have developed large action models (LAMs) that extend the capabilities of traditional LLMs to enable direct action execution in digital and physical environments. These models bridge the gap between language understanding and real-world engagement, allowing for tangible, task-oriented outcomes.
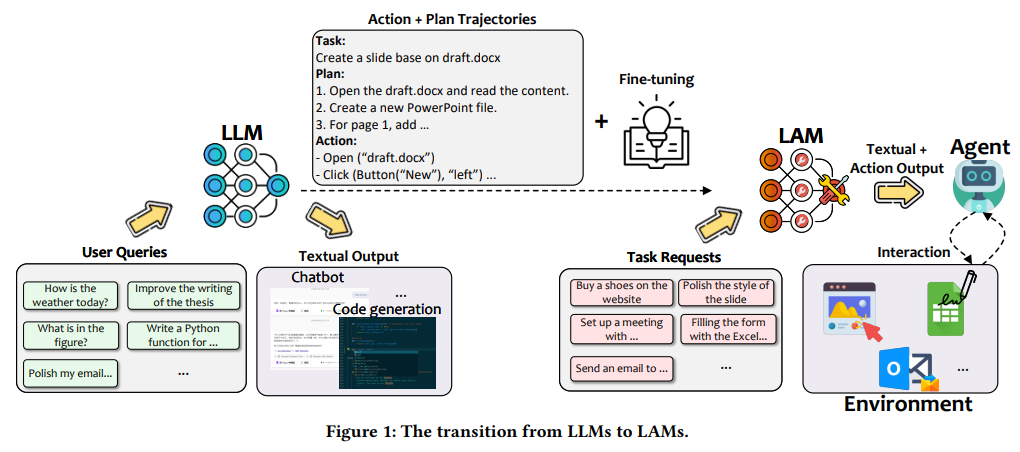
The Shift from LLMs to LAMs
While LLMs excel at generating human-like text and providing language-based insights, they are inherently limited to passive outputs. They cannot interact dynamically with the world, whether navigating digital interfaces or executing physical tasks. LAMs address this limitation by building on LLMs’ foundational capabilities and integrating advanced action-generation mechanisms. They are designed to:
- Interpret User Intentions: LAMs analyze diverse forms of input—text, voice commands, or even visual data—to discern user objectives. Unlike LLMs, which primarily generate text-based responses, LAMs translate these intentions into actionable steps.Execute Tasks in Real-World Contexts: By interacting with their environments, LAMs can autonomously perform tasks such as navigating websites, managing digital tools, or controlling physical devices. This capability represents a fundamental shift toward actionable intelligence.
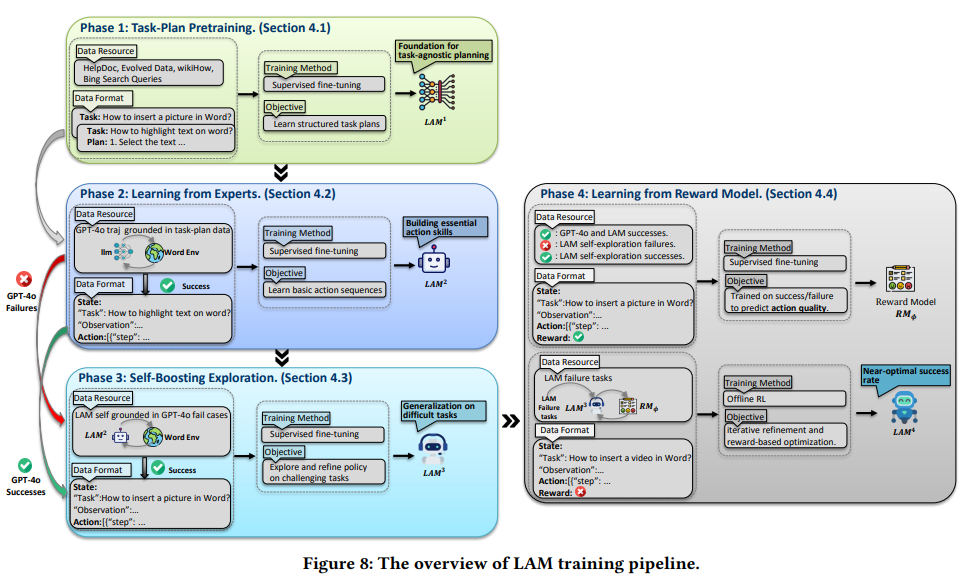
Key Characteristics of LAMs
- Action Generation: LAMs generate detailed, context-aware sequences of actions that correspond to user requirements. For example, when instructed to purchase an item online, a LAM can autonomously navigate to a website, search for the item, and complete the purchase.Adaptability: These models can re-plan and adjust actions dynamically in response to environmental feedback, ensuring robustness and reliability in complex scenarios.Specialization: LAMs are optimized for domain-specific tasks. Focusing on particular operational scopes achieves efficiency and performance comparable to or better than generalized LLMs. This specialization makes them suitable for resource-constrained environments like edge devices.Integration with Agents: LAMs are often embedded within agent systems, which provide the necessary tools for interacting with environments. These agents gather observations, use tools, maintain memory, and implement feedback loops to support effective task execution.
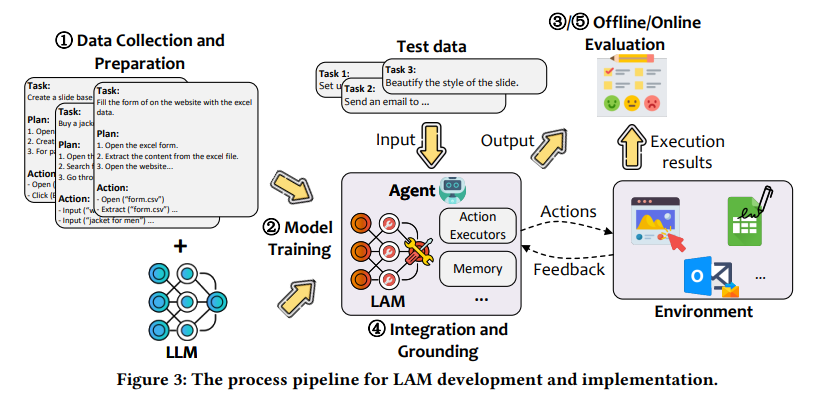
Applications of LAMs
LAMs have already demonstrated their utility in various fields. In Automated Digital Navigation, Models like GPT-V, integrated into agentic systems, have shown promise in performing web navigation tasks. They automate processes such as searching for information, completing online transactions, or managing content across multiple platforms. Also, for task automation in GUI environments, LAMs enhance human-computer interaction by automating user interface tasks and reducing manual effort in repetitive or complex operations.
LCMs and LAMs for Agentic Graph Systems
Agentic graph systems require sophisticated reasoning, planning, and action-execution capabilities to function effectively. The combination of LCMs and LAMs forms a powerful architecture that addresses these needs by leveraging the strengths of each model type.
LCMs in Agentic Systems
LCMs bring a conceptual framework that excels in reasoning and abstract thinking. They can generalize knowledge across diverse contexts by processing information in a language-agnostic and modality-agnostic manner. This makes them particularly valuable for managing long-context scenarios, where understanding dependencies and maintaining coherence are critical.
- Hierarchical Planning: LCMs’ ability to operate with explicit hierarchical structures aids in structuring plans and outputs. This hierarchical reasoning is crucial in agentic graph systems, which often involve complex, multi-step tasks.Cross-Modality Integration: By functioning on SONAR embeddings, LCMs support multi-modal data inputs, such as text, speech, and visual data. This ensures seamless integration across different information sources in an agentic graph system.
LAMs in Agentic Systems
LAMs, focusing on action generation, provide the execution layer for agentic systems. They interpret user intentions and translate them into concrete actions that interact with digital or physical environments.
- Task Execution: LAMs excel in decomposing complex goals into actionable subtasks. Their adaptability enhances this capability, allowing them to re-plan and adjust actions in real-time based on feedback.Dynamic Interaction: LAMs integrate with agent frameworks to interact with tools and environments. This interaction allows web navigation, application control, and physical device manipulation.
The Synergy Between LCMs and LAMs
The integration of LCMs and LAMs in an agentic graph system leverages the strengths of both models. LCMs provide the reasoning and planning capabilities necessary for understanding complex contexts, while LAMs execute these plans in real-world settings.
- Knowledge Graph Integration: Knowledge graphs serve as a unifying framework, enabling both models to access structured information for better planning and execution. This enhances the system’s ability to model relationships, store memory, and select appropriate tools.Complementary Strengths: While LCMs address abstract reasoning and multi-modal understanding, LAMs focus on real-world action. This complementary functionality ensures robust performance across cognitive and physical domains, meeting the demands of sophisticated agentic systems.
In conclusion, integrating LCMs and LAMs enables systems that combine abstract reasoning with practical execution. LCMs excel in processing high-level concepts, handling long contexts, and reasoning across languages and modalities. LAMs complement these capabilities by generating and executing actions that fulfill user intentions in real-world scenarios. In agentic graph systems, the synergy between LCMs and LAMs offers a unified approach to solving complex tasks that require planning and execution. By leveraging knowledge graphs, these systems gain enhanced memory, reasoning, and decision-making capabilities, paving the way for more intelligent and autonomous agents. While challenges remain, including scalability, safety, and resource efficiency, ongoing advancements in LCM and LAM architectures promise to address these issues.
Sources
- https://ai.meta.com/research/publications/large-concept-models-language-modeling-in-a-sentence-representation-space/ https://arxiv.org/pdf/2412.10047
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Bridging Reasoning and Action: The Synergy of Large Concept Models (LCMs) and Large Action Models (LAMs) in Agentic Systems appeared first on MarkTechPost.
