

sakana.ai的最新研究论文为一种新型 Transformer 架构提供了通用框架,其背后的想法是适应性。LLM 需要适应各种各样的任务,才能适合特定领域的使用。
然而,传统的 LLM 后期培训有几个缺点
微调需要大量的资源——即使采用混合精度、量化和 PEFT 等现代技术,对 LLM 进行微调的过程仍然非常昂贵,并且需要计算和存储。
过度拟合问题——很多时候,微调模型开始产生重复的输出,并注定导致灾难性的遗忘。
任务干扰——梯度冲突通常导致模型在某一特定任务上表现更好,而另一项任务的性能则下降。
自适应LLM
我们将自适应 LLM 定义为一类能够根据环境的动态变化调节其行为而无需任何外部干扰的模型。
我们如何才能实现这样的智能模型?
1.改进现有的 LLM - 我们都熟悉 LLM 的扩展规律和新兴能力,因此,如果我们继续创建更大的模型,它们显然将更擅长执行各种各样的任务,并在多个领域获得不错的输出,这并不奇怪。
然而,这不是一个可扩展的想法,需要巨大的计算能力。
2.使用混合专家模型— MoE 的理念是将输入动态路由到专门研究特定领域的“专家”模块。作者认为,Transformer² 可以大致归类为 MoE 模型,但两者之间存在显著差异。
去年,麻省理工学院和佐治亚理工学院发表了一篇题为“Self-MoE: Towards Compositional Large Language Models With Self-Specialized Experts”的论文,介绍了一种将单片 LLM 转换为组合系统的方法。其理念是——使用合成数据从头开始创建单个专家模块,而不是使用人工标记的数据(如 MoE 的情况)。然后,这些模块由基础 LLM 共享,基础 LLM 将特定输入路由到特定模块。
自适应LLM的优势
针对不同的任务动态修改模型,而不需要一次又一次地进行微调。
持续学习——随着时间的推移,模型可以积累信息,而不是用静态信息进行训练。
消除灾难性遗忘——可以将新信息添加到模型中,而不会触发任何形式的灾难性遗忘,即模型在学习新任务后会忘记如何完成之前的任务。
作者还强调了自适应LLM模仿“根据手头的任务激活大脑特定区域”的神经科学原理。
虽然 MoE 是创建组合系统的绝佳方式,但为每个单独的任务训练单独的“专家”模块仍然是一种资源密集型方法。为了解决这个问题,本文介绍了一种新颖的微调技术——奇异值微调 (Singular Value Fine-Tuning,SVF)。
奇异值微调(Singular Value Fine-Tuning,SVF)
在深入探讨论文作者所使用的技术之前,让我们先来了解一下理解该方法所需的一些基本概念。
使用奇异值分解(SVD)进行微调
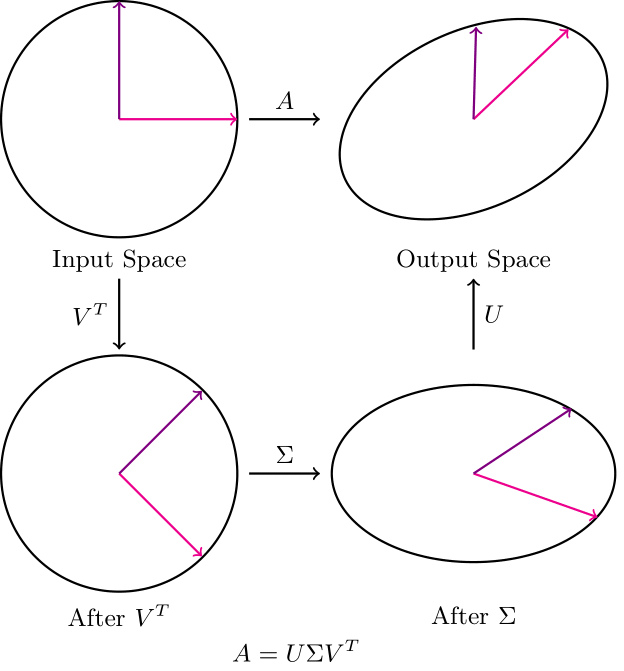
SVD 的几何解释
在 SVD 中,U和V都旋转向量空间。这里我们感兴趣的主题是 Σ 矩阵。
请注意,当 Σ 按其对应的奇异值缩放向量时,基向量与主轴(最大方差的方向)对齐。因此,改变缩放值可以看作是改变我们赋予任何特定主轴的权重量。
由于这些奇异值可以近似表示不同“特征”的“重要性”,我们可以忽略V和U的变化。
因此,我们在微调网络时仅更新权重矩阵的奇异值,这导致需要训练的参数数量呈指数减少。
这种方法的唯一缺点是,当我们仅训练前 k 个奇异值时,可能会有一些信息丢失(取决于不同方向上的方差有多均匀)。
基于 SVD 的微调与 LoRA 的比较
加载模型
from transformers import AutoModelForCausalLM, AutoTokenizername = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(name)tokenizer = AutoTokenizer.from_pretrained(name)
查看使用 LoRA 时可训练参数的数量,
from peft import LoraConfig, peft_modellora_config = LoraConfig(task_type="CAUSAL_LM",
r=8,
lora_alpha=32,
lora_dropout=0.1,
bias="none",)lora_model = peft_model.get_peft_model(model, lora_config)lora_model.print_trainable_parameters()
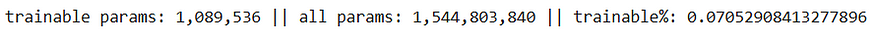
使用 SVD 时查看可训练参数的数量(更新所有 3 个矩阵 - U、V 和 Σ),
# SVD
from svd_training.svd_model import SVDForCausalLMsvd_model = SVDForCausalLM.create_from_model(model, rank_fraction=0.1)
print(f"trainable params: {svd_model.num_parameters(only_trainable=True)} || all params: {svd_model.num_parameters()} || trainable%: {svd_model.num_parameters(only_trainable=True) / svd_model.num_parameters()}")
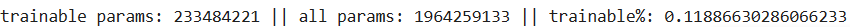
显然,使用基于 SVD 的微调时,可训练参数的数量更多,但为什么呢?答案在于我们不仅更新奇异值,而且更新分解矩阵中的所有值。
以下是应用 SVD 分解后的模型:
Qwen2ForCausalLM( (model): Qwen2Model( (embed_tokens): Embedding(151936, 1536) (layers): ModuleList( (0-27): 28 x Qwen2DecoderLayer( (self_attn): Qwen2SdpaAttention( (q_proj): SVDLinear() (k_proj): SVDLinear() (v_proj): SVDLinear() (o_proj): SVDLinear() (rotary_emb): Qwen2RotaryEmbedding() ) (mlp): Qwen2MLP( (gate_proj): SVDLinear() (up_proj): SVDLinear() (down_proj): SVDLinear() (act_fn): SiLU() ) (input_layernorm): Qwen2RMSNorm() (post_attention_layernorm): Qwen2RMSNorm() ) ) (norm): Qwen2RMSNorm() ) (lm_head): SVDLinear())
让我们做一些计算。有 28 个解码器层,每个解码器层都有 7 个 SVD 线性层。此外,还有一个模型头也已转换为 SVD 线性层。因此,我们有,
28 * 7 + 1 = 197 SVD Linear Layers
保持 Σ 矩阵中除奇异值之外的所有内容不变,每个 SVD 线性层有 1536 个奇异值。因此,奇异值的总数变为,
1536 * 197 = 302,592 singular values
这是在奇异值微调中训练的有效参数数量,相当于LoRA 使用的参数数量的0.00129% 。
去年发表的LoRA-XS论文中也做了类似的工作,不过这项工作引入了强化学习来提升学习效率。
本文最重要的贡献是:Transformer²
该框架分为两个关键步骤,
使用 SVF 根据基础模型权重的 SVD 学习 RL 紧凑和组合专家向量。(下图左侧)
推理过程中结合专家向量的 3 种自适应策略。(下图右侧)
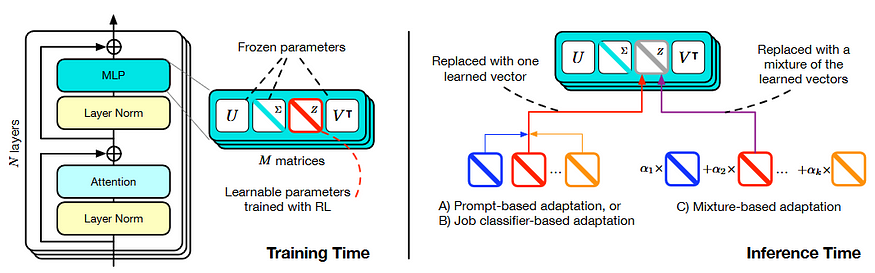
论文中使用方法的概述
我们在这篇文章中查看了大量代码来理解 SVF。现在让我们看看如何使用 RL 训练这些专家向量。我们之前了解到只需要更新 Σ 矩阵。从数学上讲,我们可以说,
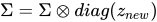
其中 z 是 SVF 专家向量。
然后,论文中的作者使用 REINFORCE 算法,该算法具有单一奖励和 KL 惩罚,用于偏离原始模型行为。这种方法有助于创建更好的“专家”向量,并放宽对数据集的限制,使其更加广泛。
这些专家向量的一大优势是它们提供的高度组合性。这些向量具有高度可解释性,并且可以进行代数运算。
自适应部分是如何工作的?
该框架定义了一种两遍自适应策略,结合了 K 组基础“专家”向量。
第一次推理——给定一个任务,观察模型的测试行为,并创建一个封装该行为的z'向量。
第二次推理——这个适应的向量z'用于生成实际响应。
其理念是,通过观察测试时间行为,模型可以适应包含其可用的专家向量的任意线性组合来生成最终输出。
结论
虽然这篇论文确实讨论了一种构建自适应 LLM 的创新方法,但创建专家 SVF 向量比使用单独的模块(如 LoRA 的情况)更复杂。此外,有大量库支持 PEFT 技术,这让最终用户使用起来更简单。但是,如果您对权重矩阵的外观以及如何操纵它们有深入的了解,那么 SVF 绝对值得研究。
该论文提供了有希望的结果,但请谨慎对待并决定什么最适合您的特定用例。
参考
Transformer² Paper — https://arxiv.org/pdf/2501.06252
2https://sakana.ai/transformer-squared/
Self-MoE Paper: https://arxiv.org/pdf/2406.12034
LoRA-XS paper: https://arxiv.org/pdf/2405.17604
Truncated SVD: https://en.wikipedia.org/wiki/Singular_value_decomposition#Truncated_SVD
SVD Training: https://huggingface.co/blog/fractalego/svd-training



内容中包含的图片若涉及版权问题,请及时与我们联系删除
