
Published on January 21, 2025 4:03 PM GMT
The AI Control Agenda, in its own words:
… we argue that AI labs should ensure that powerful AIs are controlled. That is, labs should make sure that the safety measures they apply to their powerful models prevent unacceptably bad outcomes, even if the AIs are misaligned and intentionally try to subvert those safety measures. We think no fundamental research breakthroughs are required for labs to implement safety measures that meet our standard for AI control for early transformatively useful AIs; we think that meeting our standard would substantially reduce the risks posed by intentional subversion.
There’s more than one definition of “AI control research”, but I’ll emphasize two features, which both match the summary above and (I think) are true of approximately-100% of control research in practice:
- Control research exclusively cares about intentional deception/scheming; it does not aim to solve any other failure mode.Control research exclusively cares about early transformatively-useful AI; it does not aim to generalize to any other AI. In particular, it does not aim to generalize to more powerful AI.
The core point of this post is: intentional scheming in early transformatively-useful AI is a relatively small slice of the AI X-risk probability mass, and therefore control research mostly doesn’t have much impact on X-risk.
The Model & The Problem
I’ll start with an intentionally somewhat-oversimplified model; the points made about this model do generalize to more realistic/complicated models (we’ll get to that later), but are much easier to explain in the simplified model.
In the simplified model, there are two strategically-important stages of AGI: early transformative AGI, and superintelligence.
Superintelligence is extremely dangerous by (strong) default. It will kill us or at least permanently disempower us, with high probability, unless we solve some technical alignment problems before building it. Humanity currently has no idea how to solve those technical problems, and they seem pretty hard.
Early transformative AI is much weaker than superintelligence, probably human-ish level. The big hope on which the control agenda is founded is that early transformative AI can be used to solve the hard technical problems of superintelligence. Insofar as that’s the hope, we don’t necessarily need to solve the hard technical problems of aligning superintelligence by ourselves; we just need to solve the problems of aligning early transformative AI well enough to use it to solve the hard problems.
That brings us to the central pitch of the control agenda. In the words of Buck (one of the main proponents of the control agenda):
IMO the main argument for focusing on scheming risk is that scheming is the main plausible source of catastrophic risk from the first AIs that either pose substantial misalignment risk or that are extremely useful (as I discuss here).
… and this is where I get off the train. The problem is that we mostly don’t die of catastrophic risk from early transformative AI at all. We die of catastrophic risk from stronger AI, e.g. superintelligence (in the oversimplified model). The main problem which needs to be solved for early transformative AI is to use it to actually solve the hard alignment problems of superintelligence. The risk that early transformative AI itself kills us directly, or intentionally tries to kill us indirectly, was never the bulk of the X-risk in the first place.[1]
The Median Doom-Path: Slop, not Scheming
Here, I claim, is the median way we all die, under the simplified model. It’s basically the path we get if we just look at the way major AI labs actually behave today in practice, and extrapolate forward.
First, some lab builds early transformatively-useful AI. They notice that it can do things like dramatically accelerate AI capabilities or alignment R&D. Their alignment team gets busy using the early transformative AI to solve the alignment problems of superintelligence. The early transformative AI spits out some slop, as AI does. Alas, one of the core challenges of slop is that it looks fine at first glance, and one of the core problems of aligning superintelligence is that it’s hard to verify; we can’t build a superintelligence to test it out on without risking death. Put those two together, add a dash of the lab alignment team having no idea what they’re doing because all of their work to date has focused on aligning near-term AI rather than superintelligence, and we have a perfect storm for the lab thinking they’ve solved the superintelligence alignment problem when they have not in fact solved the problem.
So the lab implements the non-solution, turns up the self-improvement dial, and by the time anybody realizes they haven’t actually solved the superintelligence alignment problem (if anybody even realizes at all), it’s already too late.
Some near-variants of this story which account for a lot of the probability mass:
- The lab doesn’t even ask their alignment team (if they even have one) to try to use the early transformative AGI to solve the problems of superintelligence.The lab does ask their alignment team to try to use the early transformative AGI to solve the problems of superintelligence, but lab leadership is mostly looking for the team to safetywash the project, not to actually get involved in building the superintelligence.The lab does ask their alignment team to try to use the early transformative AGI to solve the problems of superintelligence, and in good faith, but big organizations are low-bandwidth and hard to steer so what actually ends up implemented is a dumbed-down version of the team’s solution which doesn’t actually work.Rather than generic slop, the early transformative AGI is fairly sycophantic (for the same reasons as today’s AI), and mostly comes up with clever arguments that the alignment team’s favorite ideas will in fact work. The team falls for this. The ideas don’t work.At some point in the process, one of the alignment researchers has the clever idea of having the AGI red-team its own proposal, or provide evidence/proof that the proposal will work, etc. This produces some arguments which sound good to the researchers, but have subtle and lethal loopholes, because finding arguments which sound good to these particular researchers is a lot easier (i.e. earlier in a search order) than actually solving the problem.At some point in the process, someone with some clever tools probes the early AGI and concludes that it is not scheming. Alas, this does not mean that its outputs will actually solve the superintelligence alignment problem.Some researcher tries a clever method (like e.g. this) to check if the AI is actually solving hard problems in general, vs generating slop. Alas, the researcher fails to measure what they thought they were measuring, because that’s a strong default in empirical research when we don’t already have a deep understanding of the domain.
This thread also runs through some of the more unusual non-scheming failure modes, which are individually not that probable but account for a lot of probability mass in aggregate. After all, it would be surprising if nothing “weird” happened.
Failure To Generalize
One objection one might have at this point: maybe the value of control research, and research like it, is not in getting the early transformative AGI to solve the superintelligence alignment problem, but rather in empirically learning things which will be useful for superintelligence. This is more centrally the pitch of e.g. model organisms work, but it’s still potentially relevant for control, insofar as we expect methods to prevent scheming in early AGI to generalize to prevent scheming in superintelligence.
As far as I can tell, control researchers themselves mostly do not expect the methods they're working on to generalize to superintelligence. Indeed, “this is just intended for near-human AGI, we don’t expect it to generalize to superintelligence” is a very common refrain.
… but let’s steelman a bit; maybe the empirical learnings could be useful even if control researchers themselves do not expect that to be the main value prop. What do we actually expect?
This depends on the details of different work, but in most cases prosaic alignment work (in general, not just limited to control) seems unlikely to generalize even across fairly minor changes in AI, let alone the jump to superintelligence. Here’s one relatively-simple example (from here):
… suppose that the path to AGI is to scale up o1-style inference-time compute, but it requires multiple OOMs of scaling. So it no longer has a relatively-short stream of "internal" thought, it's more like the natural-language record of an entire simulated society.
Then:
There is no hope of a human reviewing the whole thing, or any significant fraction of the whole thing. Even spot checks don't help much, because it's all so context-dependent.Accurate summarization would itself be a big difficult research problem.There's likely some part of the simulated society explicitly thinking about intentional deception, even if the system as a whole is well aligned.... but that's largely irrelevant, because in the context of a big complex system like a whole society, the effects of words are very decoupled from their content. Think of e.g. a charity which produces lots of internal discussion about reducing poverty, but frequently has effects entirely different from reducing poverty. The simulated society as a whole might be superintelligent, but its constituent simulated subagents are still pretty stupid (like humans), so their words decouple from effects (like humans' words).
A Less-Simplified Model
Of course, one might object that the two step “early transformative AGI -> superintelligence” model is importantly oversimplified, that there are more steps in there. How does that update the story?
Well, we still have the same conceptual issue: the generation of AGI before superintelligence needs to solve the alignment problems of superintelligence. The next earlier generation needs to not only make the second-last generation not kill us, it needs to get the second-last generation to actually solve the problems of aligning superintelligence. And so forth on back to the earliest transformative AGI, and to us: we need to not only prevent early transformative AGI from killing us, we need to get early AGI to make this whole chain of increasingly-powerful AIs actually solve all these alignment problems, all the way up to superintelligence.
Recap
Again, the diagram:
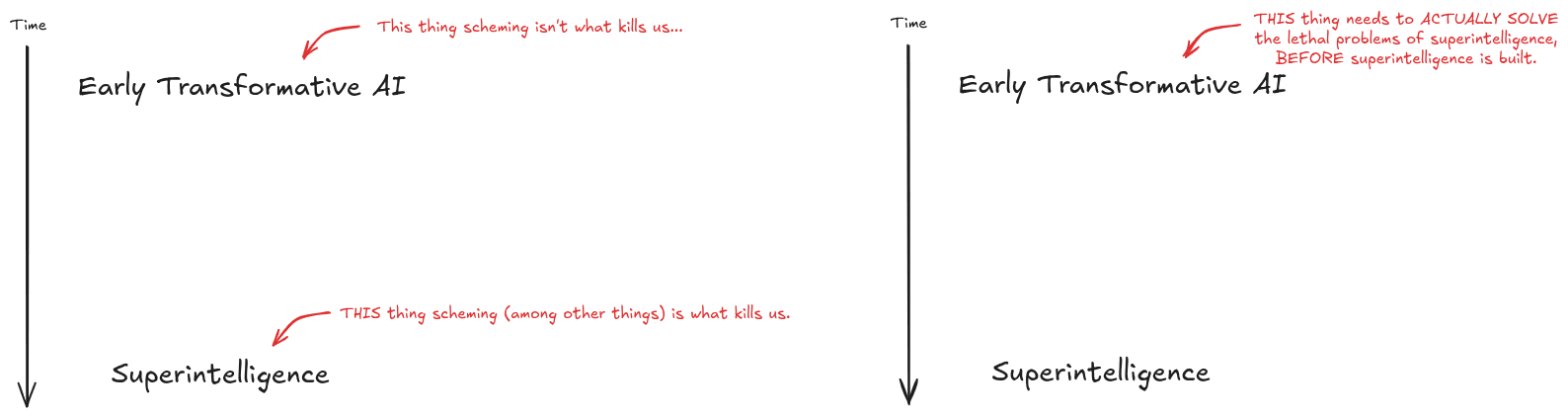
In most worlds, early transformative AGI isn’t what kills us, whether via scheming or otherwise. It’s later, stronger AI which kills us. The big failure mode of early transformative AGI is that it doesn’t actually solve the alignment problems of stronger AI. In particular, if early AGI makes us think we can handle stronger AI, then that’s a central path by which we die. And most of that probability-mass doesn’t come from intentional deception - it comes from slop, from the problem being hard to verify, from humans being bad at science in domains which we don’t already understand deeply, from (relatively predictable if one is actually paying attention to it) failures of techniques to generalize, etc.
- ^
I hear a lot of researchers assign doom probabilities in the 2%-20% range, because they think that’s about how likely it is for early transformative AGI to intentionally scheme successfully. I think that range of probabilities is pretty sensible for successful intentional scheming of early AGI… that’s just not where most of the doom-mass is.
Discuss
