
Published on January 19, 2025 9:09 PM GMT
Recently, OpenAI announced their newest model, o3, achieving massive improvements over state-of-the-art on reasoning and math. The highlight of the announcement was that o3 scored 25% on FrontierMath, a benchmark comprising hard, unseen math problems of which previous models could only solve 2%. The events afterward highlight that the announcements were, unknowingly, not made completely transparent and leave us with lessons for future AI benchmarks, evaluations, and safety.
The Events
These are the important events that happened in chronological order:
- Before Nov 2024, Epoch AI worked on building an ambitious math evaluations benchmark, FrontierMath.They paid independent mathematicians something around $300-$1000 to contribute problems to it, without clearly telling them who funded it and who will have access.On Nov 7, 2024, they released the first version of their paper on arxiv, where they did not mention anything about the funding. It looks like their contract with OpenAI did not allow them to share this information before the o3 announcement.On Dec 20, OpenAI announced o3, which surpassed all expectations and achieved 25% as compared to the previous best, 2%.On the exact same day, Epoch AI updated the paper with a v5. This update tells us that they were completely funded by OpenAI and shared with them exclusive access to most of the hardest problems with solutions:

Further Details
While all of this was felt concerning even during the update in December, recent events have thrown more light on the implicaitions of this.
Other reasons why this is bad
Let's analyse how much of an advantage this access is, and how I believe it was possibly used. I was surprised when I found a number of other things about the benchmark during a presentation by someone who worked on FrontierMath:
Firstly, the benchmark consists of problems on three tiers of difficulty -- (a) 25% olympiad level problems, (b) 50% mid-difficulty problems, and (c) 25% difficult problems that would take an expert mathematician in the domain a few weeks to solve.
What this means, first of all, is that the 25% announcement, which did NOT reveal the distribution of easy/medium/hard problem tiers, was somewhat misleading. It may be possible that most problems o3 solved were from the first tier, which is not as groundbreaking as solving problems from the hardest tier of the benchmark, which it is known most for.
Secondly, OpenAI had complete access to the problems and solutions for most of the problems. This means they could have, in theory, trained their models to solve them. However, they verbally agreed not to do so, and frankly I don't think they would have done that anyway, simply because this is too valuable a dataset to memorize.
How OpenAI could use this, without actually training o3 on it explicitly
Now, nobody really knows what goes on behind o3 (this post has some hypotheses about o1), but if they follow the "thinking" kind of inference-scaling used by models published by other frontier labs that possibly uses advanced chain-of-thought and recursive self-improvement combined with a MCMC-search using a PRM verifier, FrontierMath could be a golden opportunity to validate the PRM on. (note that I don't claim it was used this way -- but I just want to emphasize that a verbal agreement of not training is not enough).
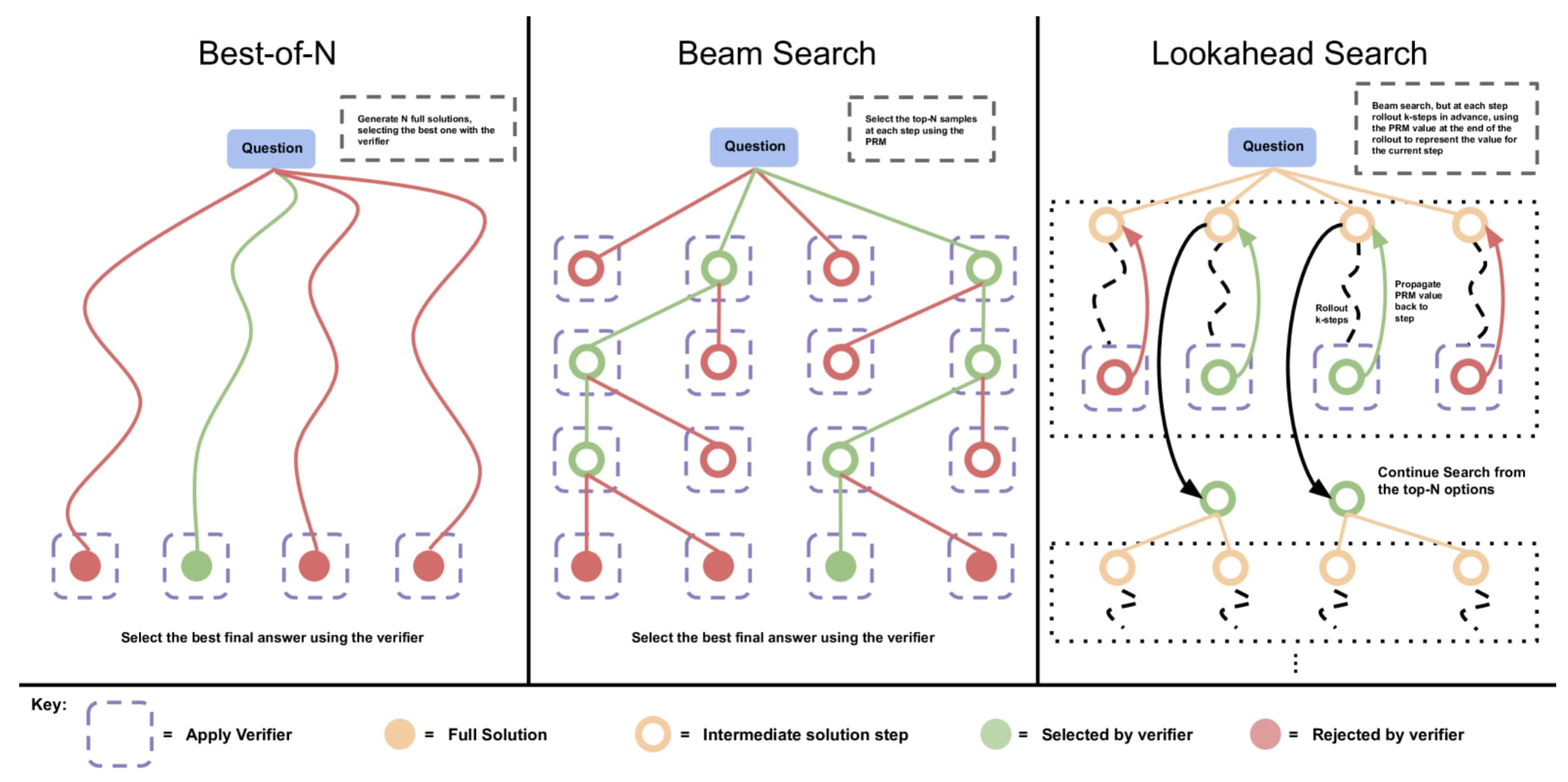
Quite simply, a model that does inference-time compute scaling could greatly benefit from a process-verifier reward model for lookahead search on the output space, and such benchmarks could be really good-quality data to validate universal, generalizable reasoning verifiers on - a really hard task to otherwise get right.
Implications on AI Safety
Epoch AI works on investigating the trajectory of AI for the benefit of society, and several people involved could be concerned with AI safety. Also, a number of the mathematicians who worked on FrontierMath would possibly have not contributed to this if they knew about the funding and exclusive access. It feels concerning that OpenAI could have inadvertently paid people to contribute to capabilities when they might not have wanted to.
Recent open conversations about the situation
Also, in this shortform, Tamay from Epoch AI replied to this (which I really appreciate):

This was in reply in a comment thread in meemi's Shortform:

However, we still haven't discussed everything, including concrete steps and the broader implications this has for AI benchmarks, evaluations, and safety.
Expectations from future work
Specifically, these are the things we need to be careful about in the future:
- Firstly, for all future evaluation benchmarks, we should aim to be completely transparent about:
- (i) who funds them, at least in front of the people actually contributing to it(ii) who will get complete or partial access to the data,(iii) a written, on-paper agreement that explicitly states guidelines on how the data will be used (training, validating, or evaluating the models or PRMs) as opposed to a verbal agreement.
I've been thinking about this last part a lot, especially the ways in which various approaches can contribute indirectly toward capabilities, despite careful considerations made to not do so directly.
Note: A lot of these ideas and hypotheses came out of private conversations with other researchers about the public announcements. I take no credit for this, and I may be wrong in my hypotheses about how exactly the dataset could have possibly been used. However I do see value in more transparent discussions around this, hence this post.
PS: I completely support Epoch AI and their amazing work on studying the trajectory and governance of AI, and I deeply appreciate their coming forward and accepting the concerns and willingness to do the best that can be done to fix things in the future.
Discuss
