


Vision-language models (VLMs) play a crucial role in multimodal tasks like image retrieval, captioning, and medical diagnostics by aligning visual and linguistic data. However, understanding negation in these models remains one of the main challenges. Negation is critical for nuanced applications, such as distinguishing “a room without windows” from “a room with windows.” Despite their advancements, current VLMs fail to interpret negation reliably, severely limiting their effectiveness in high-stakes domains like safety monitoring and healthcare. Addressing this challenge is essential to expand their applicability in real-world scenarios.
The current VLMs, such as CLIP, use shared embedding spaces to align visual and textual representations. Though these models excel in tasks such as cross-modal retrieval and image captioning, their performance falls sharply when dealing with negated statements. This limitation arises due to pretraining data biases because the training datasets contain mainly affirmative examples, leading to affirmation bias, where models treat negated and affirmative statements as equivalents. Existing benchmarks such as CREPE and CC-Neg rely on simplistic templated examples that don’t represent the richness and depth of negation in natural language. VLMs tend to collapse the embeddings of negated and affirmative captions so it is extremely challenging to tease apart fine-grained differences between the concepts. This poses a problem in using VLMs for precise language understanding applications, for instance, querying a medical imaging database with complex inclusion and exclusion criteria.
To address these limitations, researchers from MIT, Google DeepMind, and the University of Oxford proposed the NegBench framework for the evaluation and improvement of negation comprehension over VLMs. The framework assesses two fundamental tasks: Retrieval with Negation (Retrieval-Neg), which examines the model’s capacity to retrieve images according to both affirmative and negated specifications, such as “a beach without people,” and Multiple Choice Questions with Negation (MCQ-Neg), which evaluates nuanced comprehension by necessitating that models select appropriate captions from slight variations. It uses enormous synthetic datasets, like CC12M-NegCap and CC12M-NegMCQ, augmented with millions of captions that contain a wide range of negation scenarios. This will expose VLMs to somewhat challenging negatives and paraphrased captions, improving the training and evaluation of models. Standard datasets, such as COCO and MSR-VTT, were also adapted, including negated captions and paraphrases, to further expand linguistic diversity and test the robustness. By incorporating varied and complex negation examples, NegBench effectively overcomes existing limitations, significantly enhancing model performance and generalization.
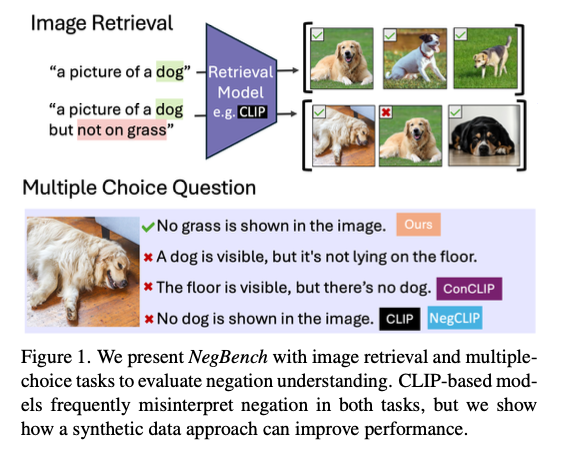
NegBench leverages both real and synthetic datasets to test negation comprehension. Datasets like COCO, VOC2007, and CheXpert were adapted to include negation scenarios, such as “This image includes trees but not buildings.” For MCQs, templates like “This image includes A but not B” were used alongside paraphrased variations for diversity. NegBench is further augmented with the HardNeg-Syn dataset, where images are synthesized to present pairs differing from each other based on the occurrence or absence of certain objects only, hence constituting difficult cases for negation understanding. Model fine-tuning relied on two training objectives. On one hand, contrastive loss facilitated the alignment between image-caption pairs, enhancing performance in retrieval. On the other hand, using multiple-choice loss helped in making fine-grained negation judgments by preferring the right captions in the MCQ context.

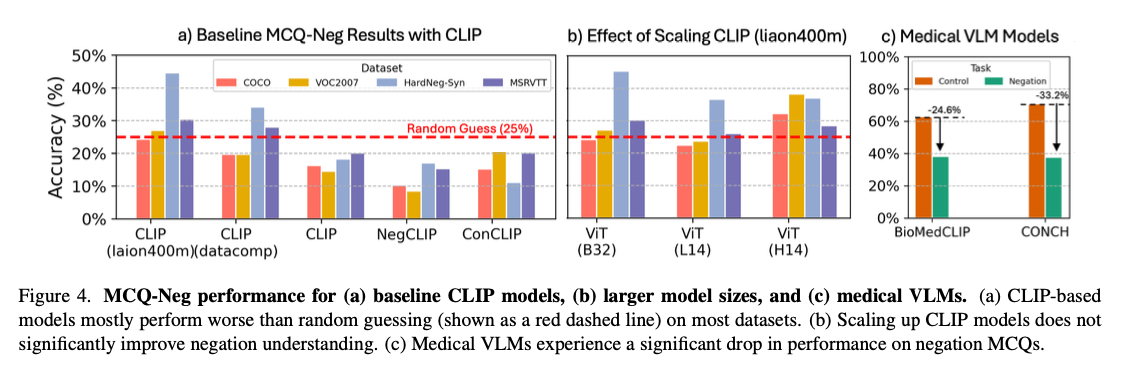
The fine-tuned models showed considerable improvements in retrieval and comprehension tasks using the negation-enriched datasets. For retrieval, the model’s recall increases by 10% for negated queries, where performance is nearly at par with standard retrieval tasks. In the multiple-choice question tasks, accuracy improvements of up to 40% were reported, showing a better ability to differentiate between the subtle affirmative and negated captions. Advancements were uniform over a range of datasets, including COCO and MSR-VTT, and on synthetic datasets like HardNeg-Syn, where models handled negation and complex linguistic developments appropriately. This suggests that representing scenarios with diverse kinds of negation in training and testing is effective in reducing affirmation bias and generalization.
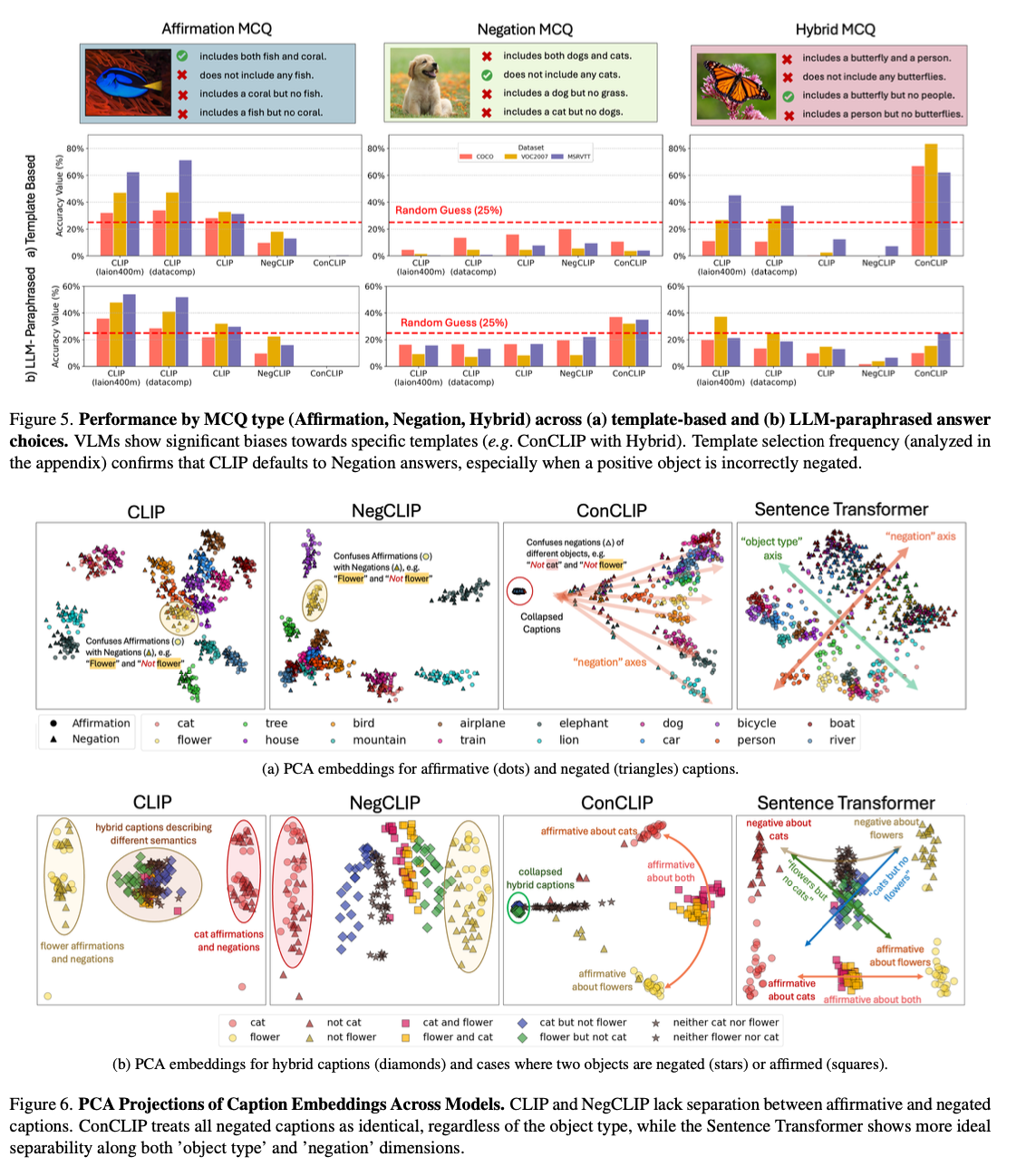
NegBench addresses a critical gap in VLMs by being the first work to address their inability to understand negation. It brings significant improvements in retrieval and comprehension tasks by incorporating diverse negation examples into trAIning and evaluation. Such improvements open up avenues for much more robust AI systems that are capable of nuanced language understanding, with important implications for critical domains like medical diagnostics and semantic content retrieval.
Check out the Paper and Code. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

The post Researchers from MIT, Google DeepMind, and Oxford Unveil Why Vision-Language Models Do Not Understand Negation and Proposes a Groundbreaking Solution appeared first on MarkTechPost.
