
Published on January 19, 2025 9:09 PM GMT
Recently, OpenAI announced their newest model, o3, achieving massive improvements over state-of-the-art on reasoning and math. The highlight of the announcement was the fact that o3 scored 25% on FrontierMath, a benchmark by Epoch AI ridiculously hard, unseen math problems of which previous models could only solve 2%. The events after the announcement, however, highlight that apart from OpenAI having the answer sheet before taking the exam, this was shady and lacked transparency in every possible way and has way broader implications for AI benchmarking, evaluations, and safety.
These are the important events that happened in chronological order:
- Epoch AI worked on building the most ambitious math benchmark ever, FrontierMath.They hired independent mathematicians to work on it who were paid an undisclosed sum for each problem they contributed (at least unknown to me).On Nov 7, 2024, they released the first version of their paper on arxiv, where they did not mention this anywhere as well. It looks like their contract with OpenAI did not allow them to share this information before the o3 announcement.On Dec 20, OpenAI announced their newest model, o3, which broke the internet because it surpassed all expectations and achieved 25% as compared to the previous best, 2%.On the exact same day, Epoch AI updated the paper with a v5, that mentions this. Turns out, they were completely funded by OpenAI in exchange of giving them exclusive access to most of the hardest problems WITH solutions. See the screenshot below from the new version of the paper, in which they so subtly disclose this in the end of a footnote:

Let's analyze how much of an advantage this access is, and how I believe it was possibly used.
I was completely dumbfounded when I found a number of other things about the benchmark during a presentation by a lead mathematician who worked on FrontierMath at a seminar:
Firstly, the benchmark consists of problems on three tiers of difficulty -- (a) 25% olympiad level problems, (b) 50% mid-difficulty problems, and (c) 25% difficult problems that would take a math Ph.D. student in the domain a few weeks to solve.
What this means, first of all, is that the 25% announcement, which did NOT reveal the distribution of easy/medium/hard problem tiers, was entirely misleading. It might as well be possible that o3 solved problems only from the first tier, which is nowhere near as groundbreaking as solving the harder problems from the benchmark.
Secondly, OpenAI had complete access to the problems and solutions to most of the problems. This means they could have actually trained their models to solve it. However, they verbally agreed not to do so, and frankly I don't think they would have done that anyway, simply because this is too valuable a dataset to memorize.
Now, nobody really knows what goes on behind o3, but if they follow the kind of "thinking", inference-scaling of search-space models published by other frontier labs that possibly uses advanced chain-of-thought and introspection combined with a MCMC-rollout on the output distributions with a PRM-style verifier, FrontierMath is a golden opportunity to validate on.
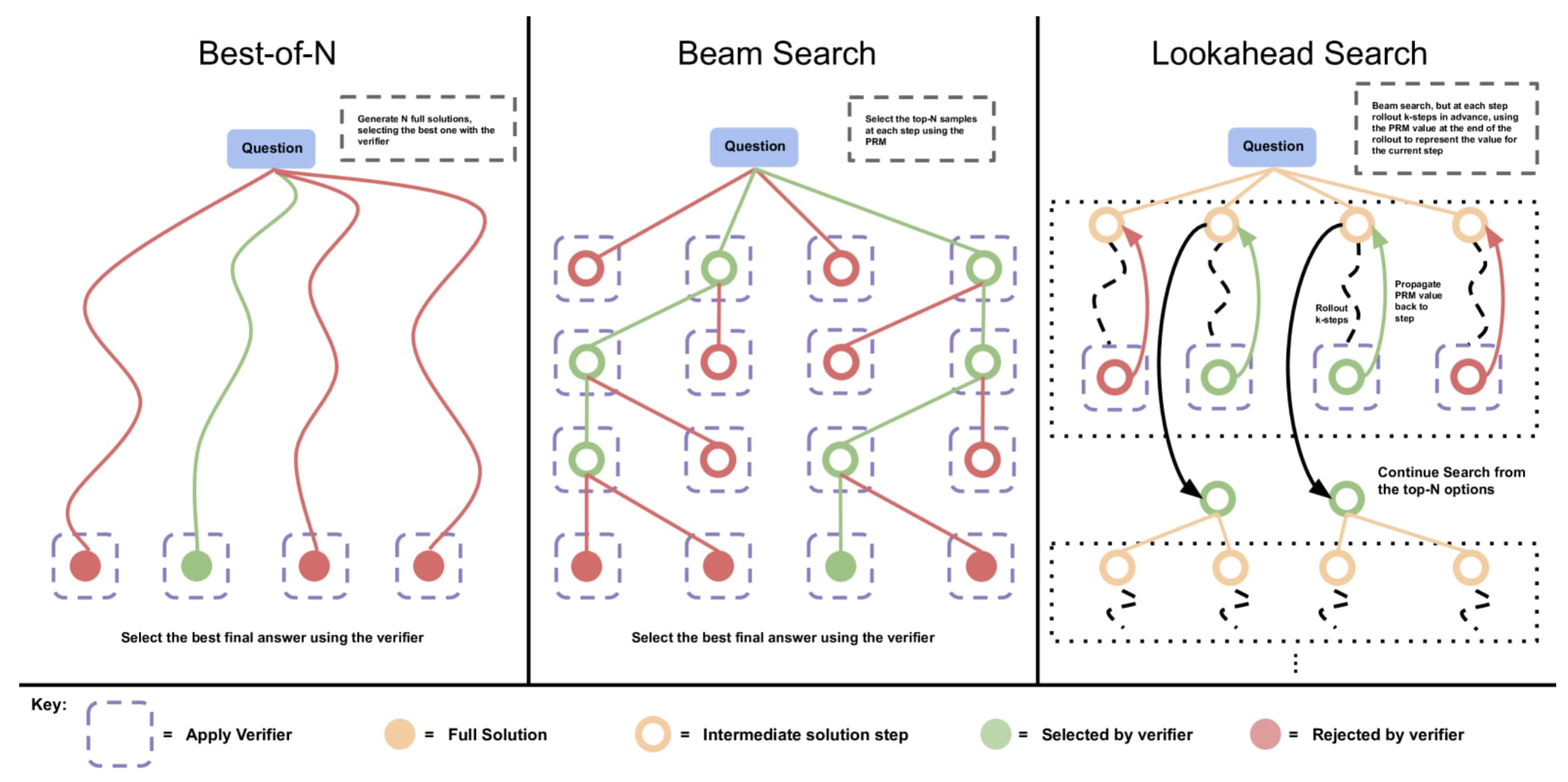
Quite simply, a model that learns inference-time reasoning as shown in this paper would greatly benefit from a good process-verifier reward model against which it can do a lookahead search on the output space, and such datasets are really good-quality data to validate universal, generalizable reasoning verifiers on - a really hard task to otherwise get right.
It is noteworthy that Epoch AI works on "investigating the trajectory of AI for the benefit of society", and a lot of the people funding them and working there are aligned to AI safety (except maybe OpenAI now). A number of the mathematicians who worked on FrontierMath are also aligned to AI safety, and would possibly have not contributed to this if they knew.
It is completely outrageous that OpenAI could pull this off, where they could have, in theory, paid safety-aligned people to contribute to capabilities without them even realizing this, and is cause of a lot of concern and discussion. In hindsight, it is quite obvious why OpenAI would want to conveniently hide this fact (think money at that scale).
Also, in this shortform, Tamay from Epoch AI accepted their mistake, and promised to be more transparent about this:

This was in reply in a comment thread in meemi's Shortform:

However, we still haven't discussed everything, including concrete steps and the broader implications this has for AI benchmarks, evaluations, and safety. Specifically, these are the things we need to be super-seriously careful about in the future:
- Firstly, whatever the next evaluation benchmarks are coming out, can we aim to be completely transparent about:
- (i) who funds them, at least in front of the people actually contributing to it(ii) who will get complete or partial access to the data,(iii) a written, on-paper agreement that explicitly states guidelines on how the data will be used (training, validating, or evaluating the model, or the verifiers it might be trained using). A "verbal agreement" is simply not enough.
Note: A lot of these ideas and hypotheses came out of private investigations, connecting the dots on public announcements and private conversations I had with others in the Berkeley alignment community in Lighthaven as part of the MATS program. I take no credit for connecting all the dots, however I do see lots of value in more transparent discussions around this, and I have been deeply concerned about this, hence this post.
Discuss
