


Understanding long videos, such as 24-hour CCTV footage or full-length films, is a major challenge in video processing. Large Language Models (LLMs) have shown great potential in handling multimodal data, including videos, but they struggle with the massive data and high processing demands of lengthy content. Most existing methods for managing long videos lose critical details, as simplifying the visual content often removes subtle yet essential information. This limits the ability to effectively interpret and analyze complex or dynamic video data.
Techniques currently used to understand long videos include extracting key frames or converting video frames into text. These techniques simplify processing but result in a massive loss of information since subtle details and visual nuances are omitted. Advanced video LLMs, such as Video-LLaMA and Video-LLaVA, attempt to improve comprehension using multimodal representations and specialized modules. However, these models require extensive computational resources, are task-specific, and struggle with long or unfamiliar videos. Multimodal RAG systems, like iRAG and LlamaIndex, enhance data retrieval and processing but lose valuable information when transforming video data into text. These limitations prevent current methods from fully capturing and utilizing the depth and complexity of video content.
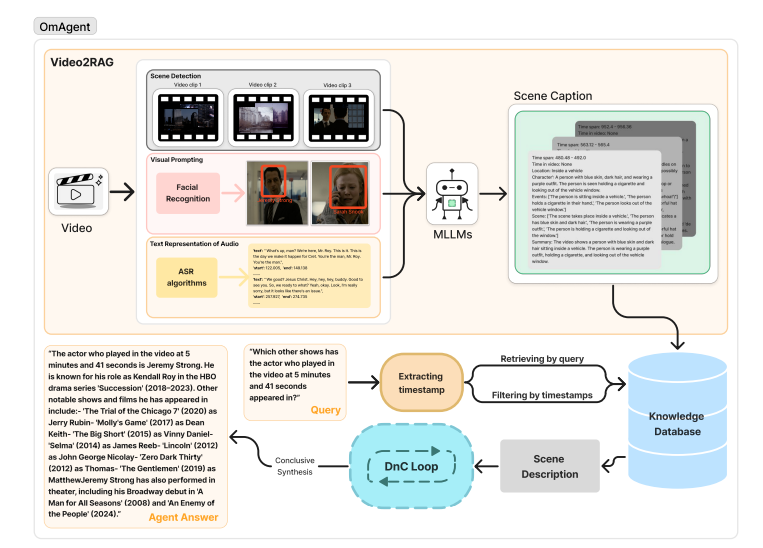
To address the challenges of video understanding, researchers from Om AI Research and Binjiang Institute of Zhejiang University introduced OmAgent, a two-step approach: Video2RAG for preprocessing and DnC Loop for task execution. In Video2RAG, raw video data undergoes scene detection, visual prompting, and audio transcription to create summarized scene captions. These captions are vectorized and stored in a knowledge database enriched with further specifics about time, location, and event details. In this way, the process avoids large context inputs to language models and, hence, problems such as token overload and inference complexity. For task execution, queries are encoded, and these video segments are retrieved for further analysis. This ensures efficient video understanding by balancing detailed data representation and computational feasibility.
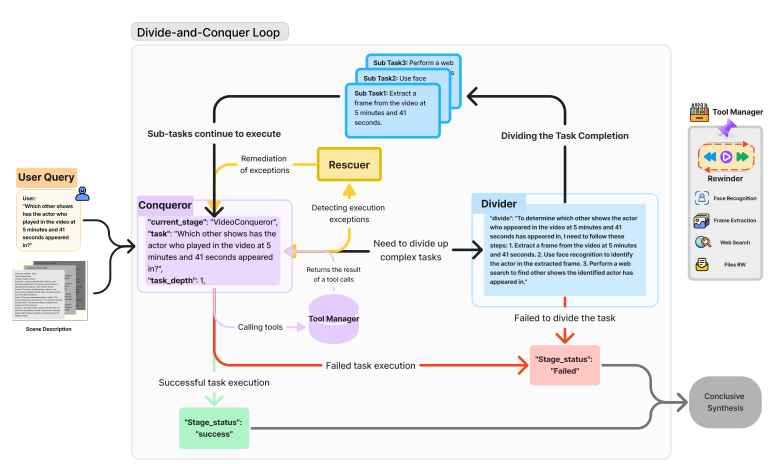
The DNC Loop employs a divide-and-conquer strategy, recursively decomposing tasks into manageable subtasks. The Conqueror module evaluates tasks, directing them for division, tool invocation, or direct resolution. The Divider module breaks up complex tasks, and the Rescuer deals with execution errors. The recursive task tree structure helps in the effective management and resolution of tasks. The integration of structured preprocessing by Video2RAG and the robust framework of DnC Loop makes OmAgent deliver a comprehensive video understanding system that can handle intricate queries and produce accurate results.
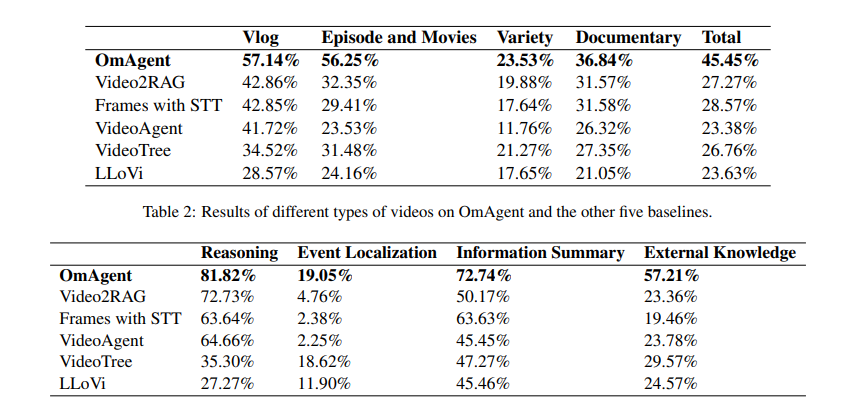
Researchers conducted experiments to validate OmAgent’s ability to solve complex problems and comprehend long-form videos. They used two benchmarks, MBPP (976 Python tasks) and FreshQA (dynamic real-world Q&A), to test general problem-solving, focusing on planning, task execution, and tool usage. They designed a benchmark with over 2000 Q&A pairs for video understanding based on diverse long videos, evaluating reasoning, event localization, information summarization, and external knowledge. OmAgent consistently outperformed baselines across all metrics. In MBPP and FreshQA, OmAgent achieved 88.3% and 79.7%, respectively, surpassing GPT-4 and XAgent. OmAgent scored 45.45% overall for video tasks compared to Video2RAG (27.27%), Frames with STT (28.57%), and other baselines. It excelled in reasoning (81.82%) and information summary (72.74%) but struggled with event localization (19.05%). OmAgent’s Divide-and-Conquer (DnC) Loop and rewinder capabilities significantly improved performance in tasks requiring detailed analysis, but precision in event localization remained challenging.
In summary, the proposed OmAgent integrates multimodal RAG with a generalist AI framework, enabling advanced video comprehension with near-infinite understanding capacity, a secondary recall mechanism, and autonomous tool invocation. It achieved strong performance on multiple benchmarks. While challenges like event positioning, character alignment, and audio-visual asynchrony remain, this method can serve as a baseline for future research to improve character disambiguation, audio-visual synchronization, and comprehension of nonverbal audio cues, advancing long-form video understanding.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Meet OmAgent: A New Python Library for Building Multimodal Language Agents appeared first on MarkTechPost.
