


The development of VLMs in the biomedical domain faces challenges due to the lack of large-scale, annotated, and publicly accessible multimodal datasets across diverse fields. While datasets have been constructed from biomedical literature, such as PubMed, they often focus narrowly on domains like radiology and pathology, neglecting complementary areas such as molecular biology and pharmacogenomics that are critical for holistic clinical understanding. Privacy concerns, the complexity of expert-level annotation, and logistical constraints further impede the creation of comprehensive datasets. Previous approaches, like ROCO, MEDICAT, and PMC-15M, have relied on domain-specific filtering and supervised models to extract millions of image-caption pairs. However, these strategies often fail to capture the broader diversity of biomedical knowledge required for advancing generalist biomedical VLMs.
In addition to dataset limitations, the training and evaluation of biomedical VLMs present unique challenges. Contrastive learning approaches, such as PMC-CLIP and BiomedCLIP, have shown promise by leveraging literature-based datasets and vision transformer models for image-text alignment. However, their performance is constrained by smaller datasets and limited computational resources compared to general VLMs. Furthermore, current evaluation protocols, focused mainly on radiology and pathology tasks, lack standardization and broader applicability. The reliance on additional learnable parameters and narrow datasets undermines the reliability of these evaluations, highlighting the need for scalable datasets and robust evaluation frameworks that can address the diverse demands of biomedical vision-language applications.
Researchers from Stanford University introduced BIOMEDICA, an open-source framework designed to extract, annotate, and organize the entire PubMed Central Open Access subset into a user-friendly dataset. This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. They also released BMCA-CLIP, a suite of CLIP-style models pre-trained on BIOMEDICA via streaming, eliminating the need for local storage of 27 TB of data. These models achieve state-of-the-art performance across 40 tasks, including radiology, dermatology, and molecular biology, with a 6.56% average improvement in zero-shot classification and reduced computational requirements.
The BIOMEDICA data curation process involves dataset extraction, concept labeling, and serialization. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API. Images are clustered using DINOv2 embeddings and labeled through a hierarchical taxonomy refined by experts. Labels are assigned via majority voting and propagated across clusters. The dataset, containing over 24 million image-caption pairs and extensive metadata, is serialized into WebDataset format for efficient streaming. With 12 global and 170 local image concepts, the taxonomy covers categories like clinical imaging, microscopy, and data visualizations, emphasizing scalability and accessibility.
The evaluation of continual pretraining on the BIOMEDICA dataset utilized 39 established biomedical classification tasks and a new retrieval dataset from Flickr, spanning 40 datasets. The classification benchmark includes pathology, radiology, biology, surgery, dermatology, and ophthalmology tasks. Metrics like average accuracy for classification and retrieval recall (at 1, 10, and 100) were employed. Concept filtering, which excludes overrepresented topics, performed better than concept balancing or full dataset pretraining. Models trained on BIOMEDICA achieved state-of-the-art results, significantly outperforming previous methods, with improved performance across classification, retrieval, and microscopy tasks using less data and computation.
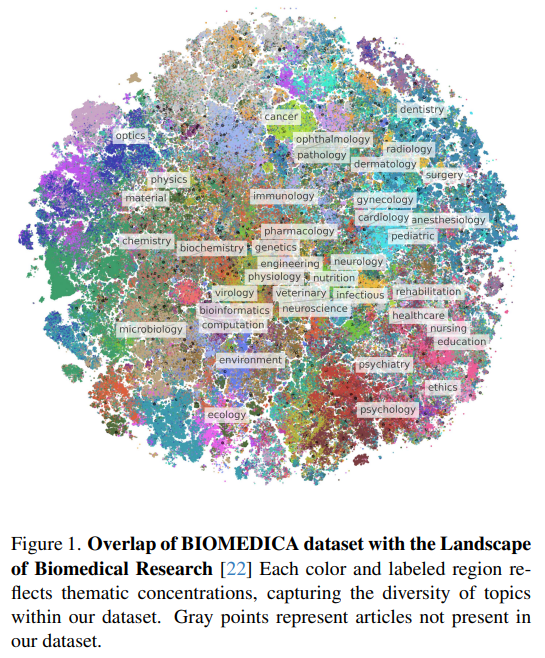
In conclusion, BIOMEDICA is a comprehensive framework that transforms the PubMed Central Open Access (PMC-OA) subset into the largest deep-learning-ready dataset, featuring 24 million image-caption pairs enriched with 27 metadata fields. Designed to address the lack of diverse, annotated biomedical datasets, BIOMEDICA provides a scalable, open-source solution to extract and annotate multimodal data from over 6 million articles. Through continual pretraining of CLIP-style models using BIOMEDICA, the framework achieves state-of-the-art zero-shot classification and image-text retrieval across 40 biomedical tasks, requiring 10x less computing and 2.5x less data. All resources, including models, datasets, and code, are publicly available.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Stanford Researchers Introduce BIOMEDICA: A Scalable AI Framework for Advancing Biomedical Vision-Language Models with Large-Scale Multimodal Datasets appeared first on MarkTechPost.
