
新型注意力机制TPA,姚期智院士团队打造。

TPA对每个token做动态的张量分解,不存储完整的静态KV,而是保留分解的版本,内存占用节省90%(或者更多),而不会牺牲性能。
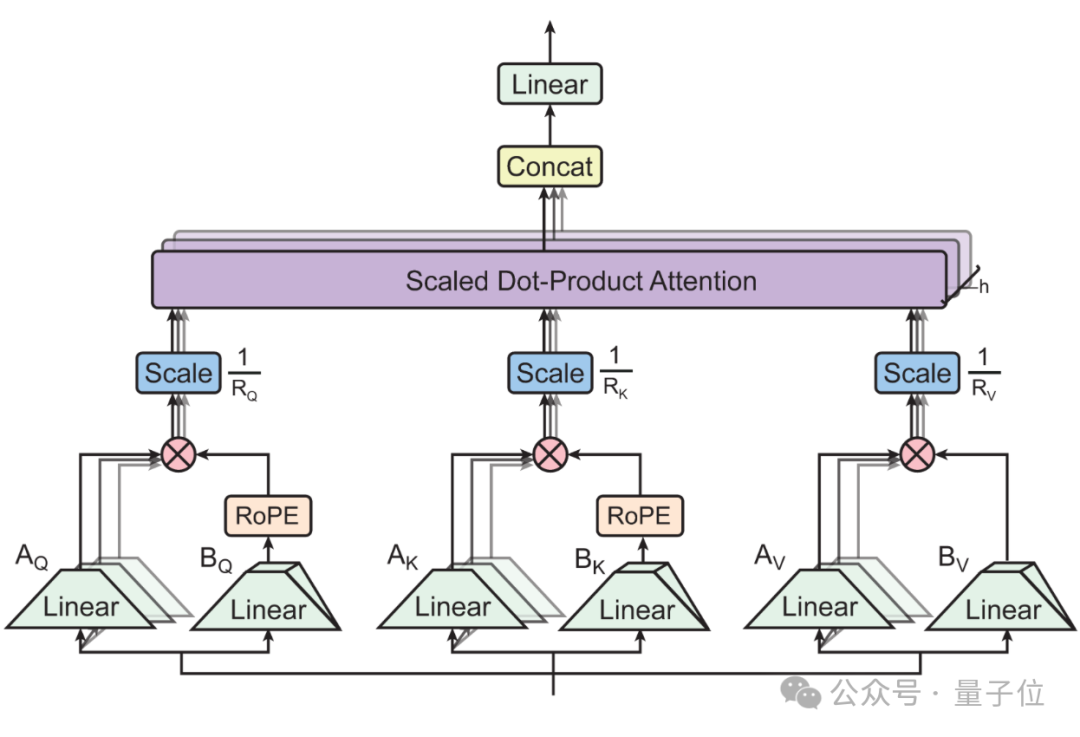
论文中还证明了流行的MHA、MQA、GQA都是TPA的特殊情况,用一个框架统一了现代注意力设计。

用此方法训练的新模型T6,代码已在GitHub开源。

论文发布后,有创业者表示,终于不用付那么多钱给云厂商了。
也有研究者认为,论文中的实验看起来很有希望,不过实验中的模型规模有点小,希望看到更多结果。

动态张量分解,无缝集成RoPE
尽管现有的注意力机制在众多任务中取得了不错的效果,但它还是有计算和内存开销大的缺陷。
DeepSeek-v2中提出的MLA压缩了KV缓存,但与RoPE位置编码不兼容,每个注意力头需要额外的位置编码参数。
为了克服这些方法的局限性,团队提出张量积注意力(TPA,Tensor Product Attention)。
新方法在注意力计算过程中对QKV做分解。
与LoRA系列低秩分解方法相比,TPA将QKV分别构造为与上下文相关的分解张量,实现动态适应。

通过只缓存分解后的秩,设置合适的参数可使内存占用降低90%或以上。

对于流行的RoPE位置编码,TPA可以与之无缝集成,实现以较低的成本旋转分解KV,无需进行复杂的调整。

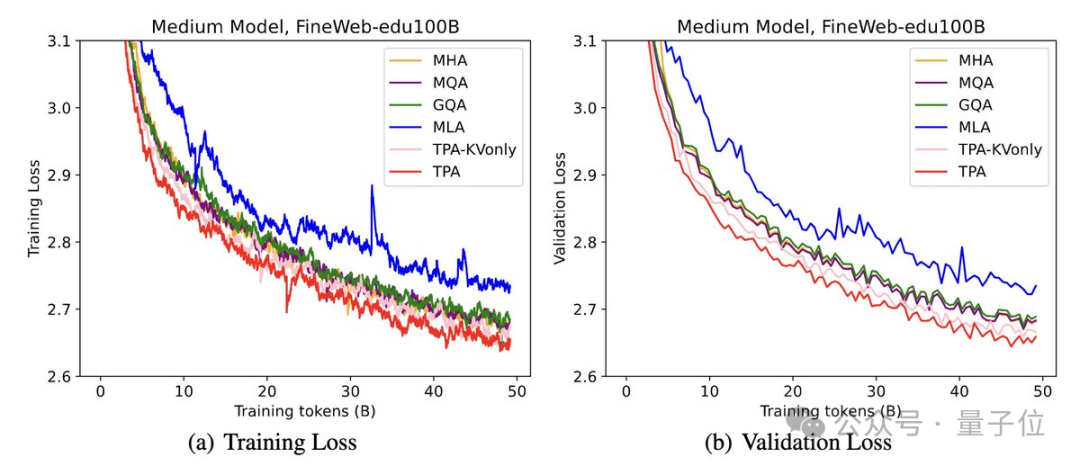
在实验中,使用FineWeb-Edu 100B数据集训练模型,TPA与其他注意力设计相比始终保持较低的困惑度。
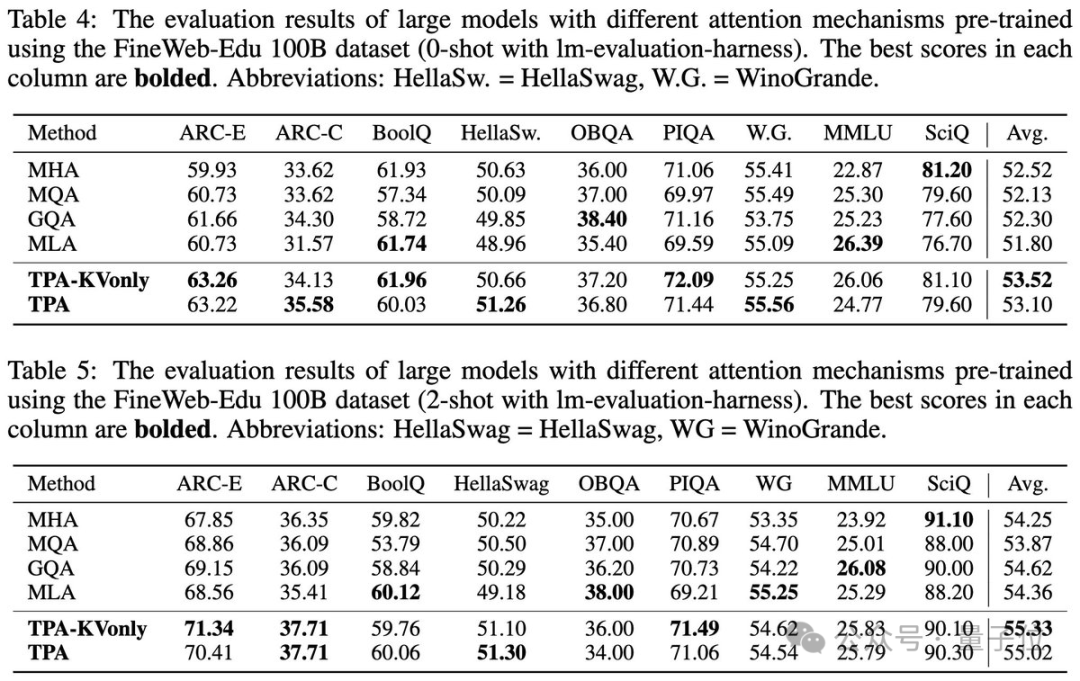
在ARC、BoolQ、HellaSwag和MMLU等基准测试中测试了零样本和少样本性能。TPA和TPA-KVonly在大多数任务中都优于或匹配所有基线。
论文由清华&上海期智研究员团队、UCLA顾全全团队合作,共同一作为清华博士生张伊凡与姚班校友、现UCLA博士生刘益枫。
此外还有来自心动网络Taptap的Qin Zhen。

论文地址:
https://arxiv.org/abs/2501.06425
开源代码:
https://github.com/tensorgi/T6
参考链接:
[1]https://x.com/yifan_zhang_/status/1879049477681741896
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里?关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

内容中包含的图片若涉及版权问题,请及时与我们联系删除
