We’ve been following Ben Hylak’s work on the Apple VisionOS for a bit, and invited him to speak at the World’s Fair. He has since launched Dawn Analytics, and continued to publish unfiltered thoughts about o1 — initially as a loud skeptic, and slowly becoming a daily user. We love mind-changers in both its meanings, and think this same conversation is happening all over the world as people struggle to move from the chat paradigm to the brave new world of reasoning and $x00/month prosumer AI products like Devin (spoke at WF, now GA). Here are our thoughts.
PSA: Due to overwhelming demand (>15x applications:slots), we are closing CFPs for AI Engineer Summit tomorrow. Last call! Thanks, we’ll be reaching out to all shortly!
o1 isn’t a chat model (and that’s the point)
How did I go from hating o1 to using it everyday for my most important questions?
When o1 pro was announced, I subscribed without flinching. To justify the $200/mo price tag, it just has to provide 1-2 Engineer hours a month (the less we have to hire at dawn, the better!)
But at the end of a day filled with earnest attempts to get the model to work — I concluded that it was garbage.
Every time I asked a question, I had to wait 5 minutes only to be greeted with a massive wall of self-contradicting gobbledygook, complete with unrequested architecture diagrams + pro/con lists.
I tweeted as much and a lot of people agreed — but more interestingly to me, some disagreed vehemently. In fact, they were mind-blown by just how good it was.
Sure, people often get very hypey about OpenAI after launches (it’s the second best strategy to go viral, right after being negative.)
But this felt different — these takes were coming from folks deep in the trenches.
The more I started talking to people who disagreed with me, the more I realized I was getting it completely wrong:
I was using o1 like a chat model — but o1 is not a chat model.
How to use o1 in anger
If o1 is not a chat model — what is it?
I think of it like a “report generator.” If you give it enough context, and tell it what you want outputted, it’ll often nail the solution in one-shot.
swyx’s Note: OpenAI does publish advice on prompting o1, but we find it incomplete, and in a sense you can view this article as a “Missing Manual” to lived experience using o1 and o1 pro in practice.
1. Don’t Write Prompts; Write Briefs
Give a ton of context. Whatever you think I mean by a “ton” — 10x that.
When you use a chat model like Claude 3.5 Sonnet or 4o, you often start with a simple question and some context. If the model needs more context, it’ll often ask you for it (or it’ll be obvious from the output).
You iterate back and forth with the model, correcting it + expanding on requirements, until the desired output is achieved. It’s almost like pottery. The chat models essentially pull context from you via this back and forth. Overtime, our questions get quicker + lazier — as lazy as they can be while still getting a good output.
o1 will just take lazy questions at face value and doesn’t try to pull the context from you. Instead, you need to push as much context as you can into o1.
Even if you’re just asking a simple engineering question:
Explain everything that you’ve tried that didn’t work
Add a full dump of all your database schemas
Explain what your company does, how big it is (and define company-specific lingo)
In short, treat o1 like a new hire. Beware that o1’s mistakes include reasoning about how much it should reason.Sometimes the variance fails to accurately map to task difficulty. e.g. if the task is really simple, it will often spiral into reasoning rabbit holes for no reason. Note: the o1 API allows you to specify low/medium/high reasoning_effort, but that is not exposed to ChatGPT users.
Tips to make it easier giving o1 context
I suggest using the Voice Memos app on your mac/phone. I just describe the entire problem space for 1-2 minutes, and then paste that transcript in.
I actually have a note where I keep long segments of context to re-use.
The AI assistants that are popping up inside of products can often make this extraction easier. For example, if you use Supabase, try asking the Supabase Assistant to dump/describe all of the relevant tables/RPC’s/etc.
2. Focus on Goals: describe exactly WHAT you want upfront, and less HOW you want it
Once you’ve stuffed the model with as much context as possible — focus on explaining what you want the output to be.
With most models, we’ve been trained to tell the model how we want it to answer us. e.g.“You are an expert software engineer. Think slowly + carefully”
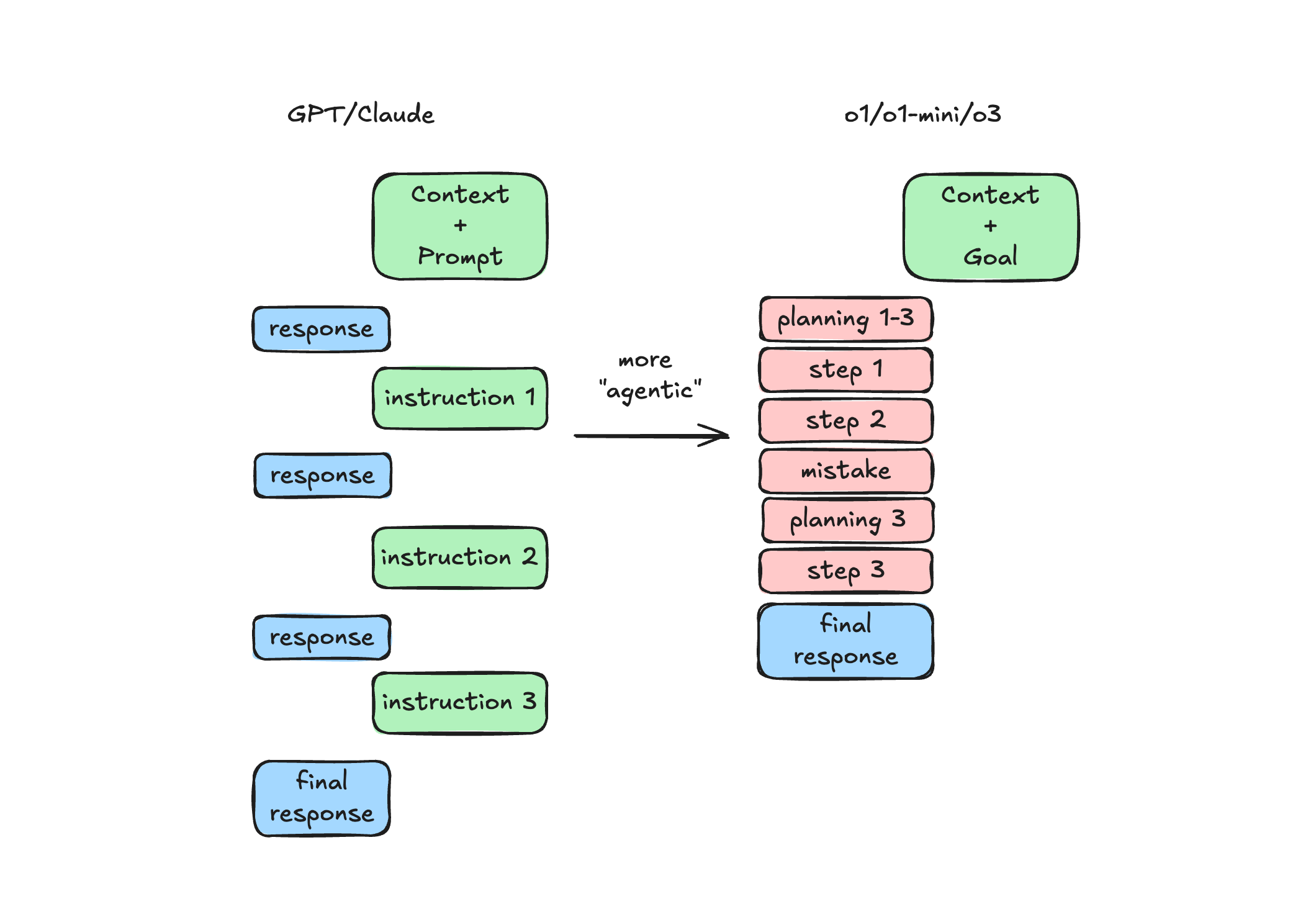
This is the opposite of how I’ve found success with o1. I don’t instruct it on the how — only the what. Then let o1 take over and plan and resolve its own steps. This is what the autonomous reasoning is for, and can actually be much faster than if you were to manually review and chat as the “human in the loop”.
swyx’s poor illustration attempt
swyx’s pro tip: developing really good criteria for what you consider to be “good” vs “bad” helps you give the model a way to evaluate its own output and self-improve/fix its own mistakes. Essentially you’re moving the LLM-as-Judge into the prompt and letting o1 run it whenever needed.
As a bonus, this eventually gives you LLM-as-Judge evaluators you can use for Reinforcement Finetuning when it is GA.
This requires you to really know exactly what you want (and you should really ask for one specific output per prompt — it can only reason at the beginning!)
Sounds easier than it is! Did I want o1 to implement a specific architecture in production, create a minimal test app, or just explore options and list pros/cons? These are all entirely different asks.
o1 often defaults to explaining concepts with a report-style syntax — completely with numbered headings and subheadings. If you want to skip the explanations and output complete files — you just need to explicitly say that.
Since learning how to use o1, I’ve been pretty mind-blown by its ability to generate the right answer the first time. It’s really pretty much better in every single way (besides cost/latency). Here are a few little moments where this has particularly stood out:
3. Know what o1 does and does not do well
What o1 does well:
Perfectly one-shotting entire/multiple files: This, by far, is o1’s most impressive ability. I copy/paste a ton of code in, a ton of context about what I’m building, and it’ll completely one-shot the entire file (or files!), usually free of errors, following existing patterns I have in my codebase.
Hallucinates Less: In general, it just seems to confuse things less. For example, o1 really nails bespoke query languages (like ClickHouse and New Relic), where Claude often confuses the syntax for Postgres.
Medical Diagnoses: My girlfriend is a dermatologist — so whenever any friend or anyone in my extended family has any sort of skin issue, they’re sure to send her a picture! Just for fun, I started asking o1 in parallel. It’s usually shockingly close to the right answer — maybe 3/5 times. More useful for medical professionals — it almost always provides an extremely accurate differential diagnosis.
Explaining Concepts: I’ve found that it is very good at explaining very difficult engineering concepts, with examples. It’s almost like it generates an entire article.
When I’m working on difficult architectural decisions, I will often have o1 generate multiple plans, with pros/cons for each, and even compare those plans. I’ll copy/paste the responses as PDF’s, and compare them — almost like I’m considering proposals.
Bonus: Evals. I have historically been very skeptical of using LLM as a Judge for Evals, because fundamentally the judge model often suffers from the same failure modes as what generated the outputs in the first place. o1, however, shows a ton of promise — it is often able to determine if a generation is correct or not with very little context.
What o1 doesn’t do well (yet):
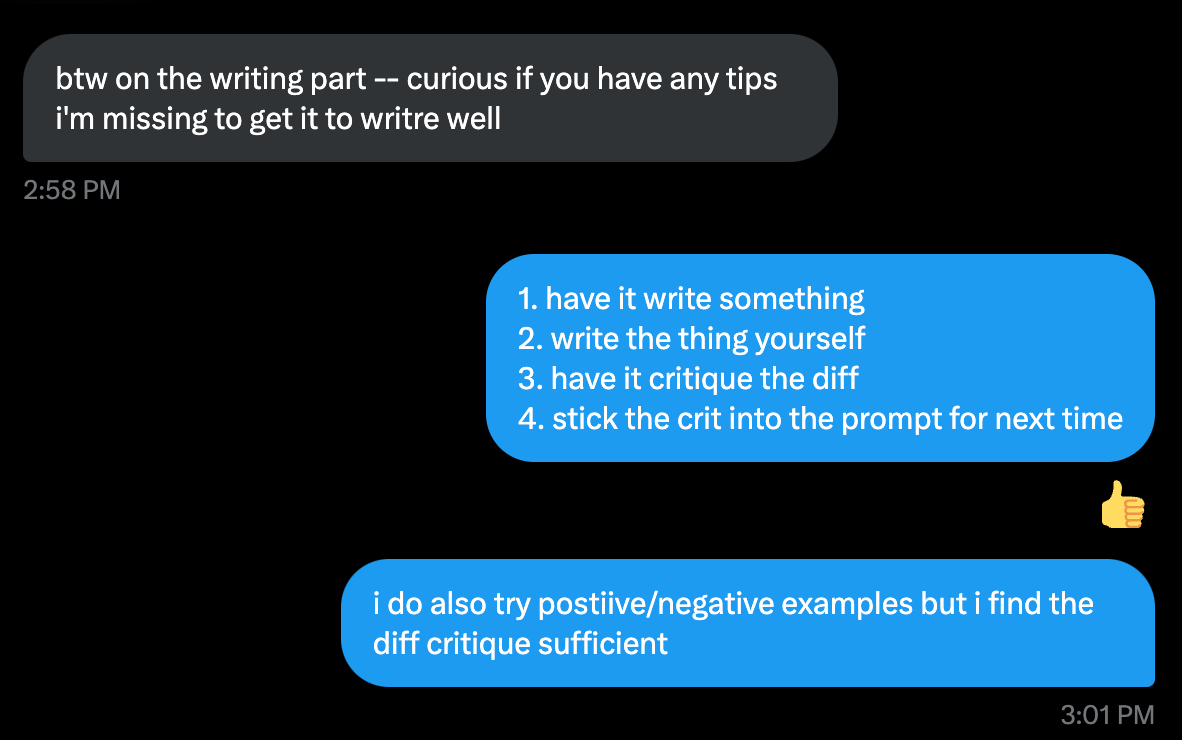
Writing in specific voices/styles: No, I did not use o1 to write this post :)
I’ve found that it’s pretty bad at writing anything, especially in specific voices or styles. It has a very academic/corporate report style that it wants to follow. I think that there are just so many reasoning tokens biasing the tone in that direction, it’s very hard to break free from that.
Here’s an example of me trying to get it to write this post — this is after much back and forth — it just wants to produce a bland school report.
Building an Entire App: o1 is mindblowingly good at one-shotting entire files. that being said, despite some of the more… optimistic… demos you might see on twitter — o1 is not going to build an entire SaaS for you, at least not with a lot of iteration. But it can pretty much one-shot entire features, especially if they’re front-end or simple backend features.
Aside: Designing Interfaces for Report Generators
Latency fundamentally changes our experience of a product.
Consider the differences between mail, email and texting — it’s mainly just latency. A voice message vs. a phone call — latency. A video vs a Zoom — latency. And so on.
I call o1 a “report generator” because it’s clearly not a chat model — it feels a lot more like email.
This hasn't yet manifested in o1's product design. I would love to see the design more honestly reflected in the interface.
Here are some specific AIUX tips for anyone building o1-based products:
Make it easier to see the hierarchy of the response (think a mini table of contents)
Similarly, make the hierarchy more easily navigable. Since every request is usually larger than the height of the window, I would take a Perplexity like approach where each question/answer page gets a section vs. freeform scroll. Within an answer, things like sticky headers, collapsible headers, etc. could really help)
Make it easier to manage and see the context you’re providing to the model. (Ironically Claude’s UI does a much better job of this — when you paste in a long piece of text, it renders as a little attachment). I also find that ChatGPT Projects don’t work nearly as well as Claude’s, so I’m copying and pasting stuff a lot.
Side note:
Separately ChatGPT is REALLY buggy when it comes to o1. The descriptions of reasoning are comical, it often completely fails to generate, and most often doesn’t work on the mobile app.
A beautiful day in… Kenya??
What’s next?
I’m really excited to see how these models actually get used.
I think o1 will make certain products possible for the first time — for example, products that can benefit from high-latency, long running background intelligence.
What sort of tasks is a user willing to wait 5 minutes for? An hour? A day? 3-5 business days?
A bunch, I think, if it’s designed correctly.
As models get more expensive, experimentation gets harder to justify. It’s easier than ever to waste $1000s of dollars in just minutes.
o1-preview and o1-mini support streaming, but they don’t support structured generation or system prompts. o1 supports structured generation and system prompts, but not streaming yet.
Given how long a response takes, streaming feels like a requirement.
It will be very cool to see what developers actually do with the model as they get to work in 2025.
swyx: Thanks Ben! Last plug - if you’re building agents with o1, or managing a team of AI engineers, you should definitely apply to AIES NYC.