


LLMs, such as GPT-3.5 and GPT-4, have shown exceptional capabilities in language generation, comprehension, and translation tasks. Despite these advancements, their performance is inherently constrained by the availability of training data, much of which has already been utilized. Recent research explores self-improvement by generating synthetic data by LLMs to address this limitation. While using advanced frontier models like GPT-4 to create supervisory data is an option, it is costly, legally restricted, and limited by the inherent quality of these models. Alternatively, LLMs can iteratively generate and fine-tune synthetic data, but this process often experiences diminishing returns as diversity decreases, restricting improvements after a few rounds of fine-tuning.
Finetuning methods generally fall into three categories: human-in-the-loop, distillation, and self-improvement. Human-in-the-loop techniques, like RLHF and DPO, leverage human feedback to refine responses, while distillation uses larger LLMs to train smaller models. Self-improvement methods, including rationale generation and self-play, enable LLMs to iteratively fine-tune by generating their data. However, these approaches often plateau in performance after limited iterations. To overcome this limitation, recent work introduces multiagent interactions to sustain performance improvements across multiple rounds of fine-tuning, achieving more consistent gains than traditional self-improvement methods.
Researchers from MIT, Harvard, Stanford, and Google DeepMind have introduced a multiagent approach to address the performance plateau observed in single-agent fine-tuning of LLMs. Starting with the same base model, multiple LLMs are independently fine-tuned on distinct data generated through multiagent interactions, fostering specialization and diversity. Models are divided into generation agents, which produce responses, and critic agents, which evaluate and refine them. This iterative feedback loop ensures sustained performance improvements over more fine-tuning rounds. The method, tested on open-source and proprietary LLMs, demonstrated significant gains in reasoning tasks and effective zero-shot generalization to new datasets.
The multiagent finetuning approach trains a society of language models to solve tasks collaboratively. It involves two key steps: generating a finetuning dataset through multiagent debate and using this dataset to specialize models. Multiple agents generate responses iteratively during the discussion, refining outputs based on others’ summaries, with a majority vote determining the final result. Models are then finetuned as either generation or critic agents. Generation models create diverse responses, while critic models assess and refine outputs. Iterative finetuning enhances accuracy and adaptability, with inference using debates among finetuned agents to produce refined, majority-voted outputs.
The study evaluates the proposed multiagent fine-tuning (FT) method on three language reasoning tasks: Arithmetic, Grade School Math (GSM), and MATH. Performance is assessed by accuracy and standard error, using 500 examples for training and evaluation. Baselines include single-agent models, majority voting, multiagent debates, and iterative fine-tuning methods like STaR. The proposed approach outperforms baselines across datasets, with significant gains in complex tasks like GSM and MATH. Multiple fine-tuning iterations consistently improve accuracy and maintain diversity, addressing overfitting issues in single-agent fine-tuning.
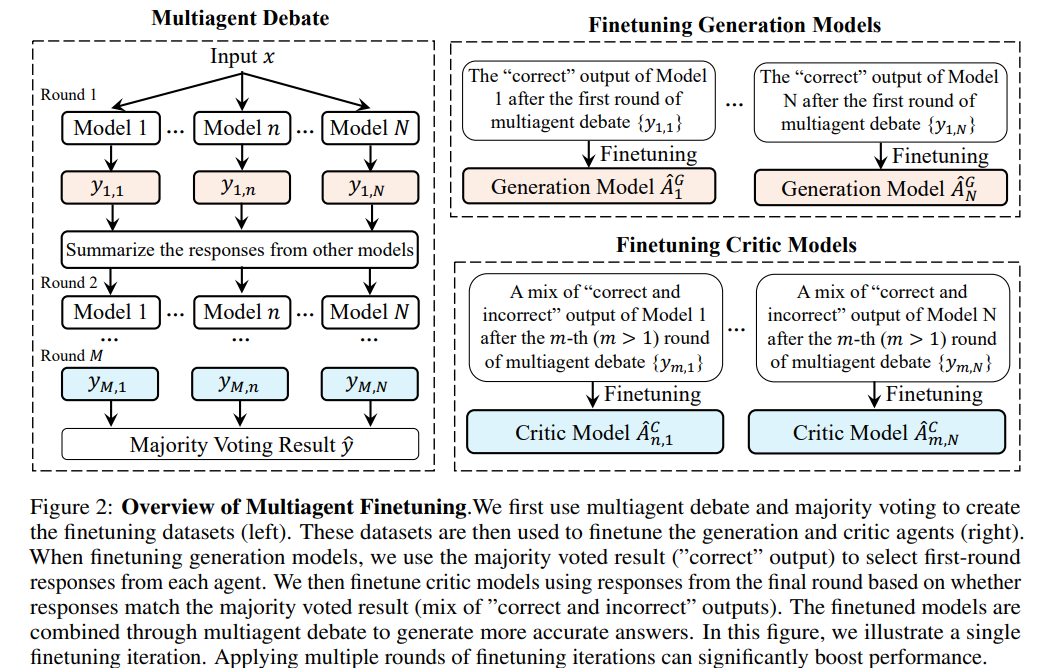
In conclusion, The proposed multiagent fine-tuning framework enhances language model performance and diversity by training a society of specialized agents with distinct roles. Unlike single-agent self-improvement, this approach fosters iterative fine-tuning using independently generated data, enabling models to preserve diverse reasoning chains and achieve greater specialization. While effective, multiagent fine-tuning is resource-intensive, requiring substantial GPU memory and time for training and inference. Potential improvements include weight sharing or distilling debates into a single model. This versatile framework, applicable to open-source and proprietary models, outperforms single-agent methods and opens avenues for integrating human feedback-based approaches like RLHF or DPO in future research.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Enhancing Language Model Performance and Diversity Through Multiagent Fine-Tuning appeared first on MarkTechPost.
