


Video-based technologies have become essential tools for information retrieval and understanding complex concepts. Videos combine visual, temporal, and contextual data, providing a multimodal representation that surpasses static images and text. With the increasing popularity of video-sharing platforms and the vast repository of educational and informational videos available online, leveraging videos as knowledge sources offers unprecedented opportunities to answer queries that require detailed context, spatial understanding, and process demonstration.
Retrieval-augmented generation systems, which combine retrieval and response generation, often neglect the full potential of video data. These systems typically rely on textual information or occasionally include static images to support query responses. However, they fail to capture the richness of videos, which include visual dynamics and multimodal cues essential for complex tasks. Conventional methods either predefine query-relevant videos without retrieval or convert videos into textual formats, losing critical information like visual context and temporal dynamics. This inadequacy hinders providing precise and informative answers for real-world, multimodal queries.

Current methodologies have explored textual or image-based retrieval but have not fully utilized video data. In traditional RAG systems, video content is represented as subtitles or captions, focusing solely on textual aspects or reduced to preselected frames for targeted analysis. Both approaches limit the multimodal richness of videos. Moreover, the absence of techniques to dynamically retrieve and incorporate query-relevant videos further restricts the effectiveness of these systems. The lack of comprehensive video integration leaves an untapped opportunity to enhance the retrieval-augmented generation paradigm.
Research teams from KaiST and DeepAuto.ai proposed a novel framework called VideoRAG to address the challenges associated with using video data in retrieval-augmented generation systems. VideoRAG dynamically retrieves query-relevant videos from a large corpus and incorporates visual and textual information into the generation process. It leverages the capabilities of advanced Large Video Language Models (LVLMs) for seamless integration of multimodal data. The approach represents a significant improvement over previous methods by ensuring the retrieved videos are contextually aligned with user queries and maintaining the temporal richness of the video content.
The proposed methodology involves two main stages: retrieval and generation. It then identifies videos by their similar visual and textual aspects concerning the query during retrieval. VideoRAG applies automatic speech recognition to generate the auxiliary textual data for a video that is not available with subtitles. This stage ensures that the response generation from all videos gets meaningful contributions from each video. The relevant retrieved videos are further fed into the generation module of the framework, where multimodal data like frames, subtitles, and query text are integrated. These inputs are processed holistically in LVLMs, enabling them to produce long, rich, accurate, and contextually apt responses. The focus of VideoRAG on visual-textual element combinations makes it possible to represent intricacies in complex processes and interactions that cannot be described using static modalities.
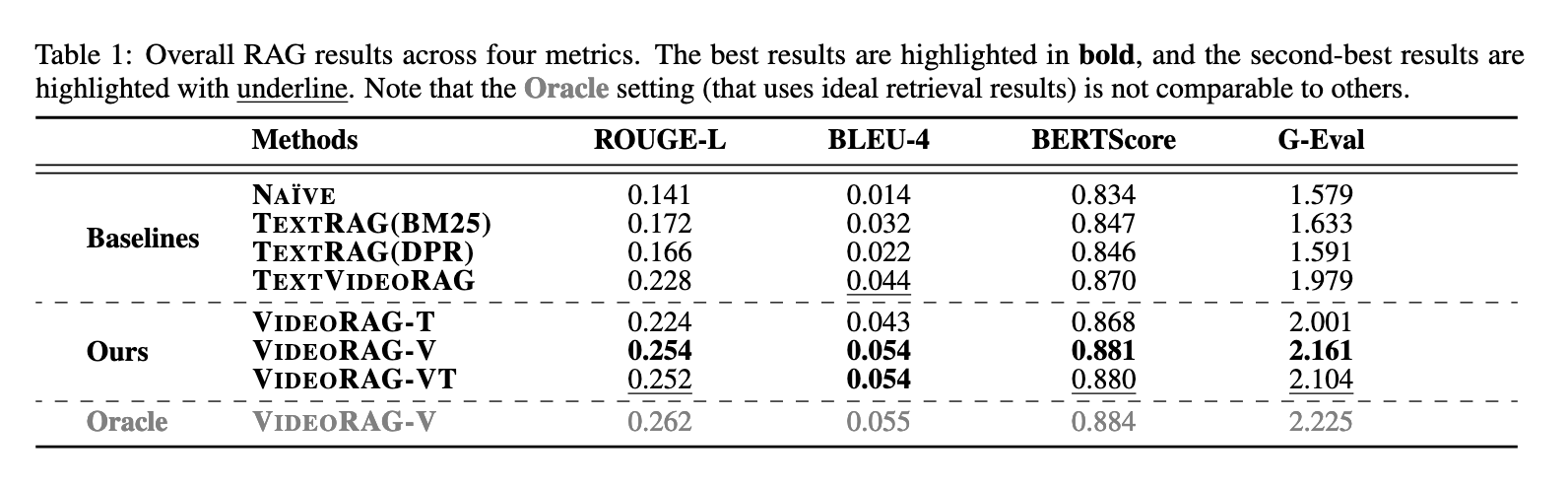
VideoRAG was extensively experimented with on datasets like WikiHowQA and HowTo100M. These datasets encompass a broad spectrum of queries and video content. In particular, the approach revealed a better response quality, according to various metrics, like ROUGE-L, BLEU-4, and BERTScore. So, regarding the VideoRAG method, the score was 0.254 according to ROUGE-L, whereas for text-based methods, RAG reported 0.228 as the maximum score. It’s also demonstrated the same with the BLEU-4, the n-gram overlap: for VideoRAG; this is 0.054; for the text-based one, it was only 0.044. The framework variant, which used both video frames and transcripts, further improved performance, achieving a BERTScore of 0.881, compared to 0.870 for the baseline methods. These results highlight the importance of multimodal integration in improving response accuracy and underscore the transformative potential of VideoRAG.

The authors showed that VideoRAG’s ability to combine visual and textual elements dynamically leads to more contextually rich and precise responses. Compared to traditional RAG systems that rely solely on textual or static image data, VideoRAG excels in scenarios requiring detailed spatial and temporal understanding. Including auxiliary text generation for videos without subtitles further ensures consistent performance across diverse datasets. By enabling retrieval and generation based on a video corpus, the framework addresses the limitations of existing methods and sets a benchmark for future multimodal retrieval-augmented systems.
In a nutshell, VideoRAG represents a big step forward in retrieval-augmented generation systems because it leverages video content to enhance response quality. This model combines state-of-the-art retrieval techniques with the power of LVLMs to deliver context-rich, accurate answers. Methodologically, it successfully addresses the deficiencies of the current systems, thereby providing a solid framework for incorporating video data into knowledge generation pipelines. With its superior performance over various metrics and datasets, VideoRAG establishes itself as a novel approach for including videos in retrieval-augmented generation systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios.’ (Promoted)
Recommended Open-Source AI Platform: ‘Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios.’ (Promoted)
The post Meet VideoRAG: A Retrieval-Augmented Generation (RAG) Framework Leveraging Video Content for Enhanced Query Responses appeared first on MarkTechPost.
