


LLMs excel in code generation but struggle with complex programming tasks requiring deep algorithmic reasoning and intricate logic. Traditional outcome supervision approaches, which guide final output quality models, are limited in addressing these challenges. Process supervision using Process Reward Models (PRMs) has shown promise by focusing on reasoning steps, but it demands extensive annotated data and is prone to inaccuracies in evaluating complex reasoning. Code generation uniquely benefits from execution feedback, offering verifiable correctness and performance insights. However, current methods prioritize debugging and local refinements, overlooking opportunities to explore innovative algorithmic strategies for enhanced performance.
Researchers from Peking University and Microsoft Research propose Outcome-Refining Process Supervision (ORPS), a novel framework that supervises the reasoning process by refining outcomes. Unlike traditional methods focused on iterative feedback, ORPS uses a tree-structured exploration to manage multiple reasoning paths simultaneously, enabling diverse solution strategies when initial attempts fail. The approach leverages execution feedback as objective verification, eliminating the need for training PRMs. Experiments show that ORPS significantly improves performance, with an average 26.9% increase in correctness and a 42.2% boost in efficiency across five models and three datasets, highlighting its scalability and reliability in solving complex programming tasks.
Traditional outcome supervision in machine learning focuses solely on evaluating final outputs, often through metrics or language model-based judgments. While these methods offer richer feedback than basic evaluations, they fail to assess the intermediate reasoning steps critical for complex tasks. In contrast, process supervision evaluates the quality of each step using PRMs, which guide reasoning by assigning rewards based on intermediate progress. However, PRMs rely heavily on dense human annotations, face generalization issues, and can produce unreliable evaluations due to model hallucinations. These highlight the need for alternative approaches that ground reasoning in concrete, verifiable signals rather than learned judgments.
ORPS addresses these challenges by treating outcome refinement as an iterative process that needs to be supervised. The framework integrates theoretical reasoning, practical implementation, and execution feedback through a tree-structured exploration with beam search, enabling diverse solution paths. Unlike traditional PRMs, ORPS uses execution outcomes as objective anchors to guide and evaluate reasoning, eliminating the need for expensive training data. A self-critic mechanism further refines solutions by analyzing reasoning chains and performance metrics, allowing models to improve theoretical strategies and implementation efficiency. This approach reduces hallucination risks and significantly enhances success rates and efficiency in solving complex programming tasks.
The study evaluates a new code generation framework to improve performance on programming benchmarks. The framework is tested on three datasets: LBPP, HumanEval, and MBPP, focusing on key questions such as its effectiveness, contributions of individual components, and the relationship between reasoning quality and code generation. The results show significant correctness and code quality improvements, particularly on more complex benchmarks. The method outperforms other execution-feedback approaches, and access to test cases boosts performance further. Ablation studies reveal that execution outcomes are more critical than reasoning alone for optimal performance.
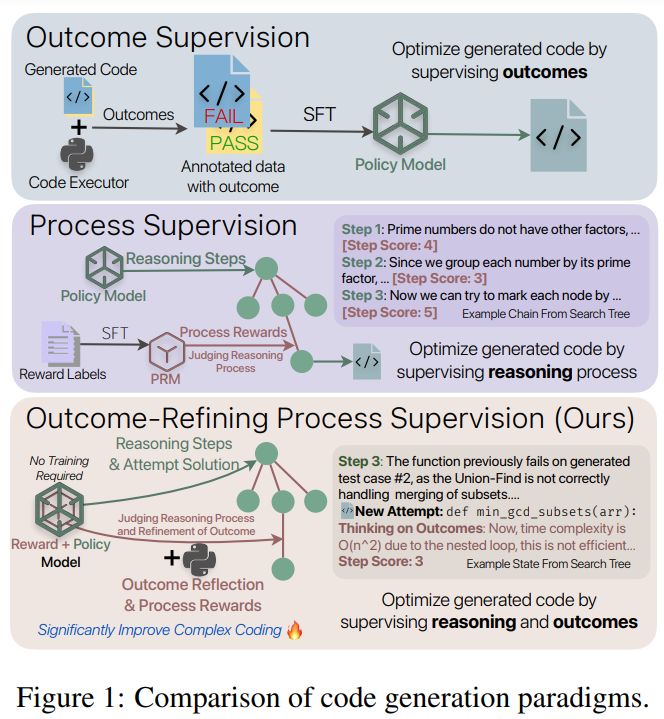
In conclusion, the study introduces ORPS, an approach to improve code generation by integrating structured reasoning with execution-driven feedback. ORPS employs a tree-structured exploration framework that supports diverse solution paths, allowing models to enhance reasoning and implementation simultaneously. Experiments across multiple benchmarks showed significant gains, with an average improvement of 26.9% and a 42.2% reduction in runtime, outperforming traditional methods. ORPS effectively utilizes execution feedback, reducing dependence on costly annotated data. This approach highlights the importance of structured reasoning and concrete feedback for complex programming tasks and offers a cost-efficient alternative for advancing computational intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios.’ (Promoted)
Recommended Open-Source AI Platform: ‘Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios.’ (Promoted)
The post Outcome-Refining Process Supervision: Advancing Code Generation with Structured Reasoning and Execution Feedback appeared first on MarkTechPost.
