
1月10日上午,第二期AIR-SUN少年科学家论坛如期举行。本次活动有幸邀请到加州大学圣地亚哥分校博士生Stone Tao,为AIR的老师和同学们做了题为《Scalable Robot Learning via Simulation and Simulation-Integrated Algorithms》的精彩报告。

讲者介绍

报告内容
陶子进首先从宏观角度解释了仿真及基于此的集成算法对于机器人开发的重要意义。他指出,机器人学习模型的训练和测试需要大量的数据,然而现实世界中的数据采集需要昂贵的人力和时间成本,因此结合使用绝大多数来自仿真的数据和少部分来自现实的数据实现计算资源的可扩展性已成为研究人员的共识。
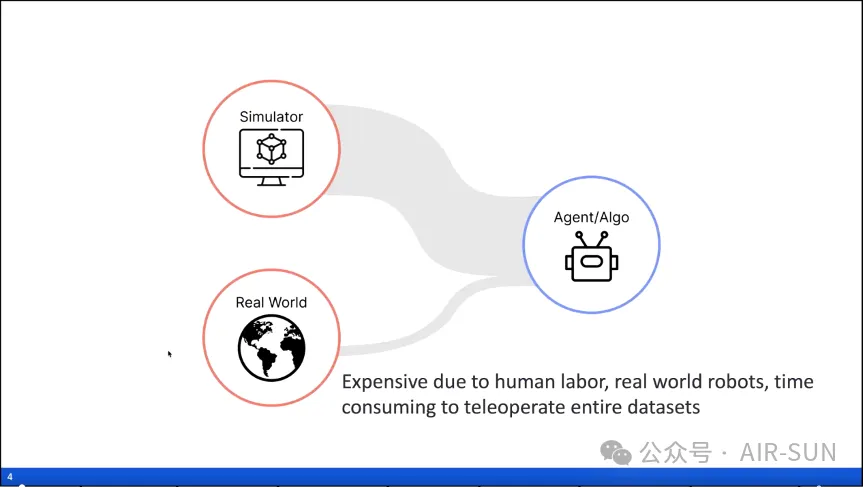
另外,陶子进还结合与强化学习领域的开创性研究者Richard Sutton的观点指出仿真数据能够提供快速且成本低廉的解决方案,但需要保证仿真环境在计算和重置上具备高效性,以免陷入效率低下的困境。
接下来,陶子进先后介绍了仿真在通用机器人学习领域和可扩展数据生成方面的应用,以及通过仿真从极少数实例中进行数据增强的算法,并提出了该领域潜在的未来工作。
在报告的第一部分,陶子进结合他目前负责的项目《ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI》介绍了GPU并行物理仿真在通用机器人学习方面的应用。该项目使用新的GPU版本的物理引擎进行GPU并行物理仿真,并实现了GPU并行渲染功能,拥有业界领先的并行物理仿真和渲染速度及内存优化。另外,陶子进还强调该项目实现了一个非常 Pythonic 的 API 设计,并为用户提供了大量预构建的功能模块,相比于与传统平台(如 ManiSkill、IsaacLab 和 Isaac Gym),ManiSkill3在实现相同任务时所需的代码量更少,可读性也更强。

陶子进在介绍时展示了该项目中的两个具有代表性的案例。其一是使用强化学习(Reinforcement Learning,RL)训练的机器臂拾取不同物体(颜色不同),它采取基于视觉的训练时仅需约30分钟就能实现高效的场景生成,而采取基于状态的训练时仅需不到1分钟。通过该案例,陶子进论证了GPU并行渲染强大的实时渲染功能和潜在的应用。

另一个是机器人在不同形状和尺寸的柜子中开门的场景,其中每个包含了不同的物体,这些物体的自由度数量也各不相同。该任务仅需很少的代码行数即可快速实现,证明了ManiSkill3的并行仿真训练出的是通用策略,并且它的场景生成能力简洁高效。在此基础上,陶子进指出在GPU上仿真出特定场景的成千上万种不同变化是可行的,并正在通过《ManiSkill Habitat》子项目实现该能力。


之后,陶子进结合案例介绍了该项目在真实世界的机器人应用。他介绍了一个低成本的机器人(约2000元人民币)在真实世界中执行zero shots强化学习任务的案例。该机器人只有RGB图像和关节数据而没有场景信息(立方体的位置等)输入,且场景识别仅使用了一个3层的CNN网络,就实现了使用单个RGB相机学习拾取不同颜色的立方体。在该案例中,为了进一步减少仿真与现实世界之间的差距,采用了域随机化(Domain Randomization)技术,通过随机化立方体的大小、颜色、摩擦力以及相机的位置和角度等多个变量,增强了训练的多样性,但也使得机器人晃动很大。陶子进指出,通过将真实世界的背景图像嵌入到仿真中,能够解决这一问题。这是因为输入背景图像能进一步缩小仿真与现实之间的差异,简化了环境的适应性问题。尽管这个方法并不完美,陶子进认为这为快速且高效的仿真到现实的迁移提供了一个新的方向,尤其适用于那些不要求精确操作的任务,如位置放置等。
在报告的第二部分,陶子进讲述了仿真集成算法,重点讨论了如何利用仿真特性加速学习过程并进行数据增强。这类算法的核心目标是通过少量的操作生成更多的数据和仿真,在这一方面,陶子进认为基于机器学习的方法相比于非学习方法有许多优势。因为基于学习的方法可以训练出一个通用策略,进行策略回放,然后生成更多的数据,使其能够泛化不同的几何形状。其次,通过使用课程学习(Curriculum Learning,CL)和RL,能够处理更精细的任务,而非学习的方法如由NVIDIA最近推广的MimicGen在这方面的表现则不尽如人意。
陶子进接着介绍了自己提出的反向前向课程学习(Reverse Forward Curriculum Learning,RFCL)方法。该方法的核心概念是首先使用反向课程学习(Reverse Curriculum Learning,RCL)在一个较窄的初始状态分布范围内训练一个较弱的策略,然后利用前向课程学习(Forward Curriculum Learning,FCL)将这个策略泛化到更广泛的初始状态分布上。
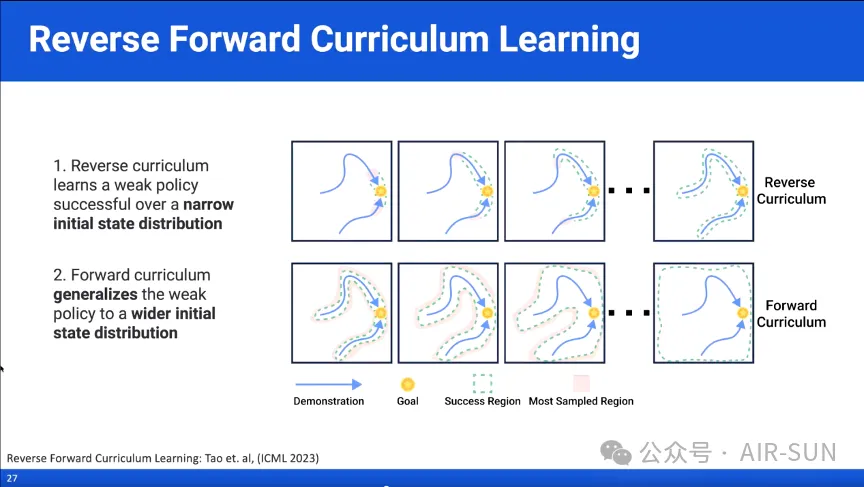
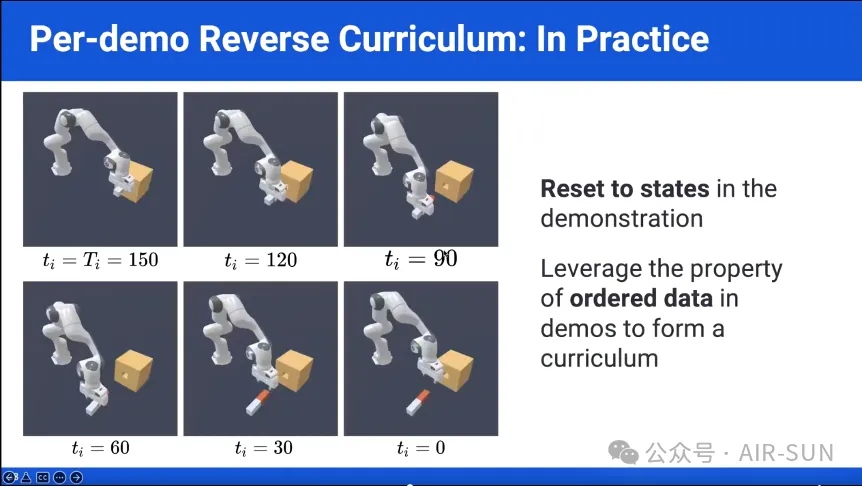
陶子进结合楔子插入木块孔洞和从桌子的任意位置拿起物体两个案例论证了RFCL的泛化能力。以楔子插入木块孔洞的任务为例,在这个任务中,目标是将一个楔子插入一个孔中,任务需要150步才能完成。RFCL方法首先从任务的最后一步开始训练,利用仿真中的状态重置功能生成一个高效的学习过程,在这个过程中,策略只有在成功完成任务时才会获得稀疏奖励。随着训练的进行,逐渐从更早的状态开始训练,直到最终达到任务的起始状态。在RFCL的第二阶段,使用FCL将已经训练好的策略推广到不同的初始条件。通过优先选择更具挑战性的初始状态,系统能够提高在困难配置下的表现,从而实现更好的任务泛化。
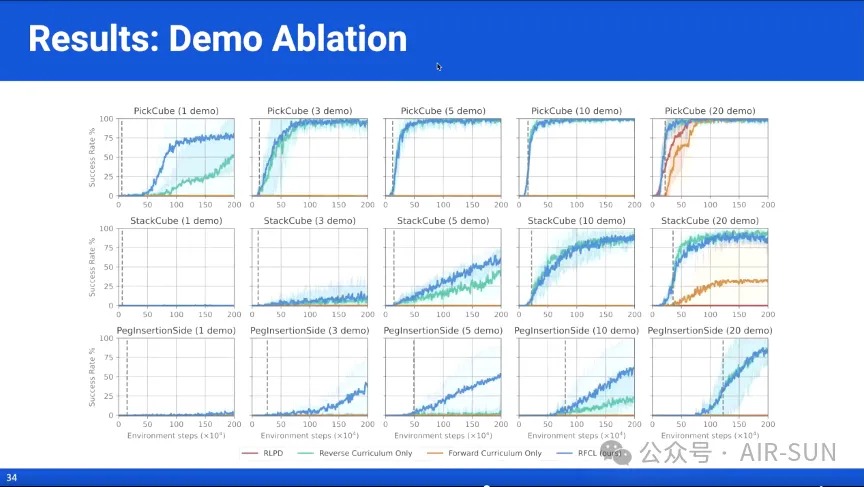
之后,在楔子插入、堆叠和捡起物体等任务中,Stone Tao博士将PFCL与当前最先进的方法如基于先验数据的强化学习(Reinforcement Learning with Prior Data,RLPD)以及单独的PCL和FCL相对比,证明了PFCL具备基于少量数据泛化出近乎无限仿真数据的能力,并且效果显著地好于这些方法。
在报告的结尾部分,陶子进对未来工作进行了展望,并与大家进行了深入交流。他指出,在RFCL方法中基于学习的数据增强方法可能会学习到不现实的行为,对这一现象的规避是未来的研究方向之一。他未来还希望能够利用GPU仿真。此外,他认为通过课程学习来逐步提高物理仿真的保真度,先训练较低精度的仿真,再逐步过渡到更高精度的物理模拟,将是综合实现快速训练和高保真度的物理仿真与场景渲染的重要研究思路。

内容中包含的图片若涉及版权问题,请及时与我们联系删除
