index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
本次报告深入探讨了“LLM-as-a-Judge”方法论,该方法旨在利用大语言模型(LLMs)模拟人类推理,进行自动化评估,以解决传统评估方法在全面性和可扩展性之间的难题。报告指出,尽管LLM评估者具备融合自动化与专家评估优势的潜力,但在实际应用中仍面临缺乏系统性综述和可靠性问题两大挑战。报告详细分析了LLM评估者的定义、应用方法,以及如何构建可靠的系统,并探讨了其在科研、金融量化等领域的应用价值,为研究者和实践者提供了构建更优AI评估框架的路线图。
💡LLM-as-a-Judge的核心概念:利用LLM模拟人类推理,判断事物是否符合既定规则,旨在解决传统评估方法在全面性和可扩展性之间的平衡难题。它既能模拟专家评估的细致推理,又具备自动化方法的可扩展性。
⚙️LLM-as-a-Judge的应用方法:报告分析了包括上下文学习、模型选择和后处理策略等典型方法论,为具体任务的实施提供了指南。例如,通过适当的提示学习或微调,LLM有望处理多模态输入,增强其评估能力。
🛡️构建可靠的LLM评估系统:报告强调了提升系统可靠性的关键策略和评价方法,如去偏、优化和基准测试。深入评估LLM生成结果,并探讨如何构建可靠的评估系统是至关重要的。
报告主题:LLM-as-a-Judge方法论,应用中的挑战和未来研究方向探讨报告日期:01月16日(本周四)14:30-16:00随着大语言模型(LLMs)在技术和应用领域的持续突破,“LLM担任评估者”(LLM-as-a-Judge)正在成为推动通用人工智能(AGI)发展的重要途径。LLM-as-a-Judge这一概念旨在让LLM判断某事物是否符合既定规则,其吸引力源于LLM模拟人类推理和思考过程的能力,使其能承担传统上由人类专家负责的角色,同时提供一种成本低且可扩展的解决方案。例如,在学术同行评审过程中引入LLM-as-a-Judge,既可以应对快速增长的投稿数量,又能维持专家级的判断水平。然而,在LLM出现之前,全面性与可扩展性之间的评估平衡一直是一个长期存在的难题。专家驱动的主观评估方法虽然因其整体性推理和细腻的上下文理解能力被认为是评估全面性的黄金标准,但其成本高昂、难以扩展且容易不一致;而自动化指标等客观评估方法虽具备高效、一致的优势,但其依赖表层词汇匹配的特性导致在捕捉深层语义和细节方面表现不佳,从而难以胜任诸如故事生成或指导性文本等任务。由此,“LLM-as-a-Judge”被提出为一种潜在解决方案,通过融合自动化方法的可扩展性与专家评估的细腻推理能力来克服这一困境。此外,在适当的提示学习(prompt learning)或微调(fine-tuning)条件下,LLM还有望具备处理多模态输入的能力,这一独特优势使其相较传统评估方法更具竞争力。基于这些特点,“LLM-as-a-Judge”有望成为应对复杂和开放式评估问题的新范式。然而,尽管这一方法展现出作为一种可扩展且适应性强的评估框架的巨大潜力,其应用仍面临两大挑战:其一,缺乏系统化的综述,对“LLM-as-a-Judge”的研究尚未形成正式定义,相关理解零散且实践方法随意,使得研究人员和实践者难以全面了解和有效应用;其二,可靠性问题依然存在,仅依赖LLM-as-a-Judge并不能保证评估结果的准确性与标准一致性。因此,必须深入评估LLM-as-a-Judge生成的输出,并进一步探讨如何构建可靠的LLM-as-a-Judge系统。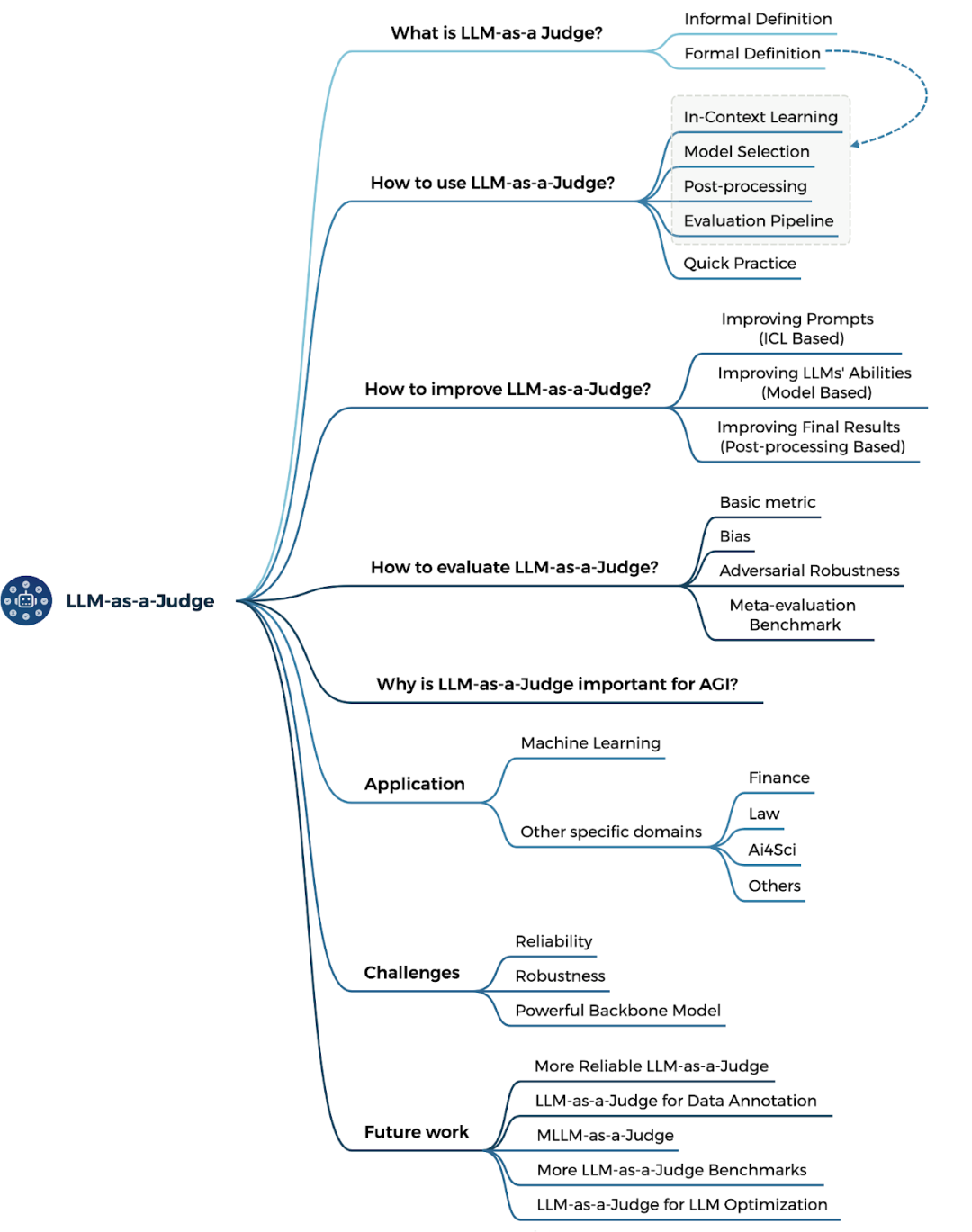 本次报告将深入分析这一领域的方法论和未来研究方向,解答如下关键问题:
本次报告将深入分析这一领域的方法论和未来研究方向,解答如下关键问题:什么是 LLM-as-a-Judge?我们将探讨其正式与非正式定义,揭示其核心机制和应用场景。如何使用 LLM-as-a-Judge?通过分析典型方法论,包括上下文学习(In-Context Learning)、模型选择和后处理策略,为具体任务提供实施指南。如何构建可靠的 LLM-as-a-Judge 系统?重点介绍提升系统可靠性的关键策略和评价方法,如去偏、优化和基准测试。LLM-as-a-Judge的重要性何在?作为能够跟环境进行交互获得反馈的方式,使得模型不断自我进化以走向通用智能。
通过这些问题的系统分析,本次报告为研究者与实践者提供了构建更可靠、可扩展、适应性强的AI评估框架的路线图。在此基础上,我们将以圆桌交流的方式来探讨LLM-as-a-Judge 的应用价值如何体现,聚焦于其在科研、金融量化等领域的潜力和应用案例的分析讨论。徐铖晋博士,IDEA研究院AI研究科学家,DataArc联合创始人&CTO,深圳市特聘专家。研究方向包括大语言模型、合成数据、知识图谱等。在TPAMI、ICLR等AI领域顶刊顶会上发表论文40余篇。代表工作有Think-on-Graph系列——基于知识驱动的大模型推理增强算法。王赛卓,香港科技大学计算机科学与工程学系博士生,研究方向为深度学习/大语言模型与量化投资。相关工作包括人与AI协作式因子挖掘系统Alpha-GPT、基于Self-improving LLM的因子挖掘算法QuantAgent等。顾嘉炜, 中山大学计算机科学与技术专业的硕士生,在International Digital Economy Academy (IDEA Research) ,实习期间完成A survey on LLM-as-a-Judge相关工作。她的研究兴趣主要集中于Scaling Law, Reasoning Enhancement 和 Efficient Learning 等。她曾在SenseTime Research实习,并在EMNLP等顶会上发表文章。 内容中包含的图片若涉及版权问题,请及时与我们联系删除





