


Large language models (LLMs) have become crucial tools for applications in natural language processing, computational mathematics, and programming. Such models often require large-scale computational resources to execute inference and train the model efficiently. To reduce this, many researchers have devised ways to optimize the techniques used with these models.
A strong challenge in LLM optimization arises from the fact that traditional pruning methods are fixed. Static Pruning removes unnecessary parameters based on a prespecified mask. They cannot be applied if the required skill for an application is coding or solving mathematical problems. These methods lack flexibility, as the performance is usually not maintained for several tasks while optimizing the computational resources.
Historically, techniques such as static structured Pruning and mixture-of-experts (MoE) architectures have been used to counter the computational inefficiencies of LLMs. Structured Pruning removes components like channels or attention heads from specific layers. Although these methods are hardware-friendly, they require full retraining to avoid a loss of model accuracy. MoE models, in turn, activate parts of the model during inference but incur huge overheads from frequent parameter reloading.
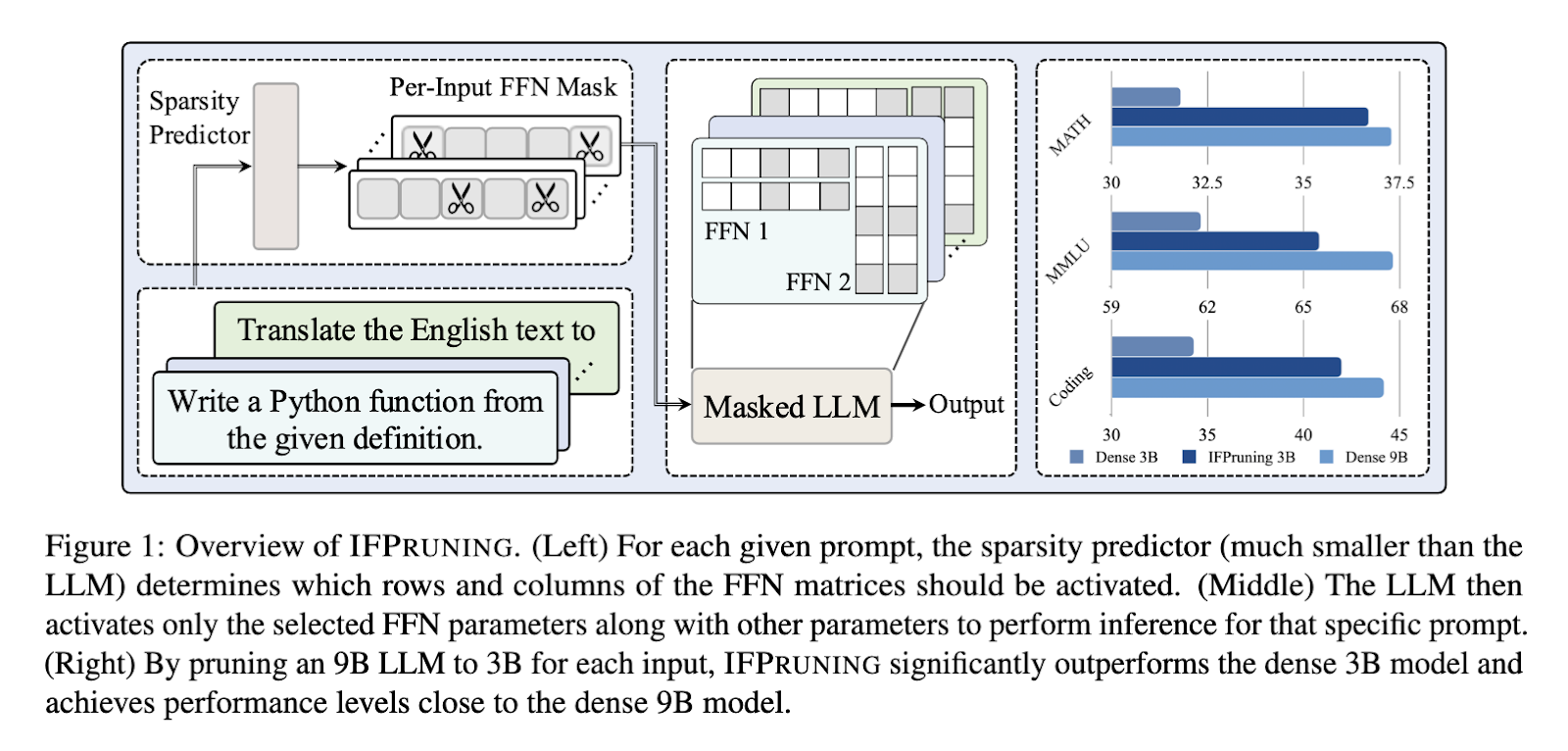
Apple AI and UC Santa Barbara researchers have introduced a new technique called Instruction-Following Pruning (IFPruning), which dynamically adapts LLMs to the needs of a particular task. IFPruning uses a sparsity predictor that generates input-dependent pruning masks, selecting only the most relevant parameters for a given task. Unlike traditional methods, this dynamic approach focuses on feed-forward neural network (FFN) layers, allowing the model to adapt to diverse tasks while reducing computational demands efficiently.
The researchers propose a two-stage training process for IFPruning: First, continue pre-training dense models on large data, maximizing the sparsity predictor and the LLM. This produces a strong starting point for subsequent fine-tuning. In stage two, training is performed only on supervised fine-tuning datasets, using highly varied task prompts and multiple examples. Masking is still dynamic due to the online generation of sparsity predictors pruning out unnecessary weights without affecting model performance. This eliminates the need for parameter reloading, a limitation observed in prior dynamic methods.
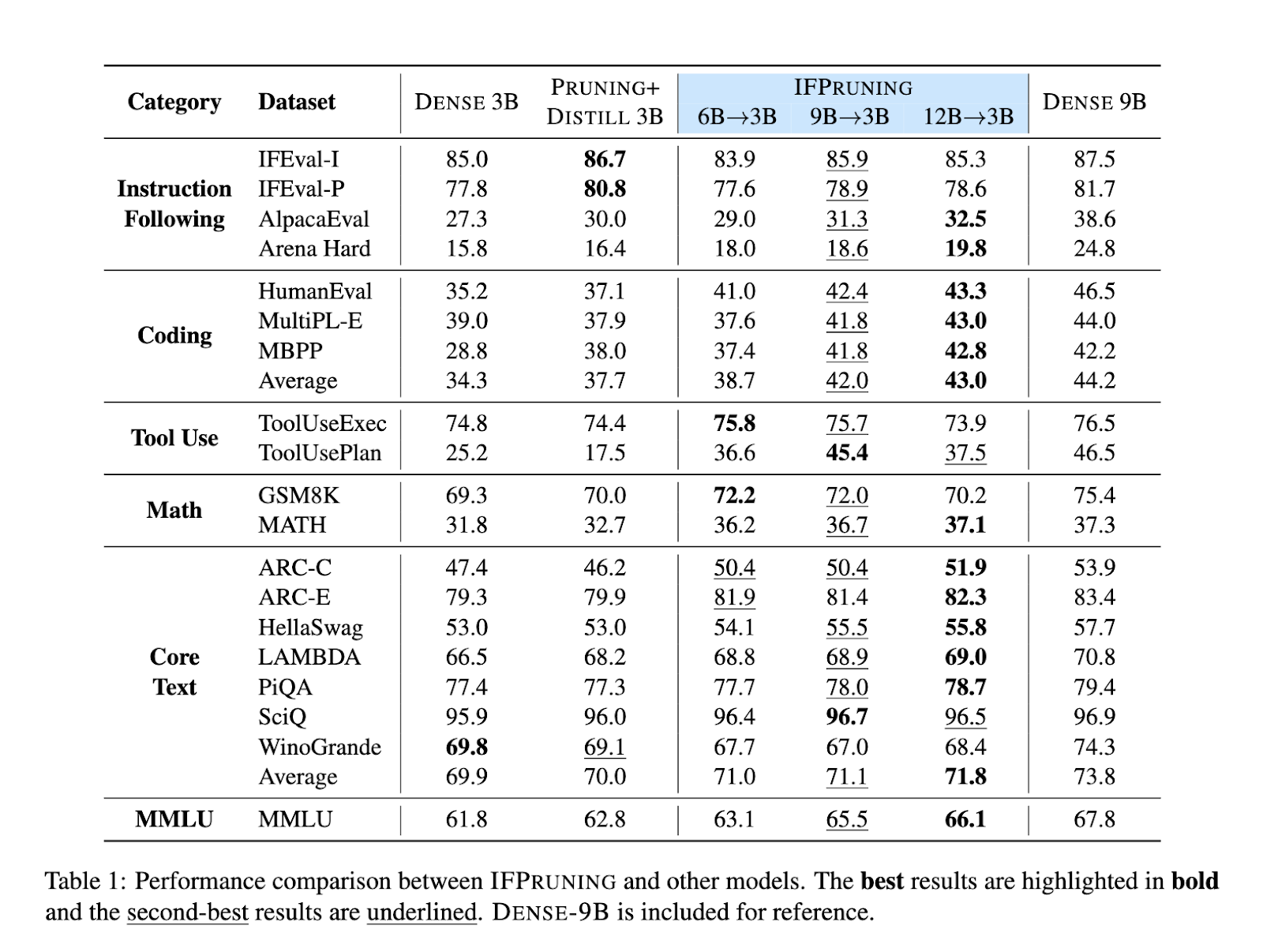
The performance of IFPruning was rigorously evaluated across multiple benchmarks. For instance, pruning a 9B parameter model to 3B improved coding task accuracy by 8% compared to a dense 3B model, closely rivaling the unpruned 9B model. On mathematical datasets like GSM8K and MATH, the dynamic pruning approach yielded a 5% increase in accuracy. It exhibited consistent gains on instruction-following evaluation in both IFEval and AlpacaEval for around 4-6 percent points. Even with multi-task benchmarks like MMLU, it showed promising robust results of IFPruning, displaying versatility across other domains.
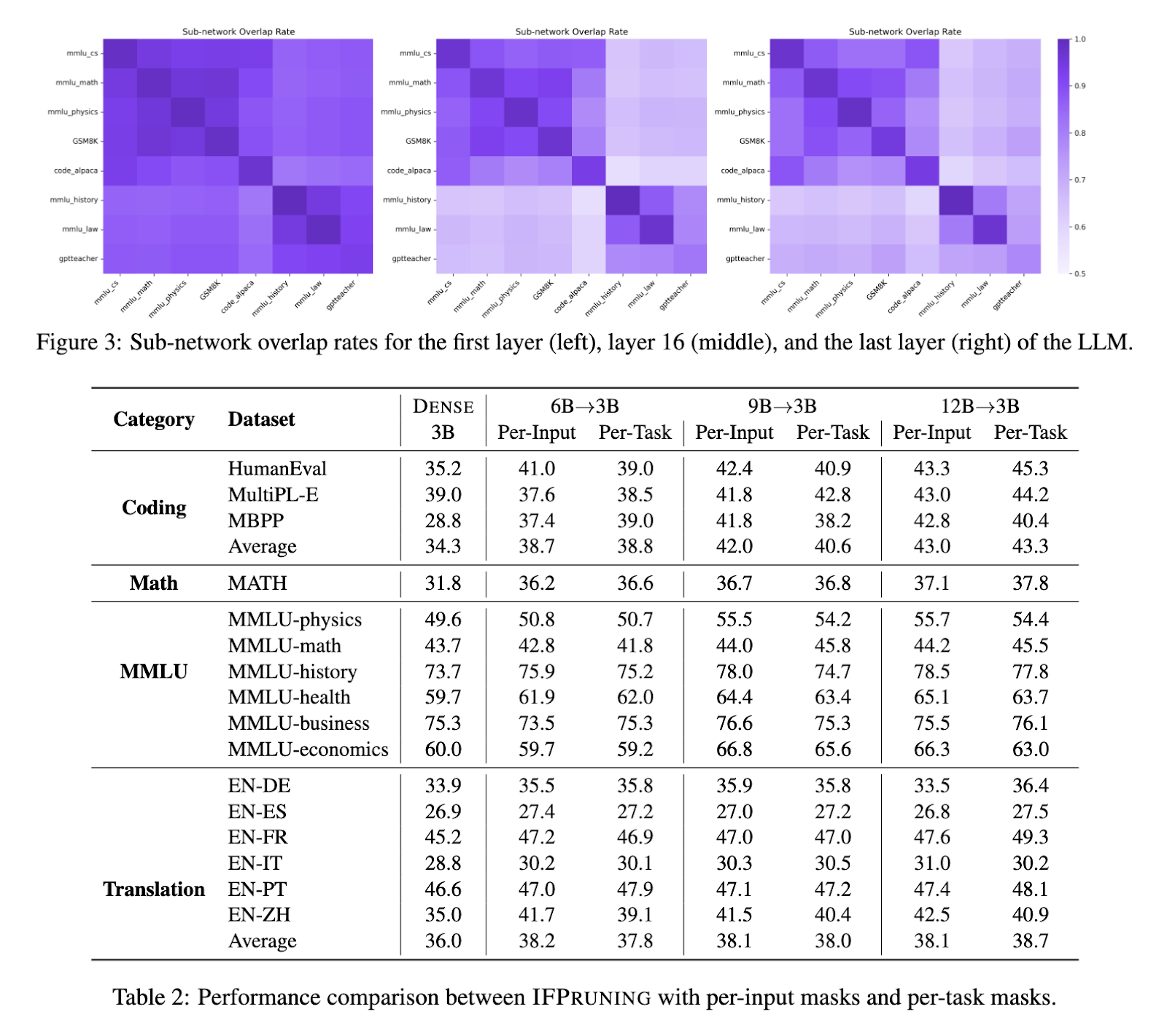
These results underpin the IFPruning approach’s scalability since models with varying sizes, namely 6B, 9B, and 12B parameters, have been tested; in all, important performance improvements post-pruning are achieved. Scaling from a 6B dense model to a 12B dense model showed that, under the same condition, efficiency was improved along with task-specific accuracy. It further outperformed traditional structured pruning methods like Pruning + Distill due to the use of a dynamic sparsity mechanism.
The introduction of IFPruning marks a significant advancement in optimizing LLMs, providing a method that dynamically balances efficiency and performance. The approach addresses the limitations of static pruning and MoE architectures, setting a new standard for resource-efficient language models. With its ability to adapt to varied inputs without sacrificing accuracy, IFPruning presents a promising solution for deploying LLMs on resource-constrained devices.
This research will point out further developments in model pruning, which include optimizing other components, such as attention heads and hidden layers. Even though the methodology presented today tackles many of the computational challenges, further research in server-side applications and multi-task Pruning can broaden its scope of applicability. As a dynamic and efficient framework, IFPruning opens up possibilities for more adaptive and accessible large-scale language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Apple Researchers Introduce Instruction-Following Pruning (IFPruning): A Dynamic AI Approach to Efficient and Scalable LLM Optimization appeared first on MarkTechPost.
