


Autoregressive pre-training has proved to be revolutionary in machine learning, especially concerning sequential data processing. Predictive modeling of the following sequence elements has been highly effective in natural language processing and, increasingly, has been explored within computer vision domains. Video modeling is one area that has hardly been explored, giving opportunities for extending into action recognition, object tracking, and robotics applications. These developments are due to growing datasets and innovation in transformer architectures that treat visual inputs as structured tokens suitable for autoregressive training.
Modeling videos has unique challenges due to their temporal dynamics and redundancy. Unlike text with a clear sequence, video frames usually contain redundant information, making it difficult to tokenize and learn proper representations. Proper video modeling should be able to overcome this redundancy while capturing spatiotemporal relationships in frames. Most frameworks have focused on image-based representations, leaving the optimization of video architectures open. The task requires new methods to balance efficiency and performance, particularly when video forecasting and robotic manipulation are at play.
Visual representation learning via convolutional networks and masked autoencoders has been effective for image tasks. Such approaches typically fail regarding video applications as they cannot entirely express temporal dependencies. Tokenization methods such as dVAE and VQGAN normally convert visual information into tokens. These have shown effectiveness, but scaling such an approach becomes challenging in scenarios with mixed datasets involving images and videos. Patch-based tokenization does not generalize to cater to various tasks efficiently in a video.
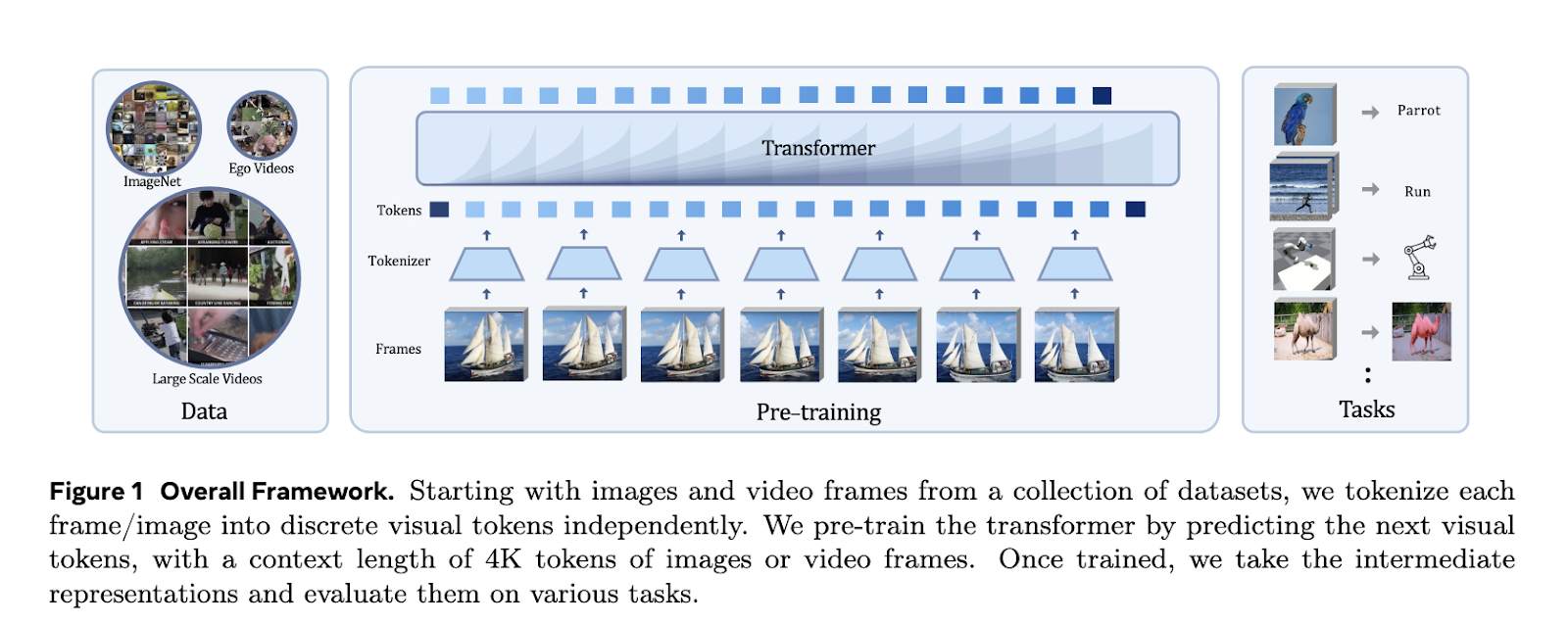
A research team from Meta FAIR and UC Berkeley has introduced the Toto family of autoregressive video models. Their novelty is to help address the limitations of traditional methods, treating videos as sequences of discrete visual tokens and applying causal transformer architectures to predict subsequent tokens. The researchers developed models that could easily combine image and video training by training on a unified dataset that includes more than one trillion tokens from images and videos. The unified approach enabled the team to take advantage of the strengths of autoregressive pretraining in both domains.
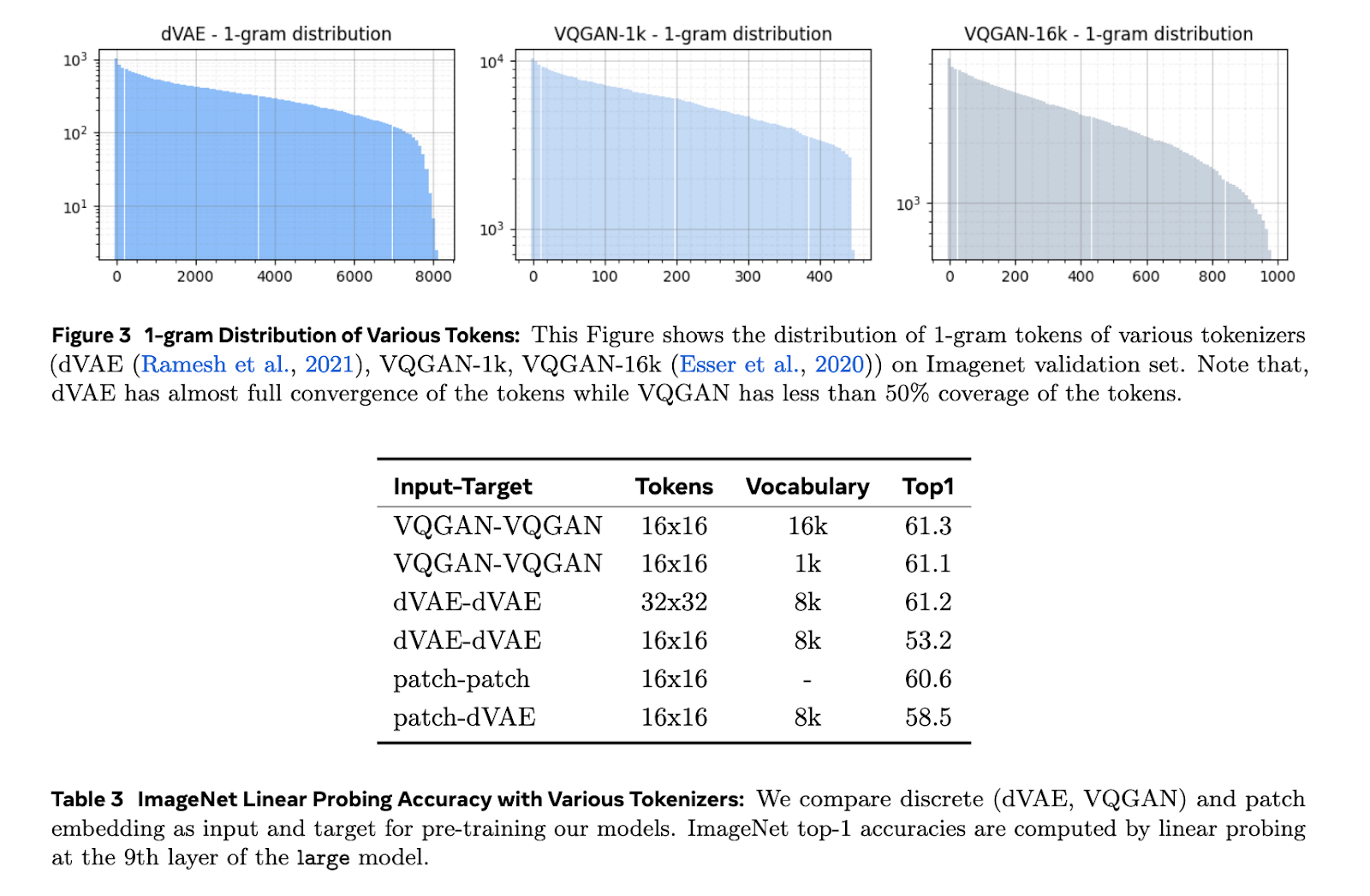
The Toto models use dVAE tokenization with an 8k-token vocabulary to process images and video frames. Each frame is resized and tokenized separately, resulting in sequences of 256 tokens. These tokens are then processed by a causal transformer that uses the features of RMSNorm and RoPE embeddings to establish improved model performance. The training was done on ImageNet and HowTo100M datasets, tokenizing at a resolution of 128×128 pixels. The researchers also optimized the models for downstream tasks by replacing average pooling with attention pooling to ensure a better quality of representation.
The models show good performance across the benchmarks. For ImageNet classification, the largest Toto model achieved a top-1 accuracy of 75.3%, outperforming other generative models like MAE and iGPT. In the Kinetics-400 action recognition task, the models achieve a top-1 accuracy of 74.4%, proving their capability to understand complex temporal dynamics. On the DAVIS dataset for semi-supervised video tracking, the models obtain J&F scores of up to 62.4, thus improving over previous state-of-the-art benchmarks established by DINO and MAE. Moreover, on robotics tasks like object manipulation, Toto models learn much faster and are more sample efficient. For example, the Toto-base model attains a cube-picking real-world task on the Franka robot with an accuracy of 63%. Overall, these are impressive results regarding the versatility and scalability of these proposed models with diverse applications.

The work provided significant development in video modeling by addressing redundancy and challenges in tokenization. The researchers successfully showed “through unified training on both images and videos, that this form of autoregressive pretraining is generally effective across a range of tasks.” Innovative architecture and tokenization strategies provide a baseline for further dense prediction and recognition research. This is one meaningful step toward unlocking the full potential of video modeling in real-world applications.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post This AI Paper Introduces Toto: Autoregressive Video Models for Unified Image and Video Pre-Training Across Diverse Tasks appeared first on MarkTechPost.
