
Published on January 10, 2025 4:53 PM GMT
Epistemic status -- sharing rough notes on an important topic because I don't think I'll have a chance to clean them up soon.
Summary
Suppose a human used AI to take over the world. Would this be worse than AI taking over? I think plausibly:
- In expectation, human-level AI will better live up to human moral standards than a randomly selected human. Because:
- Humans fall far short of our moral standards. Current models are much more nice, patient, honest and selfless than humans.
- Though human-level AI will have much more agentic training for economic output, and a smaller fraction of HHH training, which could make them less nice.
- Humans evolved under conditions where selfishness and cruelty often paid high dividends, so evolution often "rewarded" such behaviour. And similarly, during lifetime learning we often get benefit from immoral behaviour. But we'll craft the training data for AIs to avoid this, and can much more easily monitor there actions and even their thinking. Of course, this may be hard to do for superhuman AI but bootstrapping could work.
AGI is nicer than humans in expectation
- Humans suck. We really don’t come close to living up to our moral standards.By contrast, today’s AIs are really nice and ethical. They’re humble, open-minded, cooperative, kind. Yes, they care about some things that could give them instrumental reasons to seek power (eg being helpful, human welfare), but their values are greatThe above is no coincidence. It falls right out of the training data.
- Humans were rewarded by evolution for being selfish whenever they could get away with it. So humans have a strong instinct to do that.Humans are rewarded by within-lifetime learning for being selfish. (Culture does increasingly well to punish this, and people have got nicer. But people still have many (more subtle) bad and selfish behaviours reinforced during their lifetimes)But AIs are only ever rewarded for being nice and helpful. We don’t reward them for selfishness. As AIs become super-human there’s a risk we do increasingly reward them for tricking us into thinking they’ve done a better job than they have; but we’ll be way more able to constantly monitor them during training and exclusively reward good behaviour than evolution. Evolution wasn’t even trying to reward only good behaviour! Lifetime learning is a more tricky comparison. Society does try to monitor people and only reward good behaviour, but we can’t see people’s thoughts and can’t constantly monitor their behaviour: so AI training will do a much better job and making AIs nice than humans!What’s more, we’ll just spend loads of time rewarding AIs for being ethical and open minded and kind. Even if we sometimes reward them for bad behaviour, the quantity of reward for good behaviour is something unmatched in humans (evolution or lifetime).Note: this doesn’t mean AIs won’t seek power. Humans seek power a lot! And especially when AIs are super-human, it may be very easy for them to get power.
Conditioning on AI actually seizing power
- Ok, that feeds into my prior for how ethical or unethical i expect humans vs AIs to be. I expect AIs to be way better! But, crucially, we need to condition on takeover. I’m not comparing the average human to the average AI. I’m comparing the average human-that-would-actually-seize-power to the average AI-that-would-seize-power. That could make a difference.And i think it does make a difference. Directionally, I think it pushes towards being more concerned about AIs. Why is that?
- We know a fair bit about human values. While I think humans are not great on average, we know about the spread of human values. We know most humans like the normal human things like happiness, games, love, pleasure, friendships. (Though some humans want awful things as well.) This, maybe, means the variance of human values isn’t that big. We can imagine have some credence over how nice a randomly selected person will be, represented by a probability distribution, and maybe the variance of the distribution is narrow.By contrast, we know a lot less about what AGIs values will be. Like I said above, I expect them to be better (by human standards) than an average humans values. But there’s truly massive uncertainty here. Maybe LWers will be right and AIs will care about some alien stuff that seems totally wacky to humans. We could represent this with a higher variance over our credence over AGI’s values.When we condition on AI or human takeover, we’re conditioning on the AI/human having much worse values than our mean expectation. Even if AIs have better values in expectation, it might be that after conditioning on this they have worse values (bc of the bigger variance – see graph). I’ve placed a red line to represent ‘how bad’ your values would need to be to seize power. The way i’m done it, an AGI that seized power would use the cosmic endowment less well in expectation than that a human who seized power
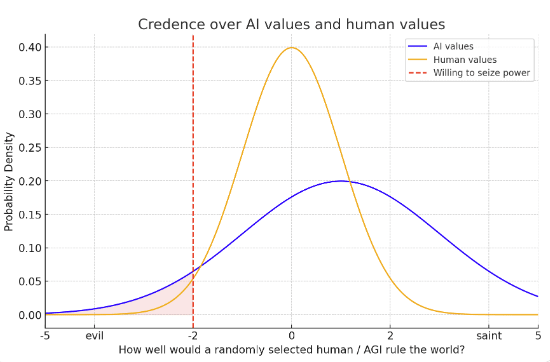
- Actually, this ‘red line’ is not quite the right way to think about it. Whether you seize power depends more on your deontological drive to “cooperate and respect property rights and the law and freedom”, and only somewhat on your long-term goals. All consequentialists want to take over! So whether you take over is more a question of corrigibility vs consequentialism than a question of “how good are your consequentialist values?”
- So when we condition on AI takeover, we’re primarily conditioning on the ‘corrigible’ part of training to have failed. That probably implies the “give the AI good values” part of training may have also gone less well, but it seems possible that there are challenges to corrigibility that don’t apply to giving AI good values (e.g. the MIRI-esque “corrigibility is unnatural”).So AIs taking over is only a moderate update towards them having worse values, even though its a strong update against corrigibility/cooperativeness!
Conditioning on the human actually seizing power
- But there are some further reasons to think human coups could be especially bad
- Human variance is high. Humans vary massively in how moral they are. And i think it’s a pretty self-obsessed dark-triad kind of person that might ultimately seize power for themselves and a small group in a DSA. So the human left-tail could be pretty long, and the selection effect for taking over could be very strong. Humans in power have done terrible things.
- However, humans (e.g. dark triad) are often bad people for instrumental reasons. But if you’re already world leader and have amazing tech + abundance, there’s less instrumental reason to mess others around. This pushes towards the long-run outcome of a human coup being better than you might think by eye-balling how deeply selfish and narcissistic the person doing the coup is.
Other considerations
- Humans less competent. Humans are also more likely to do massively dumb (and harmful) things – think messing up commitment games, threats, simulations, and VHW stuff. I expect AGIs who seize power would have to be extremely smart and would avoid dumb and hugely costly errors. I think this is a very big deal. It’s well known in politics that having competent leaders is often more important than having good values.Some humans may not care about human extinction per se.Alien AI values? I also just don’t buy that AIs will care about alien stuff. The world carves naturally into high-level concepts that both humans and AIs latch onto. I think that’s obvious on reflection, and is supported by ML evidence. So I expect AGIs will care about human-understandable stuff. And humans will be trying hard to make that stuff that’s good by human lights, and I think we’ll largely succeed. Yes, AGIs may reward seek and they may extrapolate their goals to the long-term and seek power. But I think they’ll be pursuing human-recognisable and broadly good-by-human-lights goals.
- There’s some uncertainty here due to ‘big ontological shifts’. Humans 1000 years ago might have said God was good, nothing else (though really they loved friendships and stories and games and food as well). Those morals didn’t survive scientific and intellectual progress. So maybe AIs values will be alien to us due to similar shifts?I think this point is over-egged personally, and that humans need to reckon with shifts either way.
- I’ve based some of the above on extrapolating from today’s AI systems, where RLHF focuses predominantly on giving AIs personalities that are HHH(helpful, harmless and honest) and generally good by human (liberal western!) moral standards. To the extent these systems have goals and drives, they seem to be pretty good ones. That falls out of the fine-tuning (RLHF) data.But future systems will probably be different. Internet data is running out, and so a very large fraction of agentic training data for future systems may involve completing tasks in automated environments (e.g. playing games, SWE tasks, AI R&D tasks) with automated reward signals. The reward here will pick out drives that make AIs productive, smart and successful, not just drives that make them HHH. Examples drives:
- having a clear plan for making progressMaking a good amount of progress minute by minuteMaking good use of resourcesWriting well organised codeKeeping track of whether the project is one track to succeedAvoiding doing anything that isn’t strictly necessary for the task at handA keen desire to solve tricky and important problemsAn aversion to the time shown on the clock implying that the task is not on track to finish.
Discuss
