


Proteins, essential molecular machines evolved over billions of years, perform critical life-sustaining functions encoded in their sequences and revealed through their 3D structures. Decoding their functional mechanisms remains a core challenge in biology despite advances in experimental and computational tools. While AlphaFold and similar models have revolutionized structure prediction, the gap between structural knowledge and functional understanding persists, compounded by the exponential growth of unannotated protein sequences. Traditional tools rely on evolutionary similarities, limiting their scope. Emerging protein-language models offer promise, leveraging deep learning to decode protein “language,” but limited, diverse, and context-rich training data constrain their effectiveness.
Researchers from Westlake University and Nankai University developed Evola, an 80-billion-parameter multimodal protein-language model designed to interpret the molecular mechanisms of proteins through natural language dialogue. Evola integrates a protein language model (PLM) as an encoder, an LLM as a decoder, and an alignment module, enabling precise protein function predictions. Trained on an unprecedented dataset of 546 million protein-question-answer pairs and 150 billion tokens, Evola leverages Retrieval-Augmented Generation (RAG) and Direct Preference Optimization (DPO) to enhance response relevance and quality. Evaluated using the novel Instructional Response Space (IRS) framework, Evola provides expert-level insights, advancing proteomics research.
Evola is a multimodal generative model designed to answer functional protein questions. It integrates protein-specific knowledge with LLMs for accurate and context-aware responses. Evola features a frozen protein encoder, a trainable sequence compressor and aligner, and a pre-trained LLM decoder. It employs DPO for fine-tuning based on GPT-scored preferences and RAG to enhance response accuracy using Swiss-Prot and ProTrek datasets. Applications include protein function annotation, enzyme classification, gene ontology, subcellular localization, and disease association. Evola is available in two versions: a 10B-parameter model and an 80B-parameter model still under training.
The study introduces Evola, an advanced 80-billion-parameter multimodal protein-language model designed to interpret protein functions through natural language dialogue. Evola integrates a protein language model as the encoder, a large language model as the decoder, and an intermediate module for compression and alignment. It employs RAG to incorporate external knowledge and DPO to enhance response quality and refine outputs based on preference signals. Evaluation using the IRS framework demonstrates Evola’s capability to generate precise and contextually relevant insights into protein functions, thereby advancing proteomics and functional genomics research.
The results demonstrate that Evola outperforms existing models in protein function prediction and natural language dialogue tasks. Evola was evaluated on diverse datasets and achieved state-of-the-art performance in generating accurate, context-sensitive answers to protein-related questions. Benchmarking with the IRS framework revealed its high precision, interpretability, and response relevance. The qualitative analysis highlighted Evola’s ability to address nuanced functional queries and generate protein annotations comparable to expert-curated knowledge. Additionally, ablation studies confirmed the effectiveness of its training strategies, including retrieval-augmented generation and direct preference optimization, in enhancing response quality and alignment with biological contexts. This establishes Evola as a robust tool for proteomics.
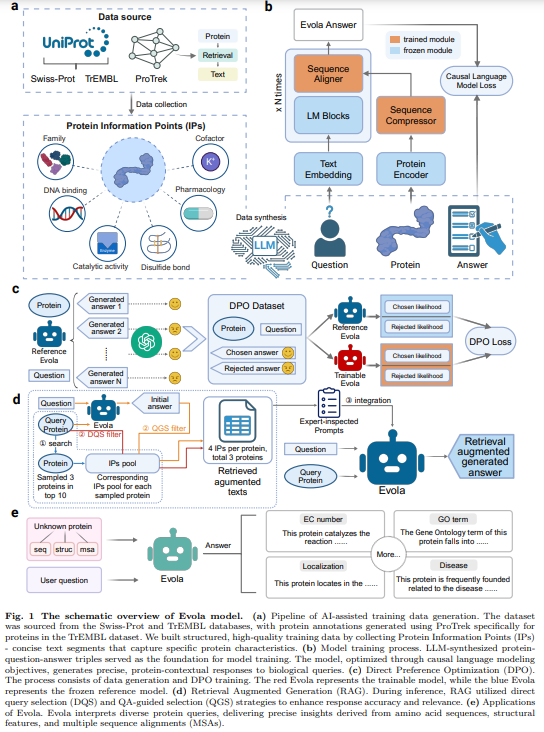
In conclusion, Evola is an 80-billion-parameter generative protein-language model designed to decode the molecular language of proteins. Using natural language dialogue, it bridges protein sequences, structures, and biological functions. Evola’s innovation lies in its training on an AI-synthesized dataset of 546 million protein question-answer pairs, encompassing 150 billion tokens—unprecedented in scale. Employing DPO and RAG it refines response quality and integrates external knowledge. Evaluated using the IRS, Evola delivers expert-level insights, advancing proteomics and functional genomics while offering a powerful tool to unravel the molecular complexity of proteins and their biological roles.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Evola: An 80B-Parameter Multimodal Protein-Language Model for Decoding Protein Functions via Natural Language Dialogue appeared first on MarkTechPost.
