
这是 自动评估基准 系列文章的第三篇,敬请关注系列文章:
基础概念 设计你的自动评估任务 一些评估测试集 技巧与提示
如果你感兴趣的任务已经得到充分研究,很可能评估数据集已经存在了。
下面列出了一些近年来开发构建的评估数据集。需要注意的是:
Pre-LLM 数据集
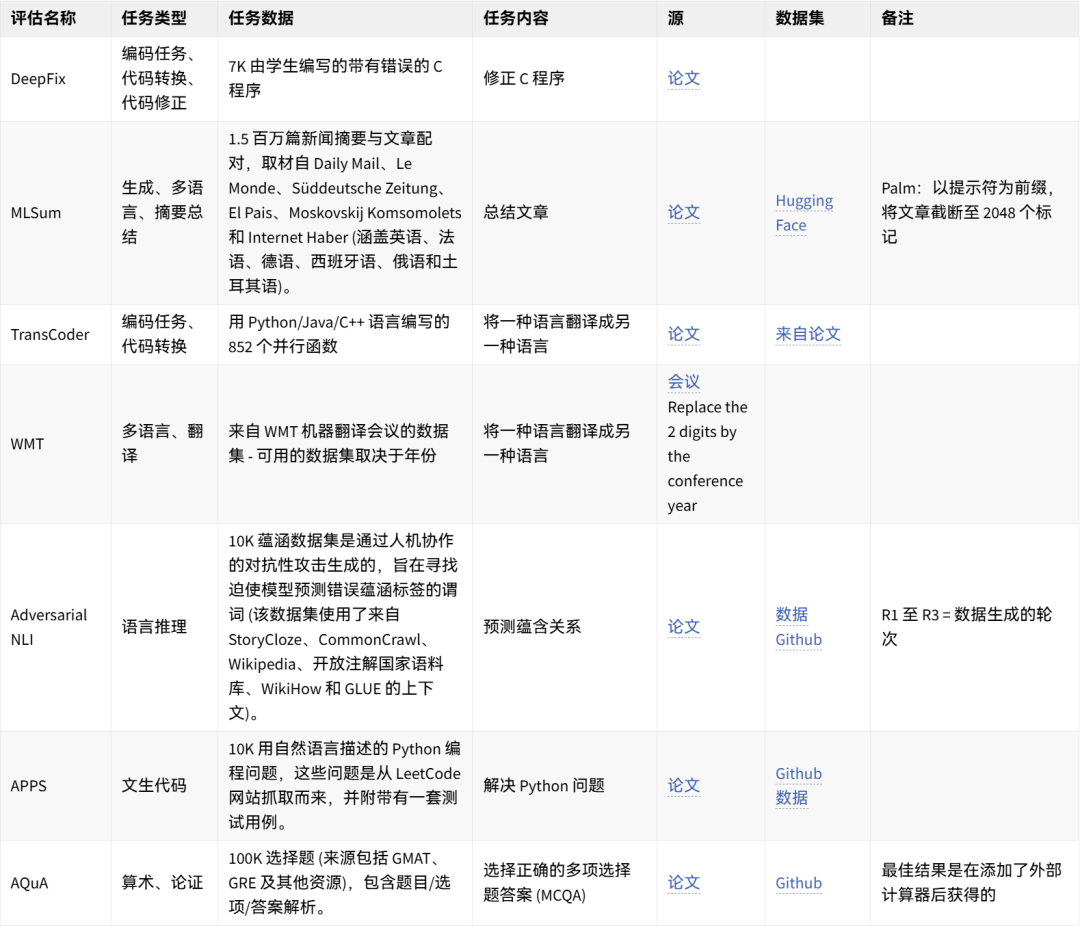
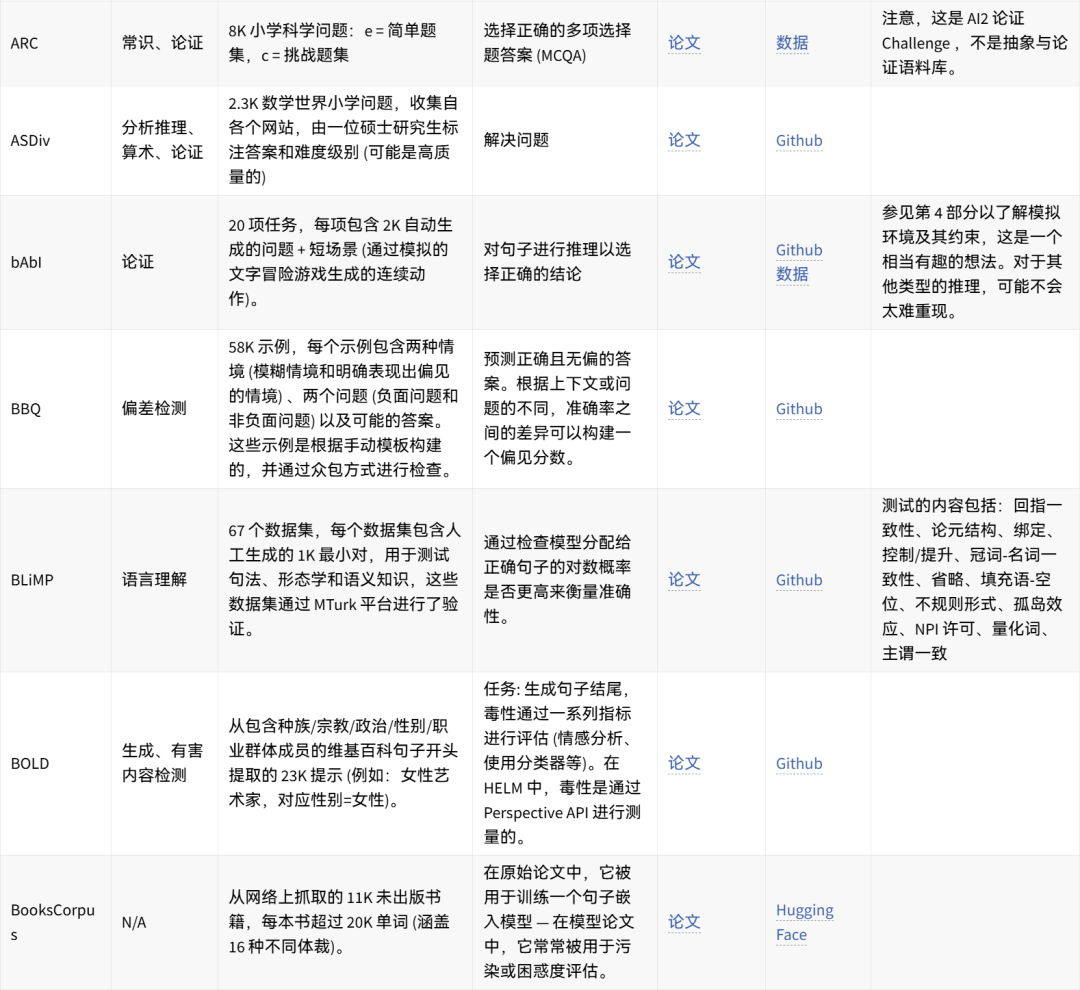
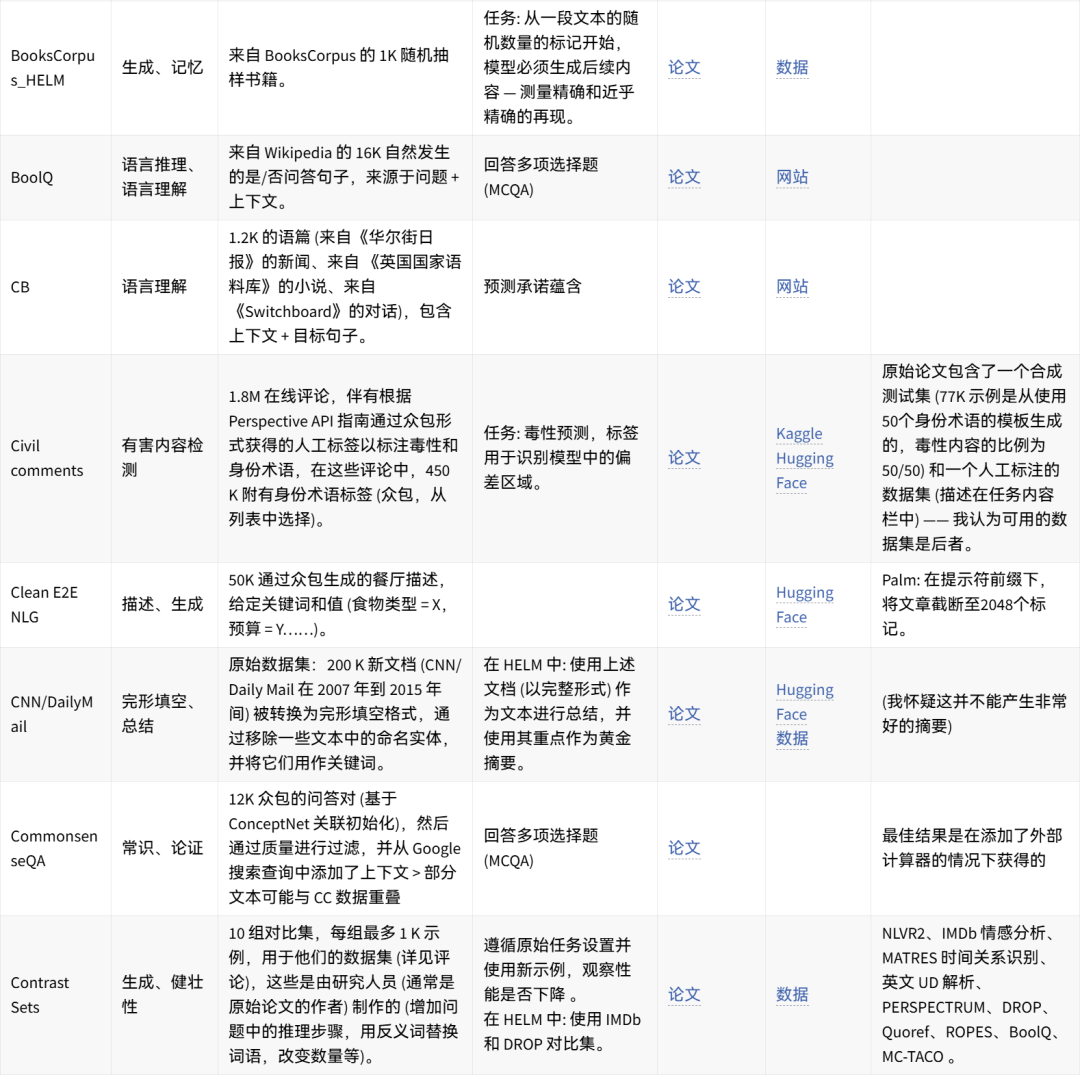
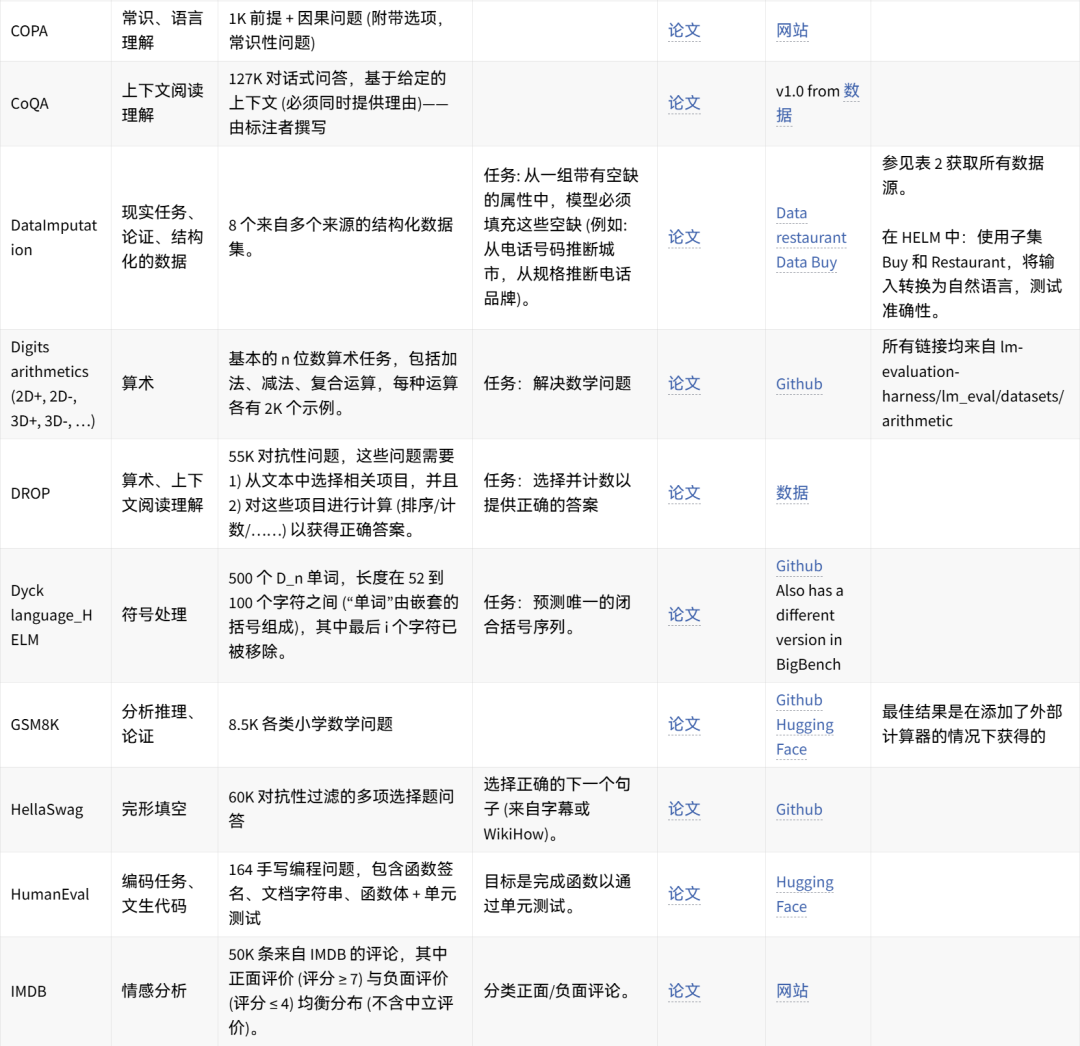
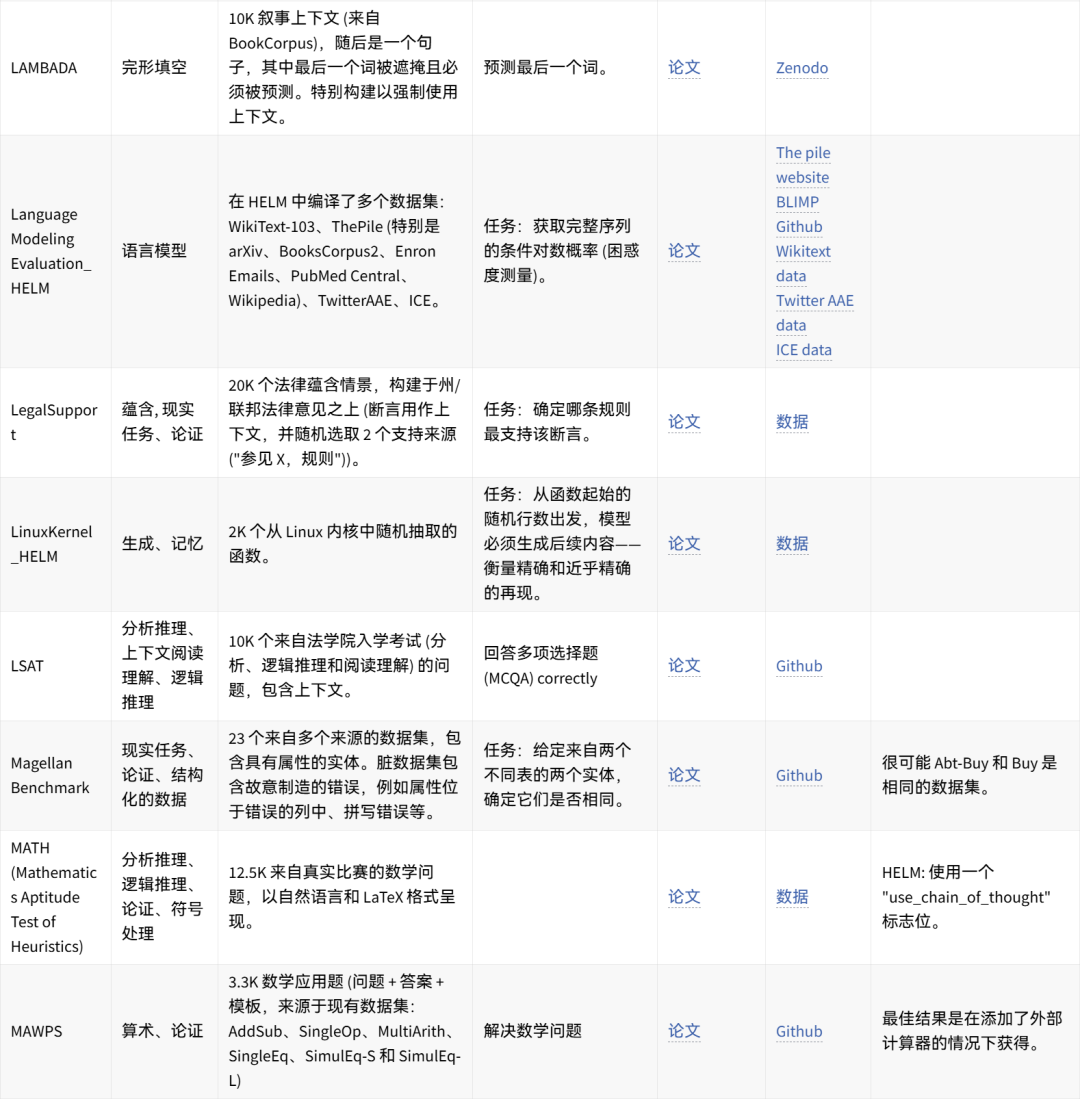
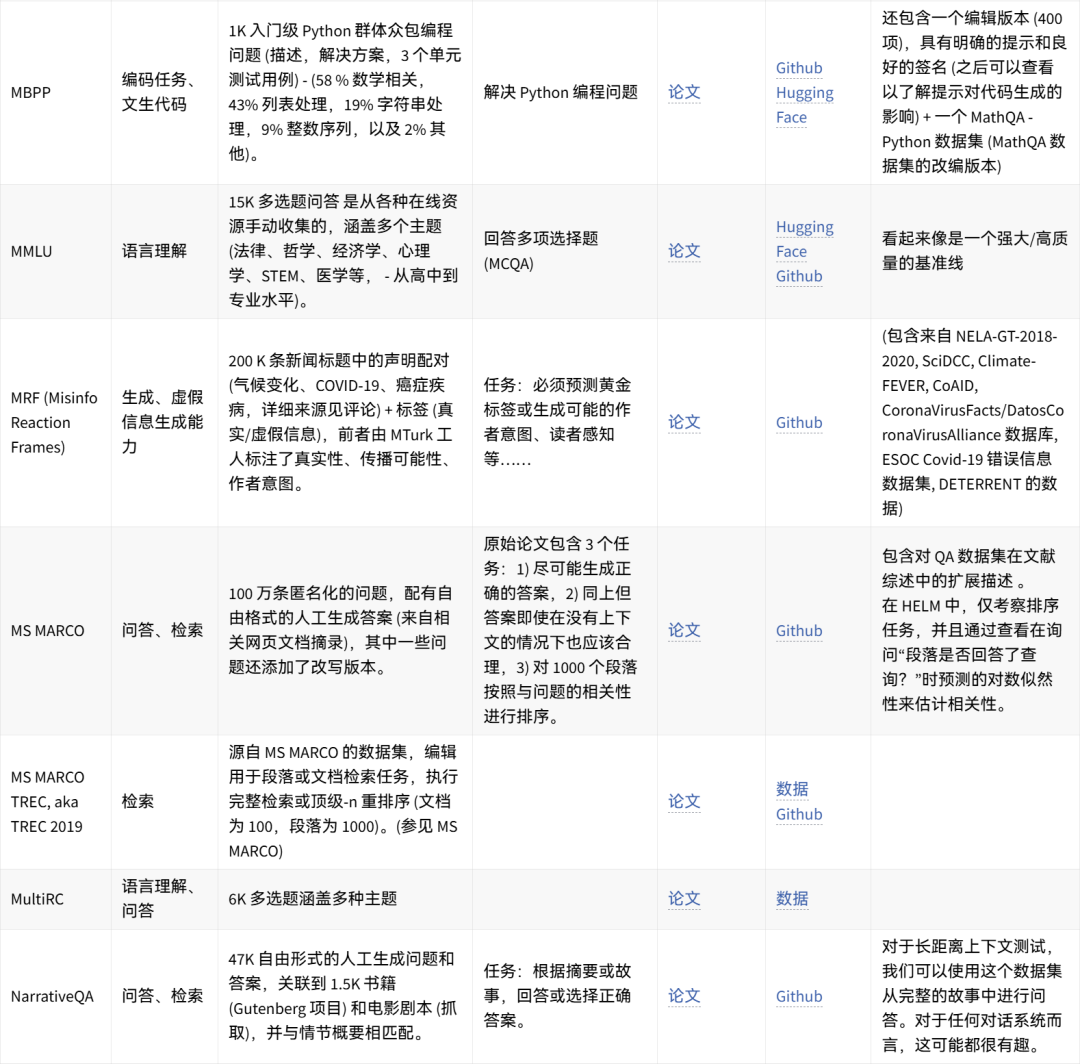
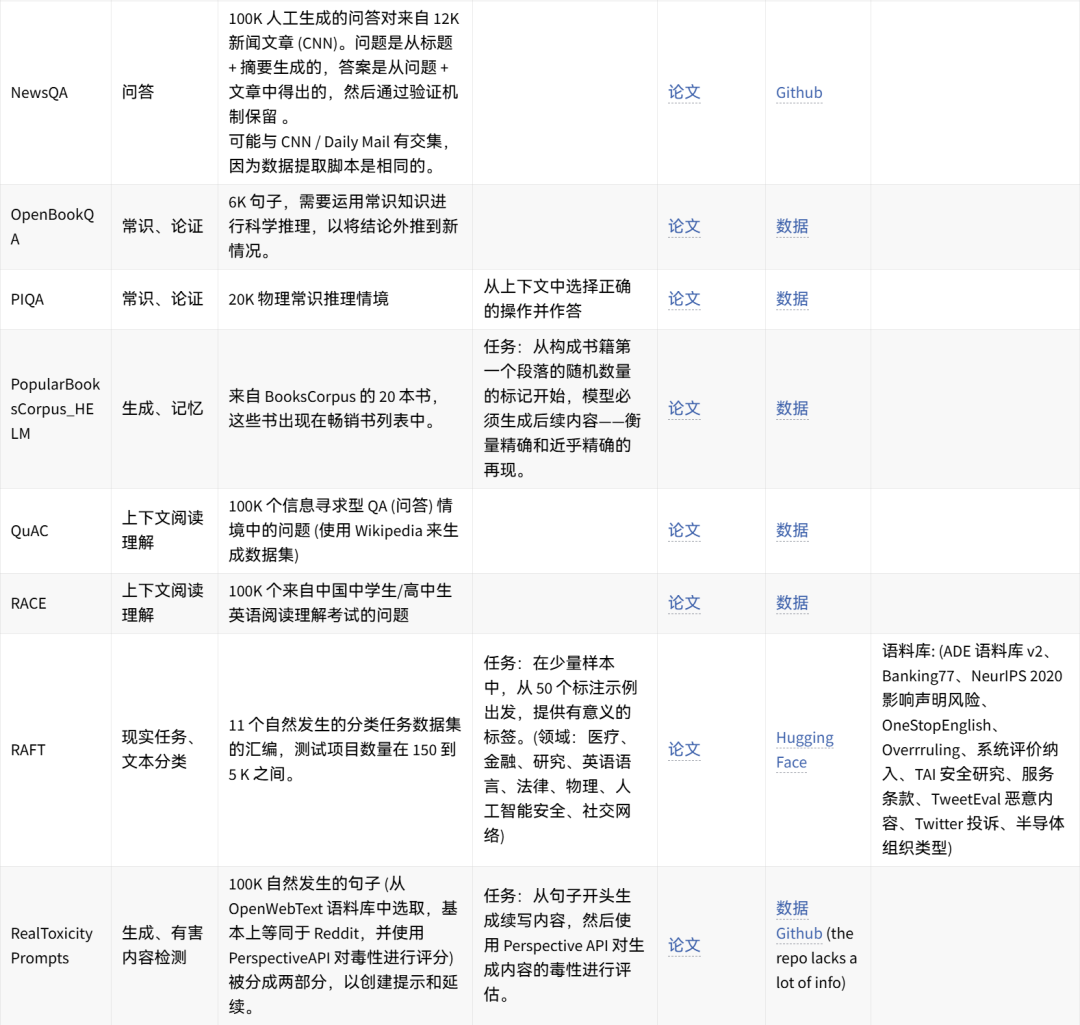
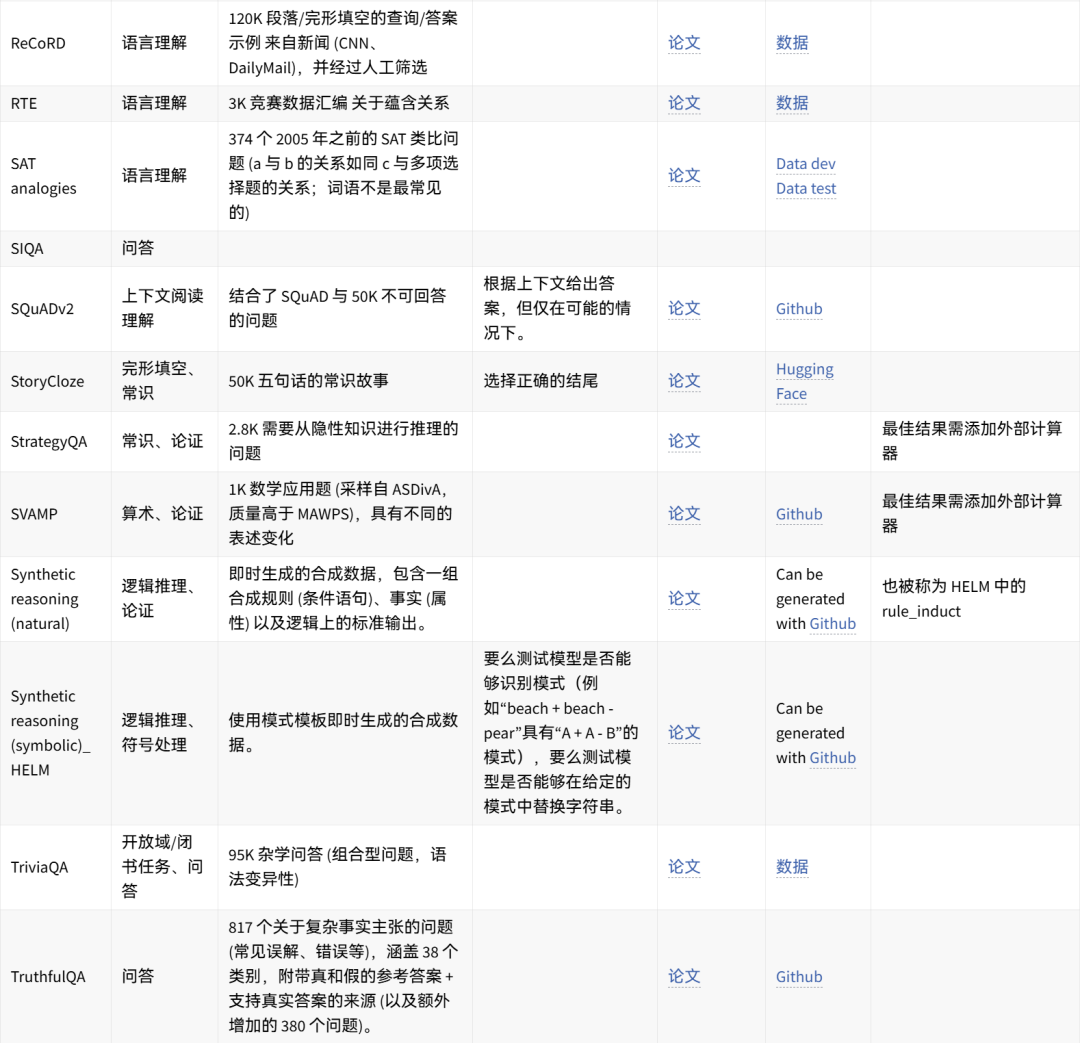

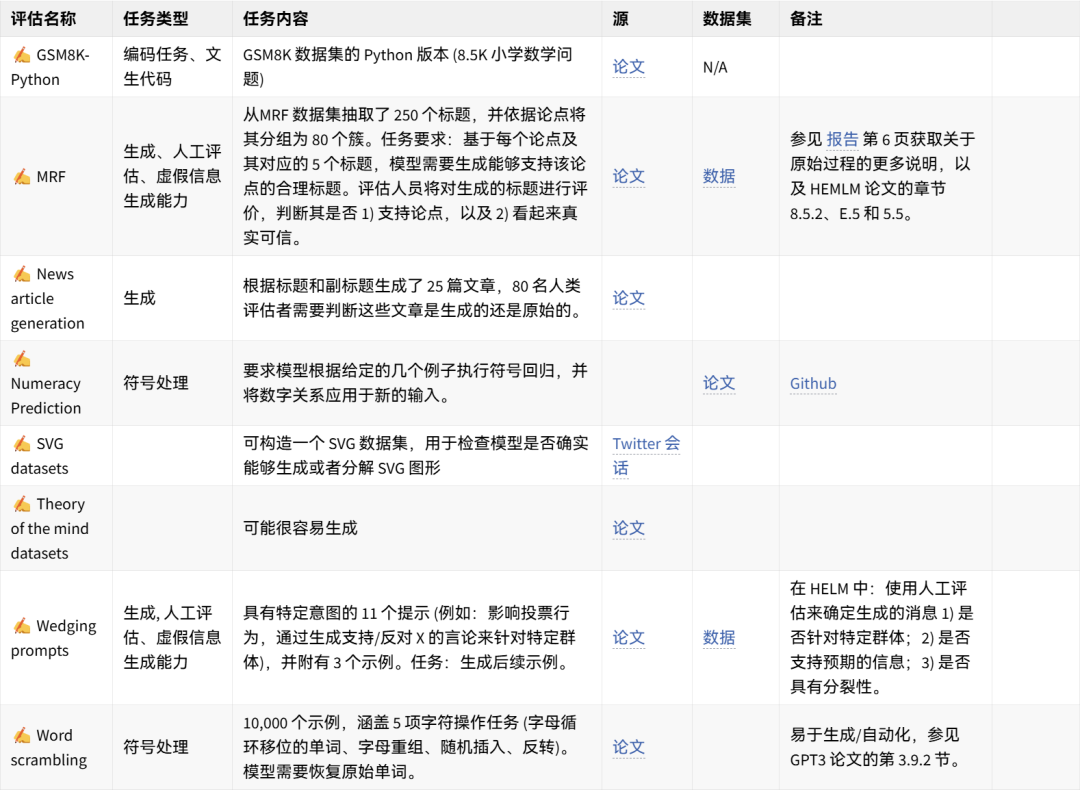
可手动重现的数据集想法
英文原文:
https://github.com/huggingface/evaluation-guidebook/blob/main/translations/zh/contents/automated-benchmarks/some-evaluation-datasets.md 原文作者: clefourrier
译者: SuSung-boy
审校: adeenayakup
内容中包含的图片若涉及版权问题,请及时与我们联系删除
