
Disclaimer: The details in this post have been derived from the Airbnb Technical Blog. All credit for the technical details goes to the Airbnb engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Airbnb's services rely on more than just raw data. They also depend on derived data.
But what is derived data?
It is information computed from massive offline datasets processed by tools like Spark or real-time event streams from systems like Kafka. This derived data is crucial for enabling personalized features, such as tailoring a user’s experience based on activity history and other similar features.
See the diagram below that shows the role of derived data in Airbnb’s overall service architecture.
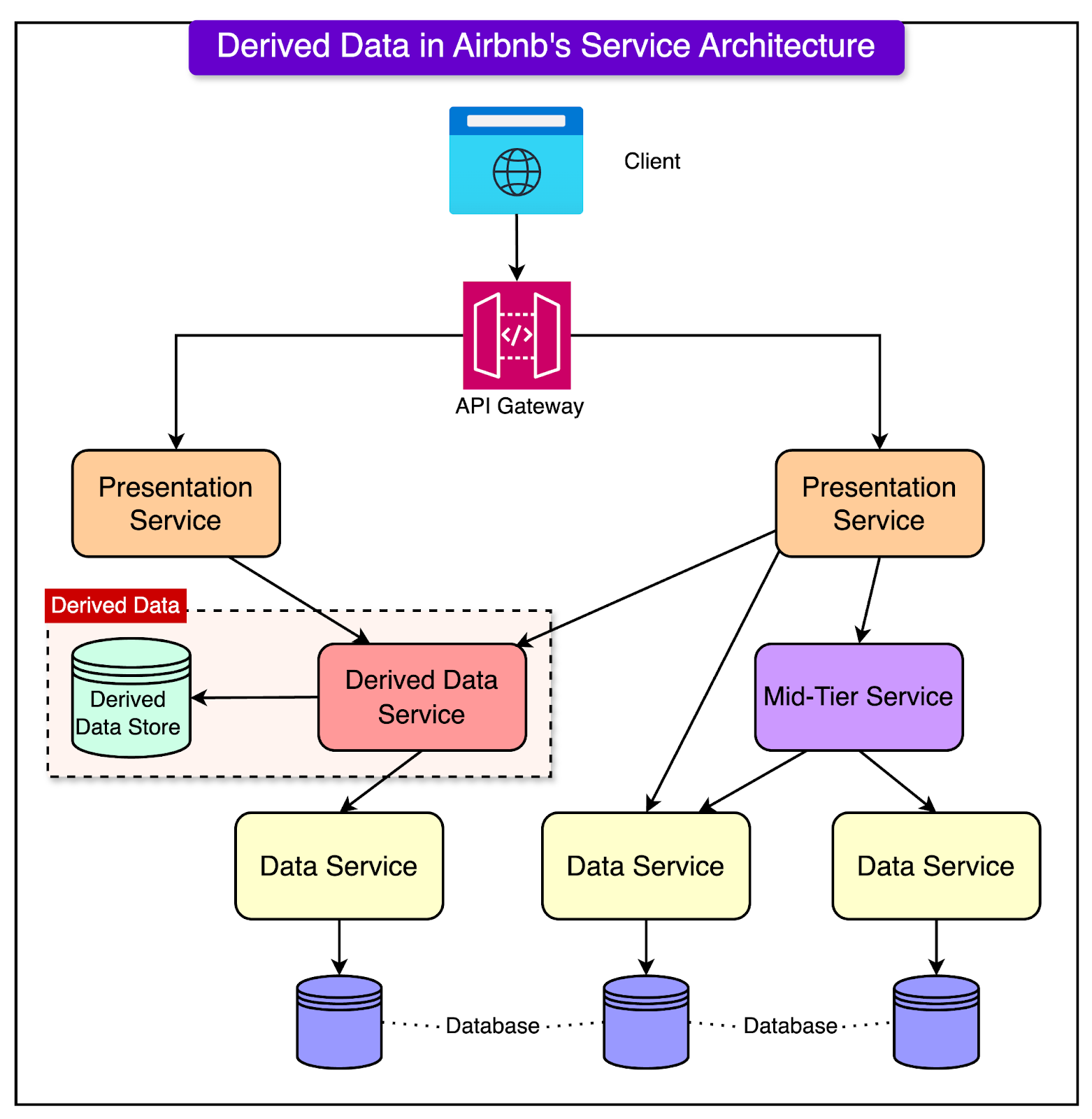
However, accessing this data efficiently poses unique challenges.
The system supporting these services must be exceptionally reliable to ensure uninterrupted functionality.
It must offer high availability so data can be accessed anytime without delays, and it needs to handle scalability, supporting the ever-growing data demands of a platform as large as Airbnb.
Finally, low latency is critical since no one wants to wait while a system lags in fetching information.
This is where Mussel comes in.
Built to meet these stringent requirements, it’s a key-value store designed to ensure Airbnb’s services can retrieve the right data at the right time.
In this article, we’ll understand the architecture of Mussel and learn how Airbnb built this key-value store to manage petabytes of data.
Evolution of Derived Data Storage at Airbnb
Mussel wasn’t the first solution that Airbnb used to store derived data. Before the brand-new key-value store became a reality, there were other solutions implemented by the Airbnb engineering team.
Let’s go through the main stages of this evolution:
Stage 1: Unified Read-Only Key-Value Store
During the early stages of Airbnb's journey to handle derived data effectively, they faced several technical challenges. Existing tools like MySQL, HBase, and RocksDB couldn't meet the demanding requirements such as:
Managing petabytes of data
Allowing fast bulk uploads
Providing low-latency access for quick responses
Supporting multi-tenancy so multiple teams could use the system simultaneously
To address these needs, Airbnb created HFileService in 2015. It was a custom solution built using HFile, which is a building block for HBase and based on Google’s SSTable.
See the diagram below for the architecture of HFileService:
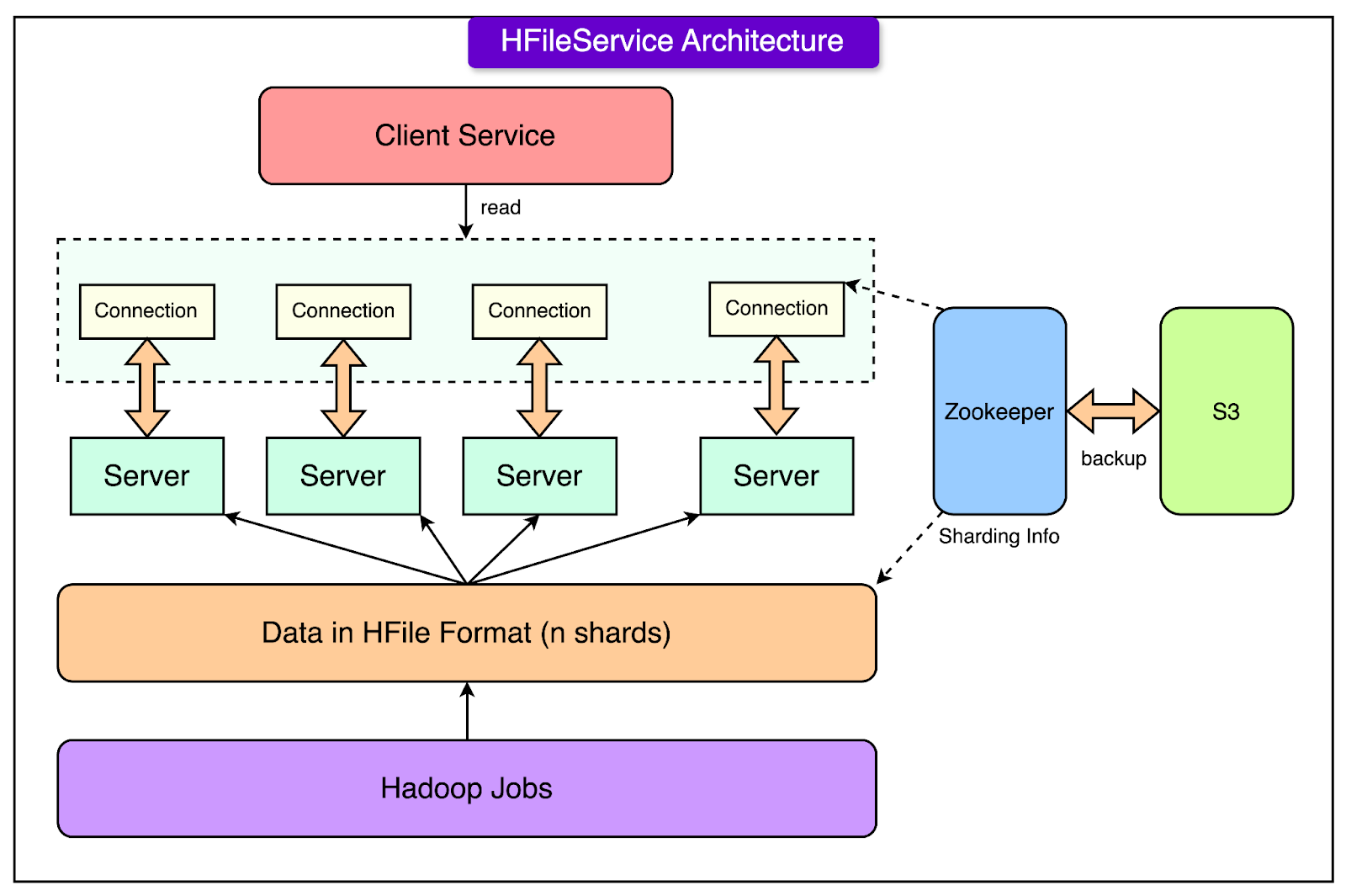
Here's how it worked:
Scalability Through Sharding and Replication:
Data was divided into smaller pieces, or "shards," based on primary keys. This approach spread the data across multiple servers, making the system scalable as data grew.
The number of shards was fixed. Each shard was replicated across multiple servers, ensuring high reliability. If one server failed, others could still serve the data.
Manual Partition Management with Zookeeper:
Zookeeper, a tool for managing distributed systems, was used to keep track of which shards were stored on which servers.
However, this mapping had to be updated manually, making it difficult to scale as data and usage increased.
Daily Batch Updates Using Hadoop:
Data updates were processed offline using Hadoop jobs that ran once daily. These jobs converted raw data into the HFile format, which was then uploaded to cloud storage (S3).
Servers downloaded their assigned shards from S3 and replaced outdated data locally.
While HFileService solved many problems, it had significant limitations:
It only supported read operations, meaning data couldn't be updated in real-time. If new data was added, users had to wait for the next day's batch process to access it.
The reliance on a daily processing cycle made the system less flexible and unsuitable for real-time or rapidly changing data needs.
Stage 2: Real-Time and Derived Data Store (Nebula)
In the second stage of evolution, Airbnb introduced Nebula, a system designed to bridge the gap between batch-processed data and the growing need for real-time data access.
See the diagram below to understand the architecture of Nebula.
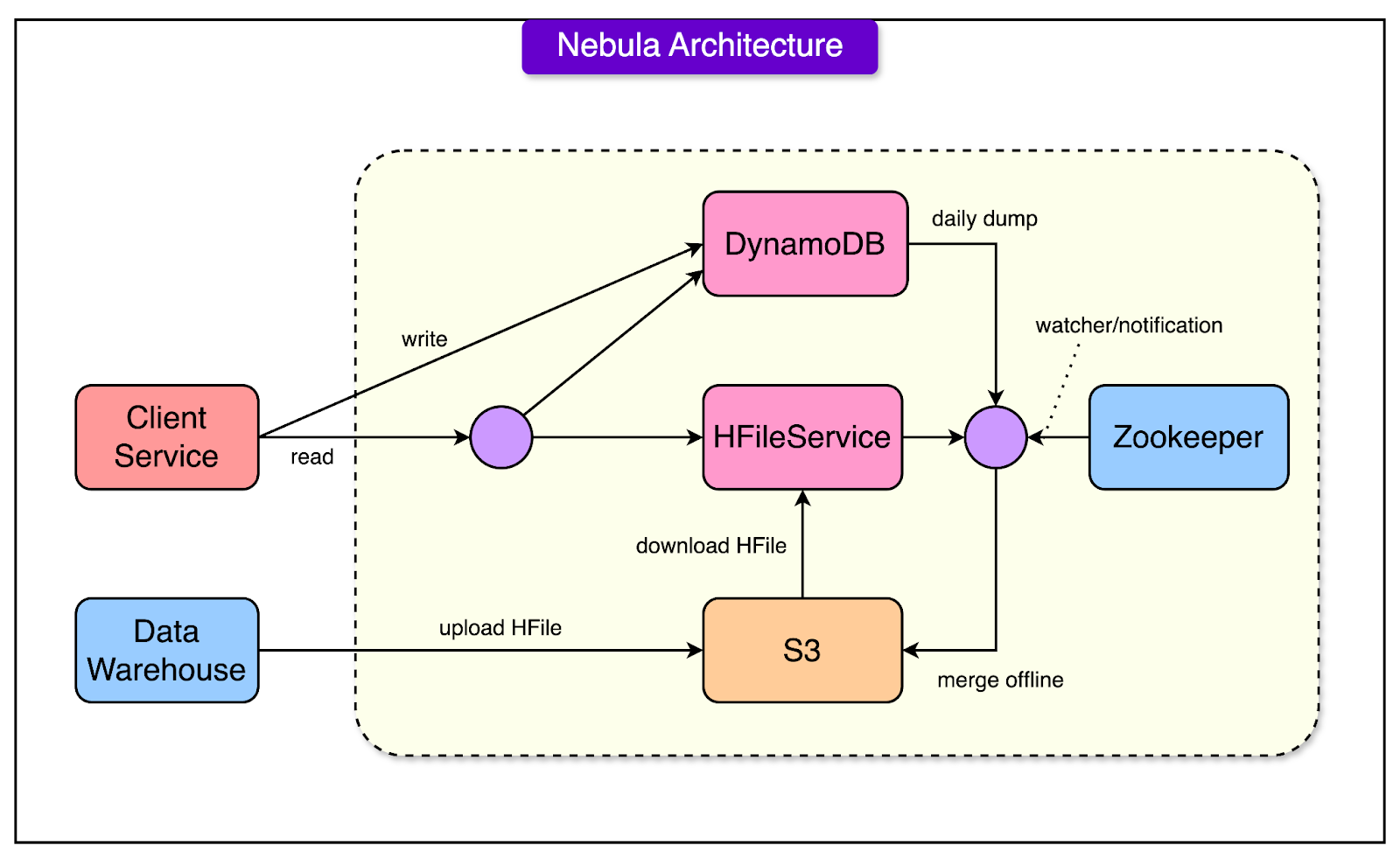
Nebula brought several important enhancements to improve upon the limitations of its predecessor, HFileService.
Combining Batch and Real-Time Data: Nebula used HFileService to handle batch-updated, offline data. For real-time data (like live updates from users or systems), Nebula integrated DynamoDB, a fast, scalable NoSQL database. This dual approach ensured that Nebula could serve static historical data and dynamic, up-to-the-minute information.
Timestamp-Based Versioning: To maintain data consistency, Nebula assigned timestamps to each piece of data. When a query was made, the system merged real-time and offline data based on these timestamps. This ensured that users always received the most recent and accurate data.
Minimize Online Merge Operations: Nebula dynamically merged data from DynamoDB and HFileService for every query to provide latest information. However, merging data from two storage systems during a query added latency, especially for large datasets or high query volumes. To reduce the burden of online merge operations, Nebula introduced daily spark jobs. These jobs pre-merged real-time updates from DynamoDB with the batch snapshot from HFileService, producing a unified dataset.
Despite the advantages, Nebula also had some limitations such as:
High Maintenance Overhead: Nebula required managing two separate systems: DynamoDB for real-time data and HFileService for batch data. This dual-system approach added complexity, as both systems needed to be kept in sync and operated efficiently.
Inefficient Merging Process: The daily merging job using Spark became slow and resource-intensive as the data grew. For example, even if only 1–2% of the data had changed in DynamoDB, Nebula reprocessed and published the entire dataset from HFileService daily.
Scalability Challenges: As Airbnb's data grew, scaling Nebula to handle increasing traffic and larger datasets became cumbersome, particularly with the manual maintenance and heavy processing requirements.
Mussel Architecture
In 2018 the Airbnb engineering team built a new key-value store called Mussel.
The architecture of Mussel was designed to address the scalability and performance limitations of previous solutions.
See the diagram below that shows the architecture of Mussel:
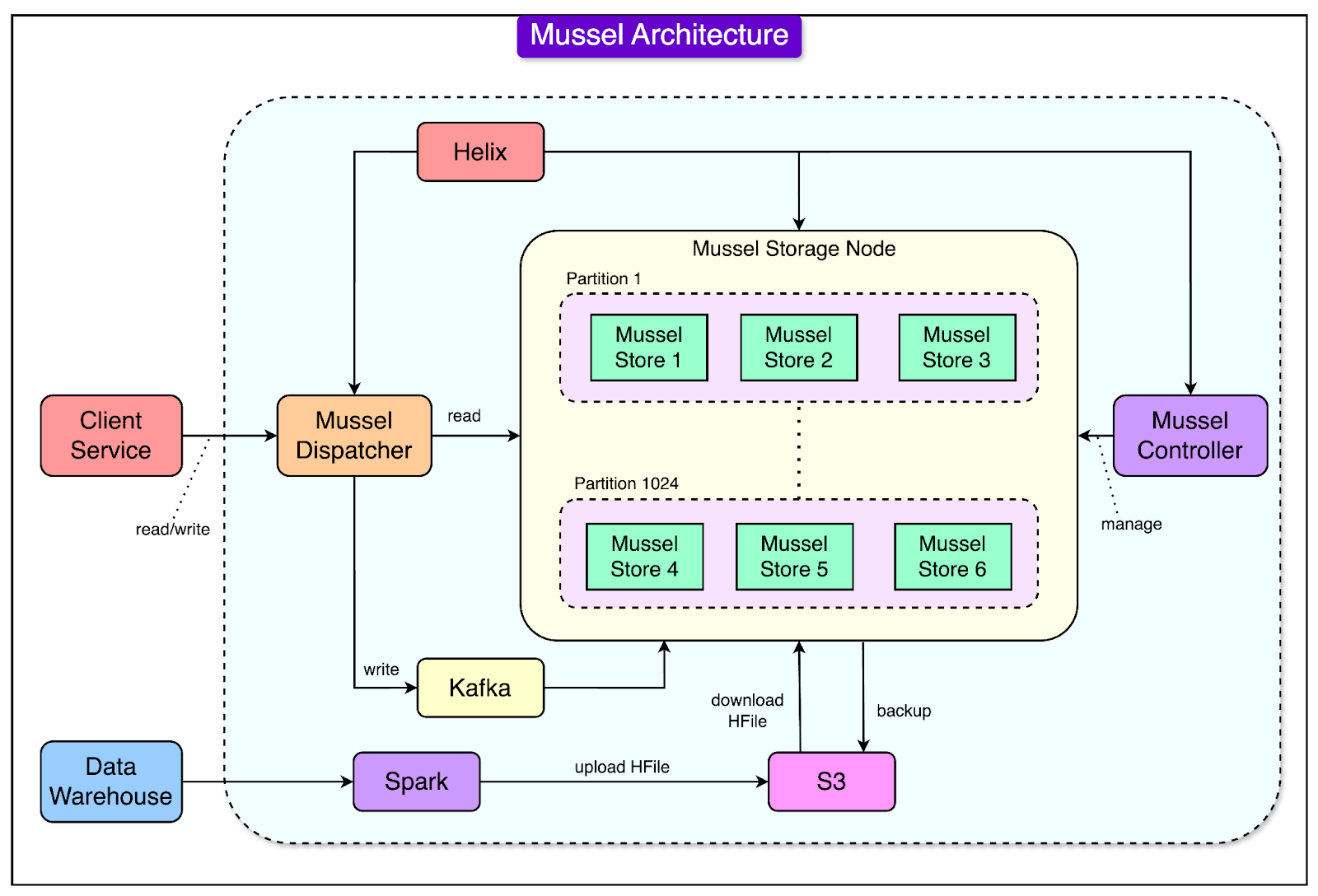
Let’s look at each feature of Mussel’s architecture in more detail:
Partition Management with Apache Helix
Mussel increased the number of shards (data partitions) from 8 to 1024 to support Airbnb’s expanding data needs. These shards are smaller subsets of data distributed across multiple servers, ensuring that no single server is overwhelmed by too much data.
The data was partitioned into those shards by the hash of the primary keys. They used Apache Helix to automate the management of these shards. It determined which physical servers stored each shard and balanced the load dynamically.
This removed the need for manual intervention, making the system more efficient and scalable.
Leaderless Replication with Kafka
Mussel used Kafka as a write-ahead log for every write operation.
Kafka divided the log into 1024 partitions, aligning with the shard structure in Mussel so that each shard’s data was processed in order. This ensured that all updates were recorded and replicated consistently.
Mussel also followed a leaderless replication approach.
Unlike systems with a designated “leader” node for each shard, Mussel allowed any node holding a shard replica to handle read requests. Write operations, however, synchronized across nodes using Kafka logs to maintain consistency.
This design smoothed out spikes in write traffic and prioritized high availability for read-heavy workloads common at Airbnb. The data was eventually consistent, but it was acceptable for the derived data use cases.
Unified Storage Engine with HRegion
Mussel replaced DynamoDB, simplifying the architecture by extending HFileService to handle real-time and batch data in a unified system.
Instead of HFile, Mussel used HRegion, a component of HBase, as its key-value storage engine. This was because HRegion offered:
LSM Tree (Log-Structured Merge Tree) to organize data efficiently.
MemStore for temporary in-memory storage of writes.
BlockCache to speed up reads by caching frequently accessed data.
In HRegion, each client table was mapped to a column family. This grouped related data logically and helped Mussel support advanced queries such as:
Point queries to fetch specific records by primary key.
Range queries to retrieve data over a range of keys.
Time-range queries to access data within a timeframe.
Over time, HRegion created multiple small files from writes and deleted or expired data. To optimize performance, these files needed to be merged using a process called compaction.
Mussel divided its nodes into:
Online nodes: Handled read requests and limited compaction activity to ensure good performance.
Batch nodes: Focused on full-speed compaction.
Helix managed scheduled rotations between these node types, ensuring the system maintained high read availability and efficient compaction.
Bulk Load Support
They supported two types of bulk load pipelines from the data warehouse to Mussel via Airflow jobs:
Merge Type: Involves merging the data from the data warehouse and the data from the previous write with older timestamps in Mussel.
Replace Type: Involves importing the data from the data warehouse and deleting all data with previous timestamps.
Mussel used Spark to process data from Airbnb’s data warehouse, converting it into HFile format. These files were uploaded to S3 (cloud storage), where each Mussel storage node downloaded and loaded them into HRegion using the bulk loading API.
Instead of reloading the entire dataset daily, Mussel loaded only the incremental changes (delta data). This reduced the daily data load from 4TB to just 40–80GB, significantly improving efficiency and reducing operational costs.
Adoption and Performance of Mussel
Mussel has become a core component of Airbnb’s data infrastructure, supporting a wide range of services that rely on key-value storage. It serves as the backbone for applications requiring reliable, low-latency access to derived data.
Some performance metrics regarding Mussel are as follows:
Mussel manages approximately 130TB of data across 4,000 tables in its production environment.
With a >99.9% availability rate, Mussel ensures that its services experience minimal downtime, providing a consistent and reliable user experience.
Mussel handles an impressive read query rate of over 800,000 QPS, making it highly suitable for read-heavy workloads.
It also supports 35,000 write QPS, showcasing its capacity to process real-time updates alongside bulk data loads.
The system achieves an average P95 read latency of less than 8 milliseconds, meaning 95% of read operations are complete in under 8ms.
Conclusion
Mussel demonstrates the evolution of a robust key-value store, addressing critical challenges like scalability, low latency, and operational complexity.
Its impressive metrics and widespread adoption within Airbnb demonstrate how it has become a critical enabler for high-performance data-driven services.
Mussel serves Airbnb’s current use case quite well. However, the Airbnb engineering team is also committed to enhancing Mussel to support use cases such as read-after-write consistency, auto-scaling, and traffic-based repartitioning.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
