


GUI agents face three critical challenges in professional environments: (1) the greater complexity of professional applications compared to general-use software, requiring detailed comprehension of intricate layouts; (2) the higher resolution of professional tools, resulting in smaller target sizes and reduced grounding accuracy; and (3) the reliance on additional tools and documents, adding complexity to workflows. These challenges highlight the need for advanced benchmarks and solutions to enhance GUI agent performance in these demanding scenarios.
Current GUI grounding models and benchmarks are insufficient to fulfill professional environment requirements. Tools like ScreenSpot are designed for low-resolution tasks and lack the variety to simulate real-world scenarios accurately. Models such as OS-Atlas and UGround are computationally inefficient and fail when the targets are small or the interface is icon-rich, which is common in professional applications. In addition, the absence of multilingual support reduces their applicability in global workflows. These shortcomings highlight the need for more comprehensive and realistic benchmarks to further this field.
A team of researchers from the National University of Singapore, East China Normal University, and Hong Kong Baptist University introduce ScreenSpot-Pro: a new framework that is tailored to professional high-resolution environments. This benchmark has a dataset of 1,581 tasks across 23 applications in industries such as development, creative tools, CAD, scientific platforms, and office suites. It incorporates high-resolution, full-screen visuals and expert annotations that ensure accuracy and realism. Multilingual guidelines encompass both English and Chinese for an expanded range of evaluation. ScreenSpot-Pro is unique as it documents the actual workflows that result in real, high-quality annotations, therefore serving as a tool for the full assessment and development of GUI grounding models.
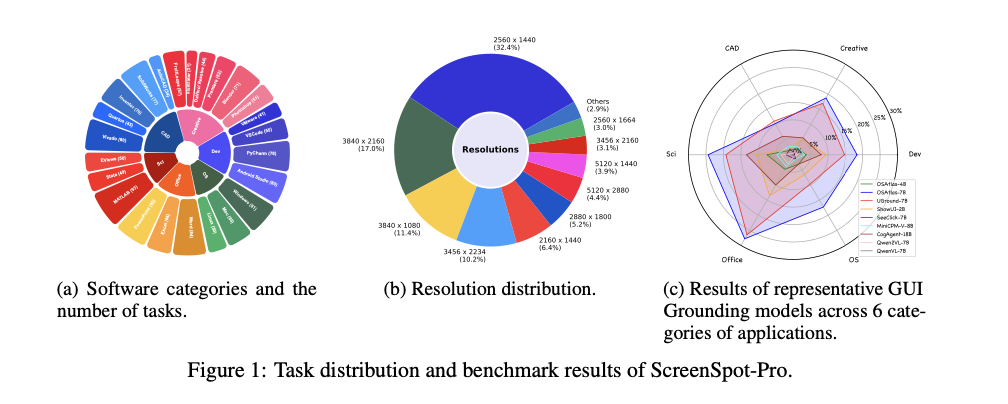

The dataset ScreenSpot-Pro captures realistic and challenging scenarios. The base of this dataset is formed by high-resolution images, where the target regions form an average of only 0.07% of the total screen, thus pointing to subtle and small GUI elements. Data was collected by professional users with experience in relevant applications, who used specialized tools to ensure accurate annotations. Additionally, the dataset supports multilingual capabilities to test bilingual functionality and contains several workflows to capture the subtleties of real professional tasks. These characteristics render it particularly advantageous for the assessment and enhancement of the accuracy and flexibility of GUI agents.
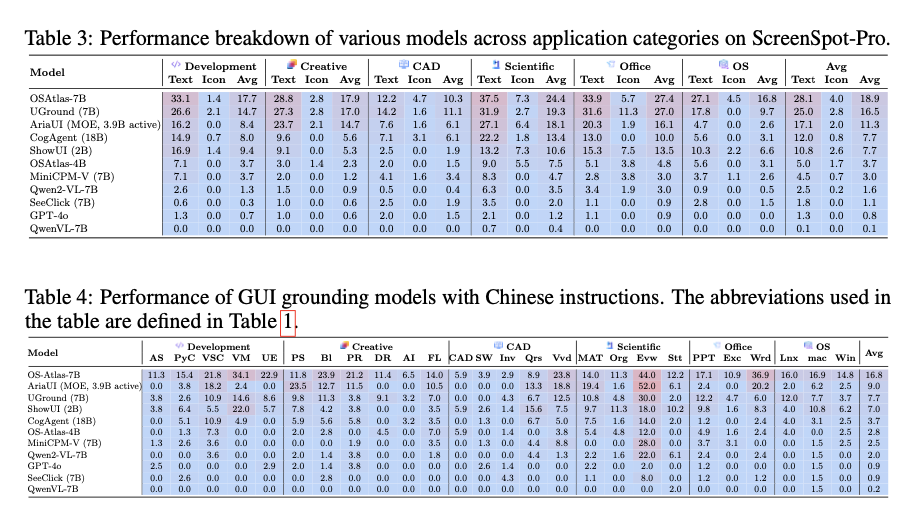
The analysis of current GUI grounding models utilizing ScreenSpot-Pro reveals considerable deficiencies in their capacity to manage high-resolution professional settings. OS-Atlas-7B attained the greatest accuracy rate of 18.9%. However, iterative methodologies, exemplified by ReGround, demonstrated the capacity to enhance performance, reaching an accuracy of 40.2% by fine-tuning predictions through a multi-step methodology. Minor components, such as icons, presented significant difficulties, whereas bilingual assignments further highlighted the limitations of the models. These findings emphasize the necessity for improved techniques that bolster contextual comprehension and resilience in intricate GUI situations.
ScreenSpot-Pro sets a transformative benchmark for the evaluation of GUI agents in professional high-resolution environments. It addresses the specific challenges in complex workflows, offering a diverse and precise dataset to guide innovations in GUI grounding. This contribution forms the foundation of much smarter and more efficient agents that support a seamless performance of professional tasks, significantly boosting productivity and innovation in all industry fields.
Check out the Paper and Data. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post ScreenSpot-Pro: The First Benchmark Driving Multi-Modal LLMs into High-Resolution Professional GUI-Agent and Computer-Use Environments appeared first on MarkTechPost.
