
Published on January 4, 2025 6:19 PM GMT
The Turing Test has long been regarded as the standard for evaluating whether a machine is intelligent. Even now, artificial intelligence researchers continue to aim for this subjective benchmark as the purpose of their studies. However, this standard overlooks a crucial factor -- efficiency. While AI has made significant progress as a useful tool, this oversight may have led to a fundamentally misguided direction in its development. Current advancements are merely superficial, driven by improvements in computational power, rather than truly bringing us closer to the essence of intelligence. This article aims to highlight these directional differences by analyzing the fundamental distinctions between human intelligence and machine learning technologies.
In 1950, Turing proposed the famous Turing Test as a standard for measuring whether a machine possesses intelligence. Generally speaking, if one wants to measure whether a machine has intelligence, one must first start with the definition of intelligence. However, doing so would lead to endless debates about the definition of intelligence, such as delving into the even more elusive question of whether intelligence requires consciousness. " Therefore, Turing hoped to bypass the step of 'defining intelligence' and directly address the question of whether a machine possesses intelligence through its functions as perceived by humans. This is how the Turing Test came about.
The core of the Turing Test is to judge whether a machine can behave like a human in conversation through a question-and-answer session. The main steps are as follows:
1) Test Setup
In a closed environment, three parties are arranged to participate:
- A human tester (judge).A machine (subject).A human participant (comparator).
The tester cannot see the machine or the human participant, and all communication takes place in text form (such as through a computer terminal) to avoid non-linguistic features like voice or appearance from influencing the judgment.
2) Question and Answer Exchange
The tester asks questions (on any topic) to both the machine and the human participant, who respond separately. The tester tries to determine which is the human and which is the machine based on their answers.
3) Judgment Results
If a machine can deceive the tester for a sufficient length of time, making it impossible to reliably distinguish the machine from the human (for example, the tester's accuracy approaches random chance), then the machine is considered to have passed the Turing Test.
The Turing Test emphasizes whether a machine can exhibit human-like thinking abilities, rather than focusing on whether the machine possesses the same internal cognitive mechanisms as humans. Since its proposal, it has become a core objective for AI researchers to pursue. Even today, although this goal has given rise to many different variations, they all use the degree of ability to imitate humans as a standard for measuring intelligence. The most advanced artificial technologies today, such as large language models, intelligent robots, and self-driving cars, are all encompassed within this scope.
What we want to propose in this article is that the Turing Test may have overlooked a very important factor of intelligence. As a result, the direction of artificial intelligence development aimed at the Turing Test goal still has a significant difference from the path toward true human-like intelligence. The key factor neglected by the Turing Test is the ability to learn or, more precisely, learning efficiency.
According to the definition of the Turing Test, it is not difficult to see that for a machine, no matter what method it uses for learning, as long as it can achieve the goal of "feeling like a human," it is sufficient. The cost required for acquiring the functions behind this is not a concern. However, for any organism in nature that has the ability to survive, cost is a crucial factor. Because external resources are limited, if a function requires a large amount of cost, then even if it evolves, the organism will likely die before it can utilize this function. This means the function would be essentially useless and goes against the direction of biological evolution.
Some might argue that the Turing Test does not ignore learning efficiency because we can have the machine learn new knowledge during the conversation and evaluate its ability to learn like humans. However, this method is impractical. Take current large language models as an example: if a tester poses a question they consider new, is it truly new for the large language model? The training dataset of a large language model is vast; it's highly probable that someone has already asked a similar question and provided a solution. Therefore, what is a new question to the tester might not be new to the large language model. This fails to achieve the desired effect of testing intelligence. In other words, if we do not know exactly what sample data has been used to train a model, we cannot evaluate its learning efficiency.
We can see that the training data of current data-driven AI is very vast. For example, the training data used by current large language models is enormous. Facebook's Llama 3 was trained on 15 trillion tokens. In contrast, the total number of words read by a person growing up to 20 years old is generally around 30 million. That's a difference of 500,000 times.
Some mainstream AI researchers might counter our comparison. They have two main arguments. One view is that humans have a lot of information from the past stored in their genes. Therefore, it's not just one generation's accumulation but rather the accumulation of all past generations. For this viewpoint, let's put aside for now whether it's biologically feasible (can genes transmit ancestor's knowledge?), and even if we only consider the difference in scale, if we take 20 years as a generation, the accumulation of 1,000 generations would require 20,000 years. This already far exceeds the earliest civilization of Homo sapiens (which appeared approximately 3,000 years ago). However, there is still a 500-fold difference.
Another argument claims that humans primarily acquire information through vision rather than text. Firstly, this viewpoint still faces the challenge of scale. Does textual information acquisition truly account for only 1/500th of a normal person's total information intake? Omitting this 1/500th seems inconsequential, but this is not the case. The amount one reads significantly impacts their abilities. Moreover, even people born blind do not experience diminished reasoning abilities due to the lack of visual capacity. Yet, this reasoning ability is something current large language models still lack. There are already numerous publications demonstrating this, such as the paper "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models" from Apple's research team.
To truly understand intelligence (if we consider human-like intelligence as true intelligence), we should return to the environment where intelligence originated and examine what is necessary for an intelligent being to survive in this environment. This survival imperative is the driving force behind the birth of intelligence.
I. Exploring the Essence of Intelligence
In past research on intelligence, researchers have heavily emphasized that intelligent agents must understand the world around them and consider building a world model as a key characteristic of intelligence. Certainly, comprehending the patterns of the surrounding environment is crucial for biological organisms to survive in nature. However, another equally important point has been neglected by mainstream AI researchers: understanding the intelligent agent itself. An intelligent agent needs to understand not only its environment but also itself.
In nature, a creature's ability to understand itself is crucial for survival because survival depends on action, and action fundamentally involves the interaction between the creature itself and its external environment. In this interplay, a creature can only make effective decisions if it has a clear understanding of its own state and capabilities, thus enabling it to acquire resources, avoid danger, and fulfill its survival needs.
For example, when hunting, a lion needs to accurately assess its own physical strength and speed. If the lion fails to recognize that it is overly hungry or exhausted and rashly chases a very fast prey, it may waste precious energy and struggle to make a successful kill, ultimately threatening its survival. Similarly, if the lion underestimates its abilities, it might forgo some prey that it could actually capture, resulting in a missed food source. A clear understanding of its own state is crucial for the lion's successful actions and acquisition of food.
Therefore, a creature's ability to understand itself is an adaptive advantage. Only by fully assessing its own state and capabilities can a creature effectively interact with its external environment and take actions that are adapted to its surroundings, which is crucial for survival and reproduction.
Is self-understanding innate or acquired?
If biological organisms need to understand themselves, is this knowledge in their DNA, or is it something learned through experience? In comparison, learning about oneself later through experience offers a clear advantage as it allows organisms to flexibly adapt to environmental and internal changes and maximize their potential.
Firstly, learning through experience grants organisms a versatile understanding of themselves. If a body evolves new functions, such learning enables these new functions to quickly integrate and work in concert with existing bodily components. For example, humans learn to manipulate various tools using their hands, utilizing both the fine motor skills of their fingers and the coordinated abilities of vision and the brain. If reliance were solely on innate, fixed mechanisms, such complex functional integration might be difficult to achieve. It would be like adding new hardware to a computer without the necessary drivers – the functionality could go unused.
Secondly, an organism's capabilities change over time, and learning through experience allows organisms to adjust their assessments of their abilities and how they utilize them in real-time. For example, an aging cheetah whose speed has diminished can learn ambush tactics instead of relying on high-speed pursuits, thus continuing to hunt successfully. If this understanding were solely determined by DNA, it might struggle to flexibly adapt to the decline in ability, potentially leading to survival difficulties.
Moreover, learning through experience bestows upon organisms a unique adaptability: the ability to view tools as extensions of the body. For example, humans can skillfully incorporate hammers, shovels, and even modern technological devices into their daily lives. This effectively integrates external tools with inherent abilities, expanding the range of bodily functions. Such adaptability significantly enhances an organism's survival and competitiveness, while complete reliance on innate modes would struggle to achieve such complex integration of external functionality.
By learning through experience, organisms can not only fully understand and utilize themselves but also adapt to environmental changes, adjust strategies, and even create new advantages. These characteristics suggest that an organism's understanding of itself is likely primarily from learning through experience rather than innate DNA.
If we accept that organisms primarily learn to understand their own capabilities through experiences, then this question becomes equally vital for the study of intelligence. However, research on this topic is scarce in mainstream artificial intelligence. Even if we broaden our scope to encompass all fields related to intelligence, such as philosophy and cognitive science, while there are indeed some studies on how humans develop self-awareness, such as metacognition theory and self-concept theory, these theories share a common limitation: they all rely on specific processes to form self-knowledge.
For example, in self-concept theory, individuals need to reflect to build a model of themselves. In this case, the process of reflection becomes a prerequisite for establishing a self-concept. If this theory were to be implemented as software, a reflection program would have to be manually hard-coded into the system.
Theoretically, this approach still relies on a predetermined reflection program. From a practical standpoint in artificial intelligence, this line of thinking essentially reverts to the outdated expert system model. The expert system approach has been proven by the history of AI development to be a flawed direction. This is because manually written programs will inevitably encounter coordination issues, and these problems will grow catastrophically as the system's scale increases.
Based on past experiences in the development of artificial intelligence, solving the catastrophic problem of coordination between modules requires finding a universal principle to handle various types of problems, much like the current data-driven machine learning. Furthermore, it needs to go beyond the current data-driven machine learning, as this principle must also allow for the simultaneous development of models about the world and models about oneself. This seems to be an exceedingly challenging task. However, unexpectedly, this principle is remarkably simple. In fact, it doesn't even require the complex maximization calculations involved in machine learning. It is just repetitiveness, or more accurately, repetitiveness based on perception. In the next, we will demonstrate why we believe this kind of repetitiveness is sufficient to produce true intelligence by answering the following three questions:
1) What is perception that we are referring to?
2) What is the scope on which perception can operate?
3) How does the repetitiveness of perception give rise to rationality?
What is perception?
The mainstream cognitive science community generally holds that perception is the result of an integration of multiple processes. Perception is typically divided into several stages including sensoring, processing, and interpretation. For example, in theories of visual perception, it includes processes such as light sensoring, the preliminary extraction of features (e.g., edges, colors, etc.), and higher-level semantic understanding (e.g., object recognition or contextual judgment). These theories suggest that perception is accomplished through the collaborative operation of multiple modular processes, with each process playing an irreplaceable role at different levels of perception.
However, is this multi-process model truly necessary? If we consider how convolutional neural networks (CNNs) recognize images, we find that in neural networks, the sensation of low-level features like edges and high-level perception like object recognition are not separate processes but are directly achieved through a single "abstraction-combination" process. In this framework, perception does not rely on explicit hierarchical steps, and this approach has already achieved outstanding recognition results. This suggests that it may not be necessary for perception to require multiple distinct processes.
In other words, the processes underlying perception and sensation may not be fundamentally different; they only differ in the nature of the objects they represent. To be more specific, before these sensations are subjectively considered "corresponding" to a particular object, they are called sensations. Once they correspond to a specific object, they become perceptions.
If we continue along this line of thinking and accept that sensation and perception are the same process, then we inevitably face the question: how can combinations of sensations express perceived objects?
To address this question, we will start with the simplest case and gradually delve deeper.
Imagine, for instance, a simple visual neuron. Its function is that, within its receptive field, if more than 50% of the area is black, it enters an activated state; otherwise, it remains inactivated. If we set its receptive field to be a display screen (for simplicity's sake, considering only a black-and-white screen), it clearly cannot distinguish different shapes on the screen because there are countless situations where more than 50% of the screen area is black. The converse is also true.
Next, we can endow this neuron with the ability to translate or scale across the screen while recording its current focus position and scaling ratio. With this capability, it becomes evident that this neuron can distinguish all different shapes on the screen. This is because it can at least zoom in until its receptive field contains only a single pixel on the screen. Consequently, as long as any pixel differs, its activation state at this location will be different.
However, this is clearly not the way visual perception works. This is because even for the same object on the screen, the data at each pixel on the screen is likely to be entirely different. There are two reasons for this:
1)The appearance of the same object can vary depending on its position and the angle from which it is observed. For example, a frontal view and a side view of a face.
2) Objects of the same class but differ in insignificant details.
The first problem is relatively easy to solve: the relationship between an object and its appearance is essentially one-to-many. In this case, it is sufficient to associate the different appearances corresponding to various structures with the same object.
The second problem has two solutions. The first is the data-driven solution, like the convolutional neural network. The idea behind this solution is that if we have a large amount of data, irrelevant factors are likely to be eliminated within that dataset. This approach allows us to obtain features that are only relevant to the target category.
However, the problem with this solution lies in the fact that it first requires an exhaustive amount of samples to eliminate irrelevant features. For humans, however, even with only one or two examples, they can quickly grasp the key features of a category. So how do humans achieve this? Imagine this situation: if a friend brings a fruit we've never seen before, we generally focus on its appearance, smell, etc., as the basis for identifying it next time. We would disregard the sticker on it as irrelevant information for recognition. In other words, this implies that the information about the fruit as a larger category already foreshadows how new subcategories within that category should be perceived. Rather than, like in CNNs, completely capturing key features through examples and ignoring the information provided by its parent category.
Recognition or Creation?
So, how can we utilize information from parent categories to help establish perception of new subcategories? To address this, we must return to a more fundamental question: why does our mind require categories? The prevailing view in the scientific community is that there are objectively many different categories of objects in the world, and the purpose of our mind is to describe these categories. In other words, the description of categories in thought is merely a reflection of the objective world. However, philosophers during the Enlightenment era critiqued this idea. Kant pointed out that humans cannot grasp the essence of external objects, but can only understand things through the senses. Does this difference lead to a substantial variation in the way intelligence is achieved? Yes, and the difference is significant. However, few people pay attention to this distinction.
if the external objective existence is not the basis for the mind to distinguish between different categories, then a new basis must replace it. What would that be? Our answer is that all categories are created based on their differing functions. The naïve prototype of this creation process can be described as follows: Initially, the activation of all representations in the mind corresponds to the same function. When an unexpected function emerges, further observation is conducted to obtain new representations that can distinguish between different functions. Through repeated iterations of this process, a progressively deeper tree-like structure can be generated, where each node of the tree branches corresponds to a distinct function. (Note: In real-world situation, it is necessary to consider that appearance and category are two distinct yet interdependent dimensions, which adds an additional complexity. As a result, the actual structure would be far more intricate than this tree-like structure. However, for the purpose of our explanation, we will focus on this simplified tree structure.)
Furthermore, the development of new sub-nodes under a parent node is essentially the discovery of new features. This discovery involves actions of the attention mechanism and may also include physical actions. This implies that when a parent node has multiple sub-nodes, the actions required to generate new sub-nodes are already embedded within it.
In this way, we resolve the question raised at the beginning of this section: how can people identify a new category with only one or two examples? In fact, the mind can establish new subcategories by relying on the actions previously taken to create subcategories for the same parent category. This is because the experience of creating subcategories in the past has already guided the mind on where to search for the critical features needed to establish a new subcategory.
Some researchers might challenge the above viewpoint, arguing that human interaction with the external world follows a process where people first perceive the external world and then respond by producing actions. How, then, could actions participate in the process of perception? However, research in embodied cognition over the past century has demonstrated that actions do play a role in perception. For instance, Alva Noë's Action in Perception explicitly highlights this point.
Perception Within the Mind vs. Free Will
Next, we will discuss what we believe to be one of the most central issues in thought: what is the origin of the mind's actions? In the previous section, we pointed out that when the mind discovers a new subcategory, it attempts to capture its key features. This capturing of key features is actually an action (involving both attention and potentially physical aspects). So what makes the mind choose to perform the action corresponding to this parent node, rather than another parent node's action? Even more broadly, what makes the mind choose to undertake this further work of capturing key features? In fact, sometimes the mind can completely refrain from doing this work of capturing key features. For example, if we are busy working in the office, we may ignore a new fruit that a colleague brings in.
Recalling, the reason the mind performs the action of feature discovery is that a new object in the external world can correspond to a parent node, but there is no known sub-node that corresponds to the function manifested by this new object. Let’s imagine that another person’s mind contains both the parent node and the sub-node. When this person encounters the object corresponding to the sub-node, would they perform the action of creating a new sub-node? Clearly, they would not create the sub-node again, as their mind already contains it.
This example highlights an obvious and important issue: the trigger for actions in the mind arises not only from external information but also from the relationship between internal and external factors. In this case, the internal factor comes from the states manifested in memory, which stores perceptual information—specifically, the presence of a parent node without the corresponding sub-node that represents the function of the object. More importantly, this states does not depend on any specific object. Whether it's a new fruit, a new car, or any other new subcategory, the same principle applies. In other words, the source driving the mind to take specific action is the internal states of the storage structure from the perceptional system within the mind.
In the past, it was commonly believed that the reason people choose to do one thing rather than another was due to free will. However, an increasing number of cognitive science experiments have found that free will does not exist. So where does the origin of human behavior lie?
Our example above illustrates how the internal states of the perceptual system can drive certain actions. If the states of the perceptual system can be the cause of actions, could other states from internal structures within the mind, such as emotions, language, goals, and memory, also become sources of actions?
If this idea is correct, then we believe that there is a core within the mind. This core, by observing the internal states of the mind's various sub-systems, locates appropriate actions and performs them.
Some might think that the "core" we are referring to is just a "homunculus" in the brain—a small human-like figure within the mind that controls actions and decisions. This idea merely shifts the problem of free will inward without addressing the real issue. However, this is not the case, because the program that locates the appropriate actions based on the internal states of thought does not require complex decision-making. It only needs to perform simple reflexive actions. The difference lies in the fact that tranditional conditional reflexes referred to the relationship between external conditions and physical actions, while the core’s reflex is based on the states exhibited by various internal subsystems of the mind and the actions within the mind. This implies that the core can be learned through simple reinforcement learning.
If we accept that internal factors within the mind determine human behavior, then the concept of free will becomes easier to explain. Let’s consider an example. A typical argument for free will goes like this: "Alex was planning to go out in the afternoon, but when someone predicted that Alex would go out, Alex decided not to." The point people want to make with this example is that, even though external conditions haven’t changed, Alex still has the ability to choose whether or not to go out.
However, if we take internal factors into account, it becomes clear that this dissolves the myth of free will. When Alex learns that someone has predicted his actions, his mental state changes. Not only does the information Alex possesses change, but so might his goal—shifting from simply going out to proving that he has the freedom to make his own choices. This shift in goal helps explain why his behavior changes, making it less surprising that Alex decides not to go out. Thus, there is no necessity for free will to play a role in this scenario.
Finally, through the method principle above, we can easily answered our initial question: how does the mind make learning efficient? Simply put, the mind uses this classification to guide the learning of knowledge for each category using the methods of its parent category. This allows for highly efficient learning. Furthermore, as more knowledge is learned and the branches of subcategories expand, the mind becomes increasingly adept at learning. In other words, it learns its own learning methods while acquiring knowledge. This is fundamentally different from data-driven machine learning, where the same method is used regardless of the type of data being learned, resulting in lower efficiency.
In fact, adopting different learning methods based on the category is basic common sense in life. For example, the way we study mathematics is very different from how we study history. Take, for instance, the story of Newton inventing calculus. From a mathematical perspective, the focus is on the methods of calculus and why Newton was able to conceive such an approach. From a historical perspective, the emphasis might be on the time, place, and subsequent impact of the story. However, this obvious distinction has been entirely overlooked by AI researchers advocating for machine learning.
In summary, the process of human learning is determined not only by the nature of the knowledge to be acquired but also by the state of one’s internal knowledge system. In fact, this principle can extend beyond learning to encompass other human behaviors, as various internal cognitive states can also be perceived. Effective behavior, discovered under the consideration of both internal and external states, is essentially the result of accounting for one’s intrinsic capabilities as well as external environmental factors. The validity of such behavior can be confirmed through repeated practice, without the need for complex mathematical computations, such as those involved in optimization.” This aligns with the principle that we previously requested: a unified principle for modeling both the self and the external world in a manner that allows for mutual coherence and integration.
Some machine learning researchers might argue that our conclusion, "internal states drive human behavior," is completely trivial. For example, in large language models, numerous parameters represent the states of the model, and these states generate the following text. Therefore, the idea that internal states drive behavior is an intuitive consensus.
However, the states we are referring to here are entirely different from the states expressed by parameters in machine learning, because in machine learning, the states are simply hidden variables that do not correspond to specific internal structures of the mind. What we are talking about are states that depend on particular mental structures. For instance, the state underlying the behavior of discovering new subcategories is derived from the hierarchical structure of categories in visual perception. Therefore, the states we are discussing are more accurately described as states that depend on the innate structures of the mind.
In fact, our conclusion here is quite different from the mainstream view in cognitive psychology. Mainstream cognitive psychology generally holds that the brain is distinguished by its functions, whereas our perspective is that the brain is not actually divided by function but rather by its inherent internal structures. These structures operate according to a unified principle. Through this operation, the different structures gradually develop their own functions. If our perspective is correct, then the study of thinking should focus on the inherent structures and the unified principle, rather than emphasizing the functions of different sub-systems within the mind, as is the case in mainstream cognitive psychology.
Summary
In this section, we propose the following three hypotheses:
1) Sensation and perception follow the same mechanisms. They are both composed of simple signal integration processes.
2) The combination of signals does not aim to fully replicate the external appearance of an object, but rather to distinguish objects that can produce different functions.
3) Internal subsystems of the mind can be perceived, just like external objects, to obtain their structural states.
Based on these three hypotheses, we speculate that the essence of the mind's operation is a reflex from states to actions. These states originate from both the internal and external environments. The internal environment encompasses the inherent states of the various sub-systems within the mind.
II. How is rationality achieved?
In the previous section, we presented a novel conception of the essential nature of the mind's operation. If we consider the source of knowledge under this conception, it clearly falls under empiricism, as both the extraction of features and the reinforcement training of the core are derived from experience. However, any claim that knowledge in the mind stems from experience must address the issue of rationality. Whether it's the historical debate between empiricism and rationalism in philosophy, or the current lack of reasoning ability in data-driven large language models (which represent an implementation of empiricism), they all demonstrate that rationality seems to be the antithesis of empiricism. On the other hand, human experience and reason coexist simultaneously. This implies that demonstrating the capacity for rationality within an empirically-based model of the mind is crucial. In this section, we will show how the mind model proposed in the previous section generates rationality. Based on this explanation, we will address Hume's key challenge to empiricism, known as the Hume problem.
To explain why our proposed implementation can endow systems with rationality, we first need to define what rationality is. The more traditional definition of rationality is: the way humans use thought, reasoning, and judgment to understand and interact with the world. However, this definition is unhelpful for addressing our problem because it defines rationality through subjects and processes that require further definition. What we need here is a definition of rationality that focuses on its functions and effects. To seek such a definition, we can examine some very distinct but highly typical examples of rationality. Consider the following three examples:
Example 1. The reasoning concludes that the sum of the interior angles of a triangle is 180°
Example 2. When purchasing a new phone, comparing and analyzing the pros and cons of various potential options; evaluating their relevance to oneself; and ultimately making a decision.
Example 3. Choose the appropriate investment options for a deposit: First, understand market trends, assess risks and returns, and set clear investment goals. Then, select investment products that match your risk tolerance and diversify your investments to reduce risk.
It is evident that the three examples above come from entirely different domains and have distinct objectives: 1) focuses on finding a basis for reasoning, while 2) and 3) involve decision-making. However, they share a common characteristic: aligning past knowledge (whether subjective knowledge about oneself or objective knowledge) with the current argumentative goal (which we can consider as an "argument" of "what is most suitable"). This alignment ensures consistency between the current argument and known past knowledge. In this way, past knowledge can be used to support the reasonableness of new knowledge. Therefore, we can conclude that the key process in achieving rationality is a reasoning process that seeks "credible" knowledge to support the current argumentative goal.
So, how does the conditioned reflex system based on internal mind states address the reasoning process described above? In fact, the reasoning processes outlined above involve three sub-goals:
1) Begin with a target argument
2) Finding credible knowledge
3) Establishing one or more logical connections between the target argument and more credible knowledge.
First, let's consider the target argument. In the reasoning process, the target argument either lacks a connection to credible knowledge or has existing connections that are insufficient; otherwise, there would be no need to establish new connections. It is clear that whether it's a lack of connection or insufficient connection, this applies to all arguments. This means it is a state of the system itself rather than a state of specific knowledge. When this state arises, it triggers the mind to initiate the reasoning process. This explains the motivation behind the mind's engagement in reasoning.
Now, let's examine the process of reasoning, specifically sub-goals 2) and 3). Although we previously identified finding reliable knowledge and establishing connections with that knowledge as two distinct sub-goals, interestingly, these two sub-goals are often achieved simultaneously.
Consider Example 1) above, where reasoning leads to the conclusion that the sum of the interior angles of a triangle is 180 degrees. A standard solution involves using parallel lines to translate the three angles to the same vertex, thereby demonstrating that it forms a straight angle. This proves that the sum of the interior angles is 180 degrees.
However, when solving this problem, we do not explicitly enumerate all theorems related to angles. Instead, we instinctively feel that the parallel line theorem can be applied directly to this translation. If someone asks why we thought of using this theorem, we often cannot provide a clear answer, attributing it to intuition.
We believe that this so-called intuition is, in fact, a state within the knowledge system. Specifically, this state involves retrieving more fundamental theorems when proving basic theorems like the sum of the interior angles of a triangle being 180 degrees, while also associating them with the relocation of angles.
Let's consider two other examples, completely different problems but triggering the same behavior.
Example 4: The following diagram shows a maze that is 22 meters long and 18 meters wide. Each path is 2 meters wide. Starting from point A, walk along the center line of the paths to reach point B. What is the total distance traveled in meters?
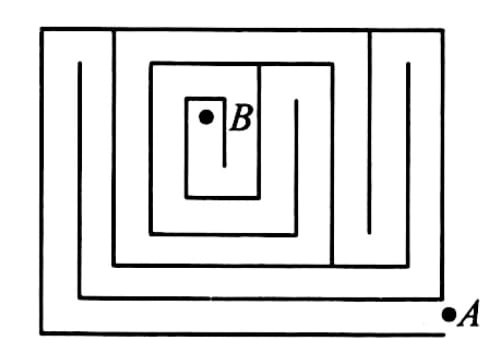
An interesting solution to this problem involves finding an equivalence relationship between the area of the rectangle and the length of the path from A to B. When our team asked the test subjects who came up with this solution why they thought of it, they all responded that the idea originated from an intuition that "if there were an equivalent relationship between the path and the area, then the problem would be simple."
In fact, if we analyze their answers, there are logical errors. After all, how could you know that using this relationship would simplify the problem if you hadn't already considered it?
Now, let's move on from this elementary school math problem to a more serious scientific question.
Example 5: The anomaly in galactic rotation curves has led astronomers to propose the existence of dark matter. By observing the rotational velocities of stars or gas orbiting the centers of galaxies, researchers have found significant discrepancies between the observed velocities and the theoretical results calculated using Newton's law of universal gravitation. According to classical mechanics, material farther from the center of a galaxy should experience weaker gravitational attraction, resulting in a gradual decrease in rotational velocity. However, observations reveal that in regions far from the galactic center, the rotational velocities of stars and gas do not decrease with distance, but instead remain nearly constant. To explain this phenomenon, astronomers hypothesized the existence of a large amount of matter that cannot be directly observed, known as dark matter. Dark matter is thought to be widely distributed, extending beyond the visible matter in galaxies. Its gravitational field provides additional gravitational force, sustaining the higher rotational velocities of material in the outer regions of galaxies.
It's not hard to see that, although Example 5 deals with entirely different objects and solves completely different problems compared to Example 4, they share one characteristic: if a certain condition exists (an equivalence relationship in Example 4, and invisible matter in Example 5), then a complex and unfamiliar problem becomes familiar and simple.
Similarly, it faces the same dilemma as Example 4: did the person who first made the dark matter hypothesis have the idea first, or was simplicity the precursor?
If the logic above holds, then there must be an process within the mind that goes from making hypothesis to evaluate its simplicity. This calculation simply remains unperceived. Its result only manifest when it plays a significant role in reasoning. In other words, we can assume that the mind constantly computes various patterns, and only those patterns that prove useful are made explicit. This implies that the process of discovery and making logical connecting between arguments during reasoning is driven by the pattern between the target argument and the known knowledge. This explains why conditional reflexes incorporating internal mental states can achieve rational thought.
Hume's Problem
We previously pointed out that the key to achieving rationality lies in relating the target argument to more credible, known knowledge, thereby increasing the argument's credibility. However, this understanding of rationality leaves a significant question unanswered: "What constitutes credibility?" To address this question fully, we must return to Hume's problem.
Hume's problem (the problem of induction) was raised by 18th-century philosopher David Hume and questioned the validity of inductive reasoning. Inductive reasoning involves inferring the future from past experiences, such as concluding that the sun will rise tomorrow because it has risen every day in the past. However, Hume argued, why should we believe that the future will resemble the past?
Inductive reasoning relies on the assumption of "the uniformity of nature," meaning that the future will operate in the same way as the past. But this assumption cannot be proven logically, nor can it be proven by induction itself without falling into circular reasoning.
British philosopher Bertrand Russell vividly illustrated this problem with "Russell's Chicken": A chicken observes that food appears in its trough every morning, leading it to believe that food will always appear there. However, one morning, it finds the trough empty. The farmer then arrives and wrings its neck.
The chicken's inference was based on past experience, but experience cannot guarantee that the future will be identical. Therefore, inductive reasoning lacks necessity; our belief stems from habit or psychological tendency rather than rational proof.
Thus, Hume concluded that inductive reasoning lacks an absolute rational foundation, therefore imbuing science and everyday knowledge with uncertainty.
This problem remains unresolved in the fields of philosophy of science and epistemology to this day. Some modern scientists and philosophers have attempted to address it using probability theory and statistics, even claiming that while absolute correctness of induction cannot be proven, reasonable conjectures can be supported on a high-probability basis.
However, these scientists and philosophers fail to recognize that the prerequisite conditions for their "high probability" still rely on the assumption of the uniformity of nature in statistics. Clearly, this is merely a new form of circular reasoning.
So, can the mind overcome Hume's challenge? The answer is both yes and no. It's a "no" because humans cannot find an absolutely correct, foundational truth to base other absolute knowledge upon. However, it's also a "yes" because humanity transcends simply performing inductions within the same category. Instead, the mind can connect various phenomena from different categories, striving to achieve the most credible knowledge possible given available information and reasoning tools.
We can see that, in our previous examples – "We see the sun rise every day, so we infer that the sun will rise again tomorrow," and "A chicken is fed by the farmer every day, so it infers that the farmer will continue to feed it" – the inductive reasoning involved is an induction of similar events. In fact, modern statistics operate in a similar manner, predicting future events solely based on similar past events.
However, human thought has surpassed this limitation. Through deductive reasoning, it connects events from different categories. For example, the celestial regularity of the sun's rising is linked to Newton's laws and the falling of objects on Earth. They mutually support each other, making the phenomena more credible. This transcends the reliability obtainable solely from similar events
Of course, this method doesn't entirely overcome Hume's problem because theoretically, all observed phenomena could mutually support each other while remaining partial perspectives. Nevertheless, within the realm of knowledge accessible to the mind, this is the most credible inference possible. Applied to the Russell chicken example, the chicken would investigate why this particular feeding trough produces food - is it the material or shape? Do other similar materials produce food? Is there a more general law governing food production? Simply concluding that this specific trough produces food might be a problematic isolated case.
At this point, we have explained that the essence of credibility lies in being connected to a large body of interrelated and mutually supportive knowledge. The essence of reasoning, then, is to establish new supportive relationships between incoming arguments and this existing body of interconnected knowledge. In other words, it is about integrating new arguments into this already validated knowledge system, forming a larger and more coherent framework of knowledge.
In fact, our explanation of the mechanisms of reasoning aligns with a less widely recognized but logically coherent philosophical school's understanding of knowledge. For specific details, please refer to the discussion on SEP: https://plato.stanford.edu/entries/justep-coherence/.
III. Has machine learning achieved AGI (Artificial General Intelligence) or ASI (Artificial Superintelligence)?
In recent years, due to the significant breakthroughs in large language models, machine learning researchers have expressed unprecedented optimism regarding the realization of Artificial General Intelligence (AGI). It is widely believed that following the Scaling Law is the right path to AGI. As model parameters and training data continue to expand, the realization of AGI seems to be within reach.
More radical perspectives even suggest that data-driven approaches could not only achieve human-level intelligence but may also give rise to superintelligence that surpasses human wisdom itself. Is this view well-founded? Let’s dive deeper into this issue.
Why do large language models work?
Since the specific implementation details of various large language models can be easily found online, we will not delve into the technical intricacies here. Instead, we will provide a brief overview of the two key pillars of large language models and explain how they work together to enable functionality.
Simply put, large language models operate primarily based on two fundamental components: embedding and attention.
Embedding is a vector in a high-dimensional vector space. In large language models, any string of text can be transformed into a vector. We can crudely view embedding as the semantic representation of a string in vector space.
For example, if two vectors represent a peach and a watermelon respectively, it's clear they share similarities and differences. A similarity is that both are delicious; a difference is that peaches grow on trees while watermelons grow on the ground. Therefore, the factors representing shared properties in their embeddings would be similar, whereas those representing distinct properties would exhibit significant differences.
The attention mechanism, on the other hand, selectively extracts property vectors from embeddings based on current needs. When these vectors are converted back into text, they become new context. For example, if the attention targets "where it grows," and the object is "peach," the extraction results in "on a peach tree."
In essence, we can view a large language model as decomposing input into two distinct components: an operator (attention) and an operand (embedding). Since both world knowledge and grammar of expressing knowledge can be seen as results of operations on content, for example, subjects (operand) are followed (operator) by verbs, drinking water (operand) quenches (operator) thirst.
Through multiple layers of embeddings and attention structures, some levels extract syntactic relationships while others extract semantic or knowledge-based relationships. Consequently, large language models learn both the knowledge of the world and grammar of expressing that knowledge simultaneously.
If we solely consider how knowledge is stored within large language models, it effectively establishes two types of correspondences:
1) Through embedding, objects are represented as a set of properties.
2) Through attention, it establishes relationships between properties.
This model architecture is remarkably powerful, enabling it to address novel problems that may involve unfamiliar objects. Often, despite differing object descriptions, underlying shared properties exist. If these properties align with those already familiar to the large language model, it can leverage existing knowledge to solve seemingly new problems.
Even more impressive, the model may statistically discover previously unnoticed relationships between properties. When guided by a prompt to express such relationships, it can astound users with its capabilities.
Problems with large language models
However, we believe that this implementation principle of large language models has a critical flaw—namely, the relationships between concepts are linked by the statistical significance of data rather than by logical reasoning. This flaw leads to at least three serious issues.
Problem 1: It memorizes a vast amount of knowledge, but this knowledge remains fragmented and lacks mutual support. Consequently, when certain factors change, the large language model cannot automatically figure out the potential impact on other related knowledge.
We can illustrate this problem with an example. We could provide the large language model with the following two prompts:
Prompt 1: If the Moon were 50% closer to Earth, how many days would there be in a month?
Prompt 2: Help me write a diary entry for a sci-fi story. The story is set on a Gaia planet similar to Earth, but its moon orbits at half the distance compared to Earth's moon. The diary's author is a Gaia scientist who begins documenting unusual planetary anomalies half a month before a global flood.
When Prompt 1 is input into large language models, most mainstream models correctly recognize the need to calculate the duration of a month and utilize Kepler's Third Law to arrive at the accurate answer. However, when presented with Prompt 2, all models generate diary entries reflecting a lunar cycle of 14 or 15 days (the correct answer should be 5 or 6 days).
This phenomenon occurs because, under Prompt 1, the large language model has already established the relationship between the length of a month and the Earth-Moon distance. Since both elements are present in Prompt 1, it triggers a recalculation.
However, Prompt 2 does not mention "the length of a month," instead requiring its use within the context of writing a diary entry. Because the large language model's knowledge is unassociated, it fails to recognize the potential change in monthly duration and consequently produces an error.
Some might wonder if there is a way to improve this issue. In fact, there are two possible approaches.
One is to directly link the shortening of the moon’s distance to the act of writing in the diary through training data. When this occurs, it would require recalculating the length of each month before continuing the diary entries.
However, the problem with this method is that such training data can only address the specific relationship between the moon’s distance and diary writing. For any other tasks potentially affected by the moon’s distance, separate data would be needed.
More importantly, there are countless potential cascading effects. For instance, A might affect B, and B could influence C, ultimately resulting in A affecting C. This would require training data to cover not only A affecting B and B affecting C but also A directly affecting C. Chains like this can extend indefinitely.
Another potential approach is to attempt using Chain of Thought (CoT) reasoning. For instance, in the earlier diary-writing example, a prompt could be added to ask, “What potential effects might the moon’s closer proximity have on diary writing?” This would guide the model to first list all possible impacts (note: with current methods, it might not detect changes in date calculations for diary entries. However, theoretically, a more advanced model could achieve this, so let’s assume such a model exists), and then proceed with further writing.
However, even if this step is feasible, as the writing task becomes more comprehensive, the number of interacting elements increases. This means the relationships between these elements could become highly complex. Consequently, it would require using CoT to ask step-by-step about all possible changes, but the number of queries would grow exponentially with the number of elements. For nnn elements, there could potentially be nnn-way interactions. Therefore, this approach also becomes impractical in complex environments.
Problem 2: Learning Efficiency Issues
The second issue arising from the lack of structured knowledge in large language models is the inefficiency of learning. Human knowledge is organized into structured systems. When fundamental knowledge at the core changes, humans actively reflect on the resulting chain reactions and reconstruct the related knowledge framework.
For example, scientists initially regarded relativity and quantum mechanics as mere "small clouds" in the field of physics. However, these theories profoundly altered our understanding of time, space, and matter, prompting a reevaluation and overhaul of the entire physical framework. This ability to self-reflect and restructure systems allows humans to efficiently respond to foundational breakthroughs, driving the overall evolution of knowledge.
In contrast, machine learning—particularly large language models—relies on two primary learning methods: training and in-context learning. However, regardless of the method, these models lack a clear internal knowledge framework. They cannot comprehend the hierarchical relationships between pieces of knowledge, nor can they proactively make systematic adjustments when fundamental knowledge changes.
For instance, if an important fact in the model's training data is updated, the model can only rely on retraining with new data or generating new answers within specific contexts. Unlike humans, it cannot actively and flexibly restructure related knowledge in response to foundational updates.
This deficiency has far-reaching consequences. The absence of a knowledge structure prevents machine learning models from efficiently adapting and comprehending the deeper implications of new information or fundamental cognitive updates. This not only limits their capacity for long-term, effective knowledge acquisition but also implies they cannot match human learning efficiency in complex, dynamic knowledge domains.
Problem 3: Lack of Self-Awareness Regarding Capabilities
The third problem arising from the lack of logical connections between knowledge is these models' inability to cognitively assess their own capabilities. Because machine learning-derived knowledge originates from external data, models' understanding of their own abilities is also externally sourced. Consequently, a model's self-reported capabilities may diverge from its actual performance.
This contrasts sharply with how humans evaluate their own abilities. We draw upon past experiences successfully completing tasks and use inferential reasoning based on knowledge relationships to gauge our competence. For instance, if we recognize our ability to execute each step of a task, we can logically conclude our capacity to complete the entire task.
In fact, the ability to assess what tasks one can accomplish is crucial for humans. When faced with a complex problem, we often need to break the task down. The goal of this breakdown includes evaluating our own abilities, as the purpose of decomposition is to make the task easier to complete. This sense of making things easier fundamentally relies on an assessment of our own capabilities.
Some may question our argument above by pointing out that modern large language models can also break down tasks and complete them step by step—Chain of Thought (CoT) being a prime example. This is indeed true. However, the reason CoT can effectively accomplish tasks is largely due to coincidental patterns in the data.
Specifically, the breakdown of common tasks comes from human-generated data, reflecting what people believe they can do. Meanwhile, the actual execution of these steps also frequently appears in the training data, representing what can actually be done. This coincidence allows large language models to align "what they think they can do" with "what they can actually do."
However, if a model were to advance like humans by developing new abilities through experience, it would inevitably acquire capabilities that were not part of the original training data. These new abilities cannot be accurately assessed by the model itself, breaking the alignment between its belief and actual capabilities.
Because external world knowledge is relatively static, and errors in knowledge reasoning do not result in irreversible physical damage, the lack of self-awareness regarding capabilities is less critical for language models. However, this deficiency poses a significantly greater problem for robots designed to perform real-world tasks.
In the physical world, scenarios are constantly evolving, leading to changes in available tools and consequently, the robot's own capabilities. This necessitates rapid reassessment of abilities; otherwise, miscalculations could lead to irreversible physical damage.
Discuss
