


Proteins, the essential molecular machinery of life, play a central role in numerous biological processes. Decoding their intricate sequence, structure, and function (SSF) is a fundamental pursuit in biochemistry, molecular biology, and drug development. Understanding the interplay between these three aspects is crucial for uncovering the principles of life at a molecular level. Computational tools have been developed to tackle this challenge, with alignment-based methods such as BLAST, MUSCLE, TM-align, MMseqs2, and Foldseek making significant strides. However, these tools often prioritize efficiency by focusing on local alignments, which can limit their ability to capture global insights. Additionally, they typically operate within a single modality—sequence or structure—without integrating multiple modalities. This limitation is compounded by the fact that nearly 30% of proteins in UniProt remain unannotated due to their sequences being too divergent from known functional counterparts.
Recent advancements in neural network-based tools have enabled more accurate functional annotation of proteins, identifying corresponding labels for given sequences. However, these methods rely on predefined annotations and cannot interpret or generate detailed natural language descriptions of protein functions. The emergence of LLMs such as ChatGPT and LLaMA has showcased exceptional capabilities in natural language processing. Similarly, the rise of protein language models (PLMs) has opened new avenues in computational biology. Building on these developments, researchers propose creating a foundational protein model that leverages advanced language modeling to represent protein SSF holistically, addressing limitations in current approaches.
ProTrek, developed by researchers at Westlake University, is a cutting-edge tri-modal PLM that integrates SSF. Using contrastive learning it aligns these modalities to enable rapid and accurate searches across nine SSF combinations. ProTrek surpasses existing tools like Foldseek and MMseqs2 in speed (100x) and accuracy while outperforming ESM-2 in downstream prediction tasks. Trained on 40 million protein-text pairs, it offers global representation learning to identify proteins with similar functions despite structural or sequence differences. With its zero-shot retrieval and fine-tuning capabilities, ProTrek sets new protein research and analysis benchmarks.
Descriptive data from UniProt subsections were categorized into sequence-level (e.g., function descriptions) and residue-level (e.g., binding sites) to construct protein-function pairs. GPT-4 was used to organize residue-level data and paraphrase sequence-level descriptions, yielding 14M training pairs from Swiss-Prot. An initial ProTrek model was pre-trained on this dataset and then used to filter UniRef50, producing a final dataset of 39M pairs. The training involved InfoNCE and MLM losses, leveraging ESM-2 and PubMedBERT encoders with optimization strategies like AdamW and DeepSpeed. ProTrek outperformed baselines on benchmarks using 4,000 Swiss-Prot proteins and 104,000 UniProt negatives, evaluated by metrics like MAP and precision.
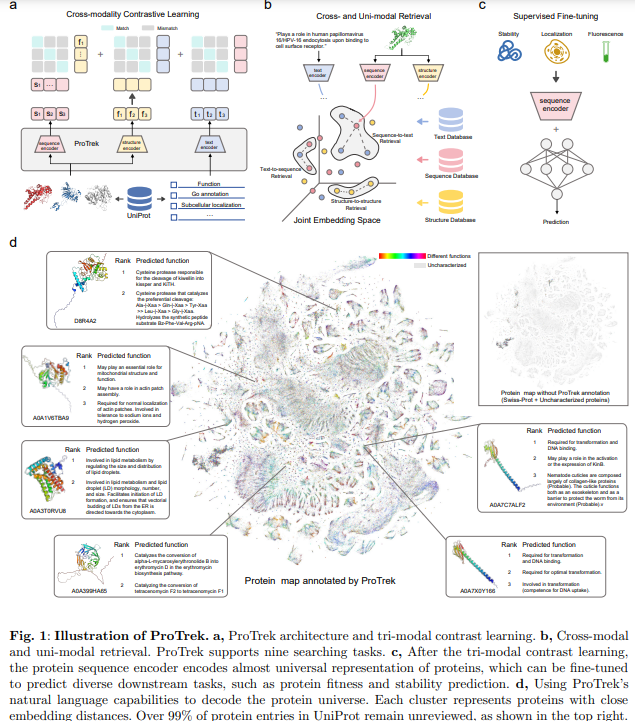
ProTrek represents a groundbreaking advancement in protein exploration by integrating sequence, structure, and natural language function (SSF) into a sophisticated tri-modal language model. Leveraging contrastive learning bridges the divide between protein data and human interpretation, enabling highly efficient searches across nine SSF pairwise modality combinations. ProTrek delivers transformative improvements, particularly in protein sequence-function retrieval, achieving 30-60 times the performance of previous methods. It also surpasses traditional alignment tools such as Foldseek and MMseqs2, demonstrating over 100-fold speed enhancements and greater accuracy in identifying functionally similar proteins with diverse structures. Additionally, ProTrek consistently outperforms the state-of-the-art ESM-2 model, excelling in 9 out of 11 downstream tasks and setting new standards in protein intelligence.
These capabilities establish ProTrek as a pivotal protein research and database analysis tool. Its remarkable performance stems from its extensive training dataset, which is significantly larger than comparable models. ProTrek’s natural language understanding capabilities go beyond conventional keyword-matching approaches, enabling context-aware searches and advancing applications such as text-guided protein design and protein-specific ChatGPT systems. ProTrek empowers researchers to analyze vast protein databases efficiently and address complex protein-text interactions by providing superior speed, accuracy, and versatility, paving the way for significant advancements in protein science and engineering.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post ProTrek: A Tri-Modal Protein Language Model for Advancing Sequence-Structure-Function Analysis appeared first on MarkTechPost.
