


Large language models (LLMs), including GPT-4, LLaMA, and PaLM are pushing the boundaries of artificial intelligence. The inference latency of LLMs plays an important role because of LLMs integration in various applications, ensuring a positive user experience and high service quality. However, the LLM service operates within an AR paradigm, generating one token at a time because the attention mechanism relies on previous token states to generate the next token. To produce a longer response, a forward pass is executed using LLMs equivalent to the number of tokens generated, leading to high latency.
The efficient LLM Inference method is divided into two streams, a method that needs additional training and another that does not need it. Researchers explored this method due to the high AR inference cost for LLMs, mostly focused on increasing the AR decoding process. Another existing method is LLM Distillation, where the Knowledge distillation (KD) technique is used to create small models and replace the functionality of larger ones. However, traditional KD methods are not effective for LLMs. So, KD is used for autoregressive LLMs to minimize the reverse KL divergence between student and teacher models through student-driven decoding.
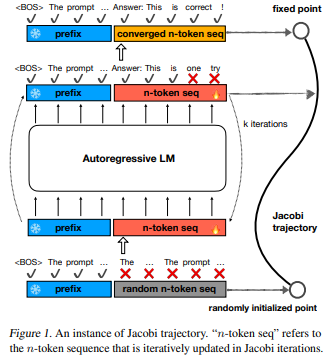
Researchers from Shanghai Jiao University and the University of California proposed Consistency Large Language Models (CLLMs), a new family of LLMs specialized for the Jacobi decoding method for latency reduction. CLLM was compared with traditional methods such as speculative decoding and Medusa for adjusting auxiliary model components and didn’t use extra memory for this task, unlike others. When CLLMs are trained on ∼ 1M tokens for LLaMA-7B, it becomes 3.4 times faster on the Spider dataset showing that the cost of fine-tuning is moderate for this method. Two main factors for this speed-up are fast forwarding and stationary tokens.
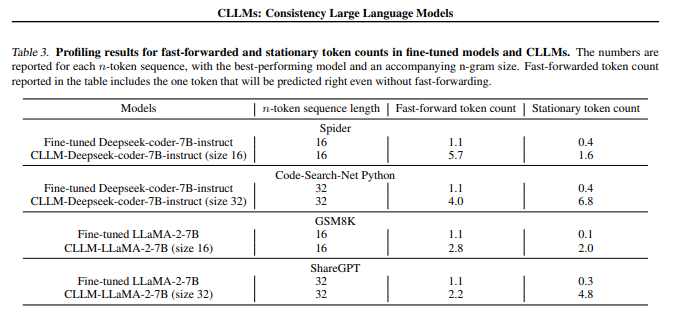
In fast forwarding, correct predictions are done in a single forward pass for multiple consecutive tokens whereas, stationary tokens show correct prediction with no change through subsequent iterations despite being preceded by inaccurate tokens. In target LLMs and CLLMs, when fast-forwarded and stationary counts are compared across all four datasets (in Table 3), there is an improvement of 2.0x to 6.8x in both token counts. Also, for both the token counts, such improvement in domain-specific datasets is better than in open-domain datasets profiled on MT-bench. This helps distinctive collocations and easy syntactical structures like blank space, newline tokens, and repetitive special characters in specialized domains like coding.
Researchers carried out experiments to evaluate the performance and inference speedup of CLLMs across multiple tasks such as comparing the stat-of-the-art (SOTA) baselines on the three domain-specific tasks and the open-domain profiled on MT-bench. CLLMs show outstanding performance on various benchmarks, e.g. they can achieve 2.4× to 3.4× speedup using Jacobi decoding with nearly no loss in accuracy on domain-specific benchmarks like GSM8K, CodeSearchNet Python, and Spider. CLLMs can achieve 2.4× speedup on ShareGPT with SOTA performance, with a 6.4 score on the open-domain benchmark MT-bench.
In conclusion, researchers introduced CLLMs, a new family of LLMs that excel in efficient parallel decoding and are designed in a way that they can improve the efficiency of Jacobi decoding. Additional architecture designs or managing two different models in a single system are complex and complexity is reduced with the help of CLLMs because this method is directly adapted from a target pre-trained LLM. Besides, fast-forwarded and stationary token counts are compared across four datasets, showing an enhancement of 2.0x to 6.8x In target LLMs and CLLMs.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post Consistency Large Language Models (CLLMs): A New Family of LLMs Specialized for the Jacobi Decoding Method for Latency Reduction appeared first on MarkTechPost.
