


Federated learning has emerged as an approach for collaborative training among medical institutions while preserving data privacy. However, the non-IID nature of data, stemming from differences in institutional specializations and regional demographics, creates significant challenges. This heterogeneity leads to client drift and suboptimal global model performance. Existing federated learning methods primarily address this issue through model-centric approaches, such as modifying local training processes or global aggregation strategies. Still, these solutions often offer marginal improvements and require frequent communication, which increases costs and raises privacy concerns. As a result, there is a growing need for robust, communication-efficient methods that can handle severe non-IID scenarios effectively.
Recently, data-centric federated learning methods have gained attention for mitigating data-level divergence by synthesizing and sharing virtual data. These methods, including FedGen, FedMix, and FedGAN, attempt to approximate real data, generate virtual representations, or share GAN-trained data. However, they face challenges such as low-quality synthesized data and redundant knowledge. For example, mix-up approaches may distort data, and random selection for data synthesis often leads to repetitive and less meaningful updates to the global model. Additionally, some methods introduce privacy risks and remain inefficient in communication-constrained environments. Addressing these issues requires advanced synthesis techniques that ensure high-quality data, minimize redundancy, and optimize knowledge extraction, enabling better performance under non-IID conditions.
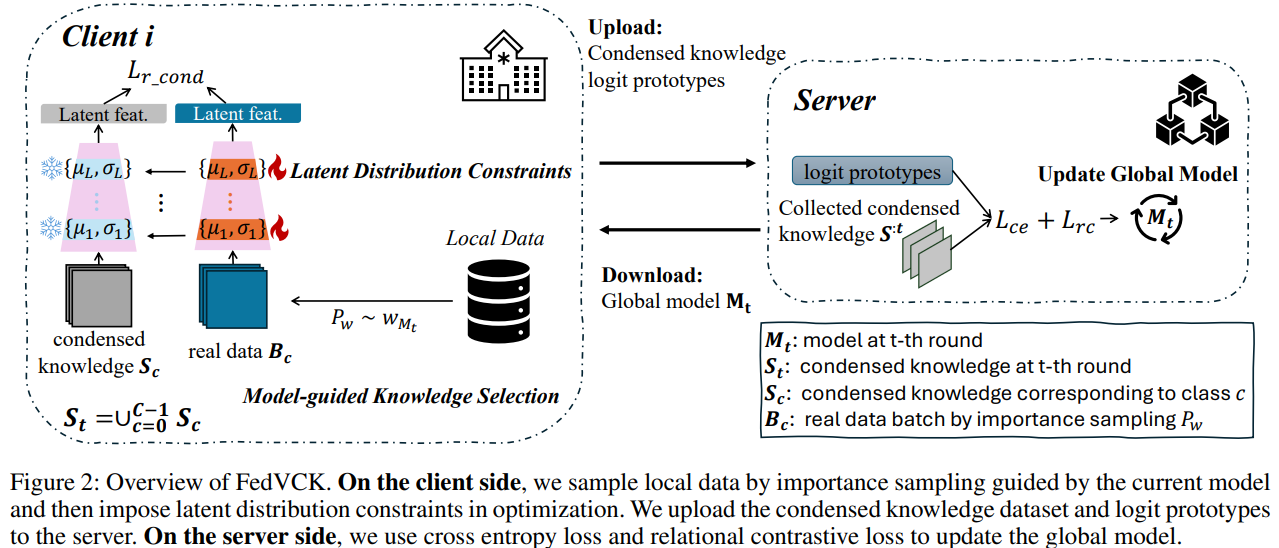
Researchers from Peking University propose FedVCK (Federated learning via Valuable Condensed Knowledge), a data-centric federated learning method tailored for collaborative medical image analysis. FedVCK addresses non-IID challenges and minimizes communication costs by condensing each client’s data into a small, high-quality dataset using latent distribution constraints. A model-guided approach ensures only essential, non-redundant knowledge is selected. On the server side, relational supervised contrastive learning enhances global model updates by identifying hard negative classes. Experiments demonstrate that FedVCK outperforms state-of-the-art methods in predictive accuracy, communication efficiency, and privacy preservation, even under limited communication budgets and severe non-IID scenarios.
FedVCK is a federated learning framework comprising two key components: client-side knowledge condensation and server-side relational supervised learning. On the client side, it uses distribution matching techniques to condense critical knowledge from local data into a small learnable dataset, guided by latent distribution constraints and importance sampling of hard-to-predict samples. This ensures the condensed dataset addresses gaps in the global model. The international model is updated on the server side using cross-entropy loss and prototype-based contrastive learning. It improves class separation by aligning features with their prototypes and pushing them away from hard, negative classes. This iterative process enhances performance.
The proposed FedVCK method is a data-centric federated learning approach designed to address the challenges of non-IID data distribution in collaborative medical image analysis. It was evaluated on diverse datasets, including Colon Pathology, Retinal OCT scans, Abdominal CT scans, Chest X-rays, and general datasets like CIFAR10 and ImageNette, encompassing various resolutions and modalities. Experiments demonstrated FedVCK’s superior accuracy across datasets compared to nine baseline federated learning methods. Unlike model-centric methods, which showed mediocre performance, or data-centric methods, which struggled with synthesis quality and scalability, FedVCK efficiently condensed high-quality knowledge to improve global model performance while maintaining low communication costs and robustness under severe non-IID scenarios.
The method also demonstrated significant privacy preservation, as evidenced by membership inference attack experiments, where it outperformed traditional methods like FedAvg. With fewer communication rounds, FedVCK reduced the risks of temporal attacks, offering improved defense rates. Furthermore, ablation studies confirmed the effectiveness of its key components, such as model-guided selection, which optimized knowledge condensation for heterogeneous datasets. Extending its evaluation to natural datasets further validated its generality and robustness. Future work aims to expand FedVCK’s applicability to additional data modalities, including 3D CT scans, and to enhance condensation techniques for better efficiency and effectiveness.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post FedVCK: A Data-Centric Approach to Address Non-IID Challenges in Federated Medical Image Analysis appeared first on MarkTechPost.
