
无需额外模型训练、即插即用,全新的视频生成增强算法——Enhance-A-Video来了!
和最近人气超高的混元视频生成模型(HunyuanVideo)对比来看,加入Enhance-A-Video的版本在生成画面中表现出了更加丰富的细节和更高的语义契合度,生成内容和用户输入的文本提示更匹配:
研究团队成员来自新加坡国立大学、上海AI实验室和德克萨斯大学奥斯汀分校。
简单来说,新算法通过调整时间注意力层输出的一个关键参数,能够在几乎不增加推理负担的情况下,大幅提升生成视频的细节表现和时序连贯性。
Enhance-A-Video还兼容多种主流视频生成模型,无需修改基础架构即可直接应用。
比如CogVideoX-2B + Enhance-A-Video:

还有OpenSora-V1.2 + Enhance-A-Video:

实验结果显示,Enhance-A-Video在提升视频质量方面表现卓越,尤其是在对比度、清晰度以及细节真实性上有显著改进。
新算法一经发布,其强大的泛化能力也是迅速得到了社区的认可。
很多网友已将该算法集成到多个主流推理框架中,包括ComfyUI-Hunyuan和ComfyUI-LTX。
对比一下网友Kijai发布的原始混元模型和增强后的效果,可以看到模型生成画面更加自然,动态表现也更加流畅:



△Comfy-UI测试结果,左边为原始视频,右边为增强视频
LTX-Video的研究人员Nir Zabari还成功将它应用到了LTXV模型中,显著提升了生成视频在动作一致性和细节呈现方面的表现。

这一成果表明,Enhance-A-Video不仅适用于特定模型,还能广泛适配于不同的视频生成框架。
研究背景:提升视频生成质量需求强烈
近年来,以Diffusion Transformer(DiT)为代表的视频生成技术[1]迅猛发展,能够根据文本描述生成多样化的视频内容。
然而,现有方法仍面临以下挑战:
时序不连贯:帧与帧之间缺乏一致性;
细节模糊:画面纹理缺乏清晰度;
画面抖动:动态效果不够稳定。
这些问题显著影响了生成视频的实用性和观看体验,如何提升 AI 生成视频的质量成为当前研究的关键问题之一。
为了解决上述问题,Enhance-A-Video应运而生。其核心原理是通过一个增强系数,优化时间注意力的分布,从而实现以下优势:
高效增强:快速提升视频质量;
无需训练:可直接应用于现有生成模型;
即插即用:灵活适配多种场景和需求。
设计动机:时间注意力的优化潜力
时间注意力(Temporal Attention)在DiT模型中负责信息的帧间传递,对生成视频的连贯性和细节保留至关重要。
通过对不同DiT层的时间注意力分布进行可视化分析,研究人员发现:
在部分DiT层中,时间注意力的分布存在显著差异:跨帧注意力(非对角线部分)的强度明显低于单帧自注意力(对角线部分)。
这一现象可能导致帧间信息传递不足,进而影响视频的一致性和细节表现。
基于这一观察,作者提出了一个关键假设:能否通过利用时间注意力来提高视频质量?
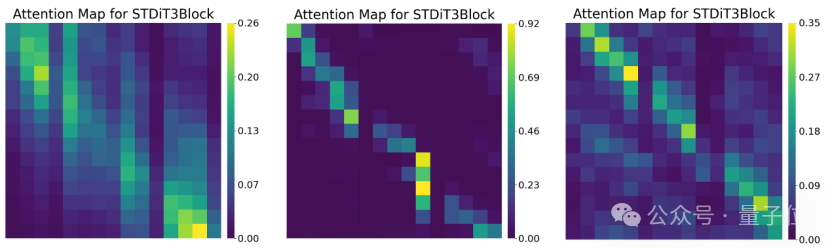
△不同DiT层的时间注意力分布图
方法概述:无需训练的动态增强方案
基于上述观察与思考,作者首次发现时间注意力的温度系数决定了不同帧之间的相关性强度,相关性强度越高意味着每一帧生成时,在时间上下文维度所考虑的范围越广。
由此想法出发,作者提出了一种调整时间注意力层输出,无需训练的视频增强方法,该方法可以直接应用于现有的AI视频生成模型。
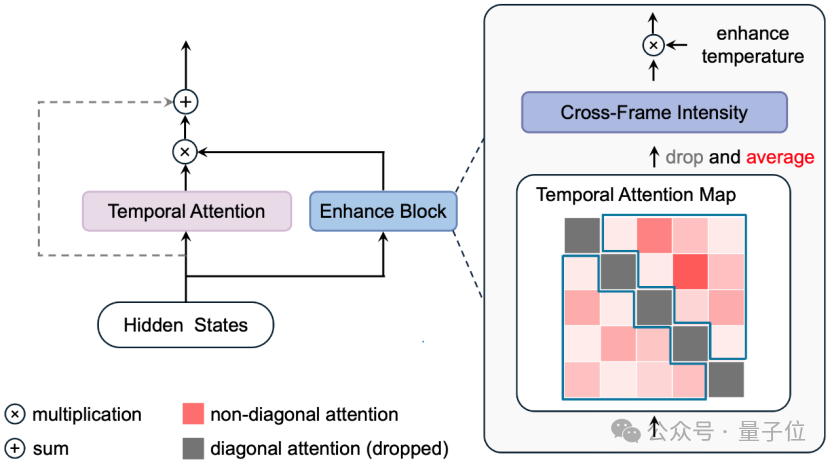
△Enhance-A-Video框架图
Enhance-A-Video的核心设计是通过动态调节时间注意力层的输出,实现对帧间一致性和细节表现的优化。
具体方法分为以下几步:
1.并行增强模块
在时间注意力层的基础上增加一个并行分支,计算时间注意力分布图。
输入时间注意力层的隐藏状态也被传入增强模块。
2.计算跨帧强度(CFI)
从时间注意力分布图中提取非对角线元素的平均值,作为跨帧强度(Cross-Frame Intensity, CFI)。
3.动态增强控制
引入增强温度参数(Enhance Temperature),将其与CFI的乘积作为增强模块的输出系数。
利用该系数动态调整时间注意力层输出的特征增强强度。
通过这一策略,Enhance-A-Video 能够高效地提升视频的帧间一致性和细节表现,而无需对原始模型进行重新训练。
为AI视频生成技术提供新思考
这项研究提出了首个无需训练、即插即用的AI生成视频质量增强方法——Enhance-A-Video,针对当前生成视频质量的关键问题,围绕时间注意力机制展开创新设计,主要贡献如下:
创新性方法:通过在时间注意力层计算交叉帧强度,引入增强温度参数,提升帧间一致性与细节表现力。
高效性与通用性:无需训练,直接适配主流视频生成模型。
显著性能提升:在HunyuanVideo等模型上解决了细节缺失和时序不一致等问题。
未来他们还会在此基础上进一步开展工作,包括:
自适应增强:研究自动调节增强温度参数机制,优化一致性与多样性平衡。
扩展适用性:优化方法设计以适配大规模模型和多模态场景。
质量评价:构建更完善的视频生成质量评价体系。
作者表示,期待本研究为AI视频生成技术的实际应用与质量提升提供新的思路和支持!
开源代码链接:https://github.com/NUS-HPC-AI-Lab/Enhance-A-Video
相关博客链接:https://oahzxl.github.io/Enhance_A_Video/
[2]Renze, Matthew and Erhan Guven. “The Effect of Sampling Temperature on Problem Solving in Large Language Models.” ArXiv abs/2402.05201 (2024).
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点这里?关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

内容中包含的图片若涉及版权问题,请及时与我们联系删除
