
然而,生成高质量图像的过程常常需要付出大量的时间和内存,这对于硬件资源有限的设备来说是一大挑战。
为了应对这一问题,北京大学、东北大学、佐治亚大学发布了Stable-Diffusion.cpp(简称Sdcpp)的优化方法,引入了Winograd算法和三个优化策略,最终整图生成速度最高可达到4.79倍,从此实现创作自由!

项目主页:https://github.com/SealAILab/stable-diffusion-cpp
Sdcpp是Stable Diffusion模型的C/C++实现,旨在无需外部依赖的情况下在CPU(以及可能配置GPU)上实现高效推理。Sdcpp作为一个高效的推理框架,不仅能够显著加速模型的运行,还能大幅减少内存占用。
Sdcpp的实现中,计算密集型的2D卷积运算是图像生成的主要瓶颈,虽然功能强大,但效率却不够理想,推理速度较慢,内存占用高。
为了解决这些问题,研究人员在Sdcpp的基础上,引入了Winograd算法,对Sdcpp中的卷积操作进行了革命性的改进,最终实现了性能与资源利用率的双提升。
主要优化策略为:
并行处理:分析算子间的关联性,将关联性较小的运算动态分配到不同的计算线程与核心上,充分利用多线程和多核心架构,动态分配计算任务,充分发挥硬件性能,减少图像生成延迟。
尤其是在M系列Mac设备上,优化了性能核心(P-core)和效率核心(E-core)的分工,使推理速度得到了显著提升。
多设备、多模型支持
扩展模块:如支持LoRA,以及支持算子量化等,为用户提供更高的灵活性。
此外,该框架还支持并且优化了diffusion transformer模型中的算子,进一步拓展了应用场景。
速度提升,快!
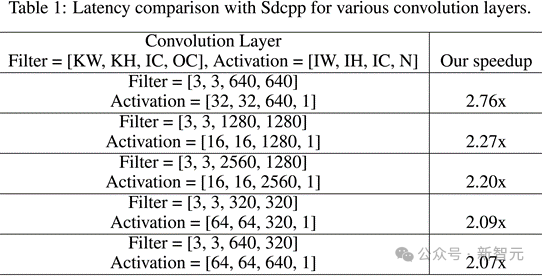
单卷积层的加速表现:对于多种卷积层配置,推理速度平均提升超过2倍!
研究人员测试了在一些在SD生成图片过程中出现比较频繁的卷积层,计算了在这些单卷积层上,优化的Sdcpp相较于原版Sdcpp的加速效果。在不同的卷积层上,推理速度提升至少达到2倍。
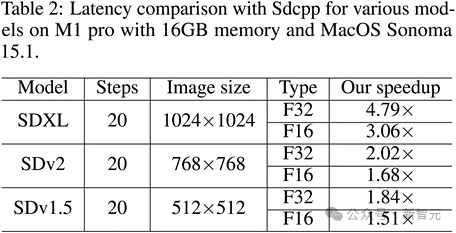
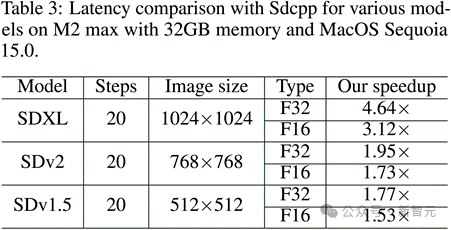
整图生成速度对比:最高加速比达到4.79倍!
图像分辨率越大,方法的加速效果越明显。在生成1024×1024分辨率图像时,相比于原版Sdcpp,优化后的Sdcpp在M1 Pro以及M2 Max上的推理速度提升可超过4.6 倍(FP32 类型)。
对于其他图像尺寸和SD模型,优化的Sdcpp的加速效果也十分显著(如SDv1.5模型生成512×512图像时在M1 Pro上加速1.84 倍)。
显著的加速比主要得益于框架的局部优化(降低缓存交换并且提高内存使用效率),以及并行处理(动态分配计算任务并且提高运算并行度)。
更快的速度,不仅节省时间,更让创作更自由!
实例展示:更真实的生成效果

可以看出,在相同配置和提示词下,优化后的Sdcpp不仅速度更快,生成的图像也更加细腻逼真,细节丰富,层次分明。
优化的Sdcpp能够支持不同硬件平台上(Mac、Android、AMD 等)各种主流SD模型(如SDv1.4、v1.5、v2.1、SDXL 和 SDXL-Turbo)的所有算子,确保使用这些SD模型能够生成高质量的图片。
该框架还会不断进步,研究人员计划优化更多操作符,提升兼容性;进一步提高模型量化的效率;探索在更多设备上的性能提升。



内容中包含的图片若涉及版权问题,请及时与我们联系删除
