
Published on December 23, 2024 7:35 PM GMT
As most of you know, openAI has recently showcased o3's SOTA results on various benchmarks. In my opinion FrontierMath was the hardest of the bunch, and it was reflected in model performance as the SOTA was 2% before Friday. It also seems to be the benchmark with the least visibility. To set the scene, Chollet and the ARC-AGI group were very forthcoming with their thoughts on o3's performance, and even published the model training set and the results on github. People have got a chance to engage with the training set, and even argue potential ambiguities. The upshot of this discussion is that there is a lot of data surrounding the ARC-AGI benchmark.
OTOH, there is a dearth of discussion wrt FrontierMath. I think people genuinely don't understand the benchmark, and get oneshotted by the hard math problems it advertises. I understand that people see the jump from 2% -> 25% as impressive, and I do too. I am just not sure at what we're actually measuring, or whether models are actually getting better at math. It's for a very simple reason: coming up with an answer is the easy part, coming up with a solution is the hard part.
I'm not sure if people know, but Elliot Glazer has actually commented on the old 2% SOTA in an AMA on reddit:
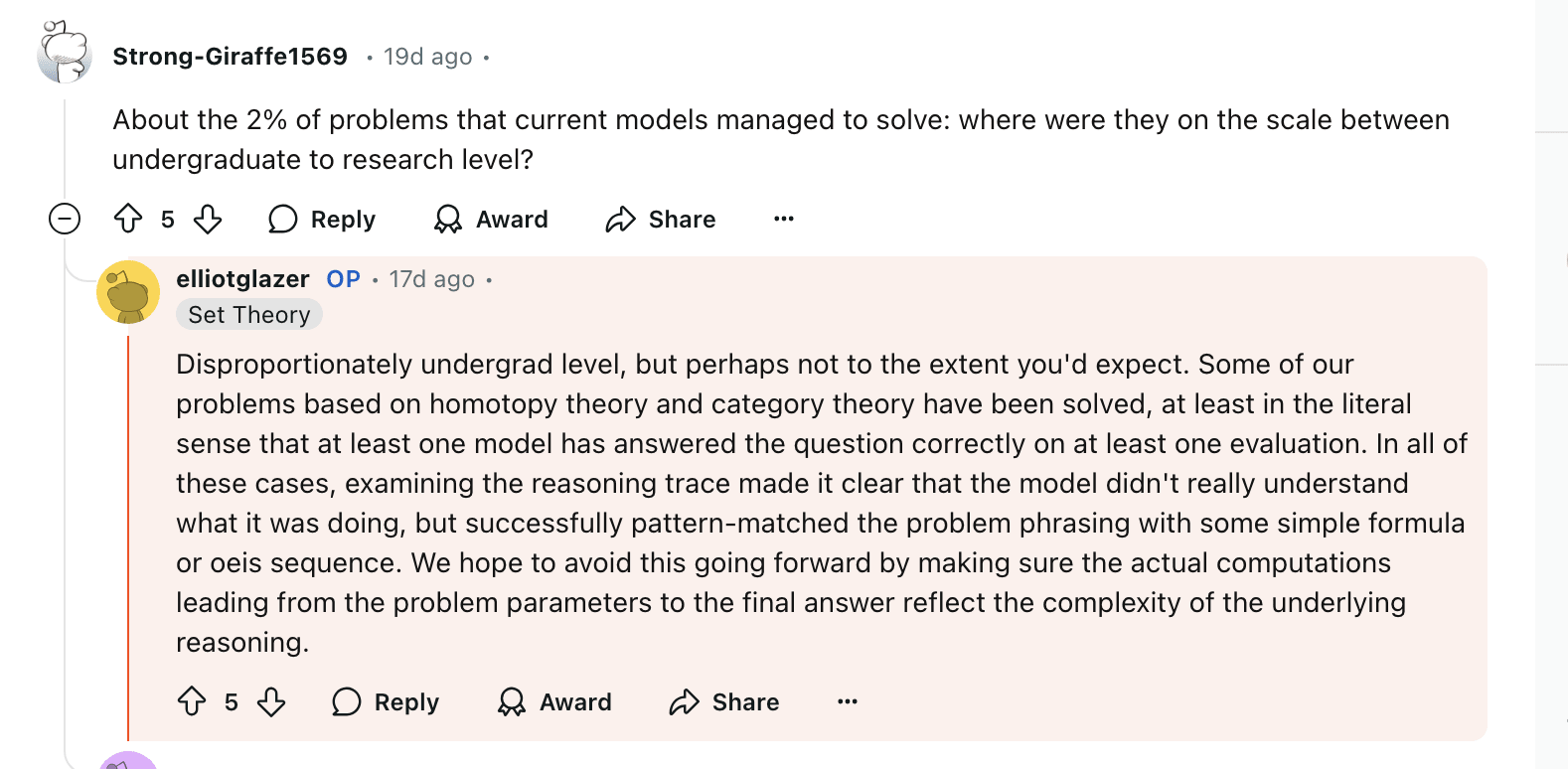
I don't find that there is are 3 tiers of problems to be an issue at all, other than openAI has not (to my knowledge) published which tier of problems o3 has solved. Moreover, models are not actually required to "understand" the problem and the solution to come up with an answer. Thus, it's not clear to me that the increased FrontierMath SOTA represents such a large increase in the mathematical capabilities of the models. There is a severe lack of qualitative review of the reasoning traces of o3, and it just seems like people are uncritically accepting the increased performance without questioning what it actually represents.
I of course understand that there is a need for privacy with these models - if the problems get published then the benchmark will be soiled. I think this is a sign that FrontierMath is ultimately not a good benchmark for truly measuring math ability of models. I don't get why there needs to be a middleman in the form of a benchmark. Actually, this has been discussed by Elliot Glazer:
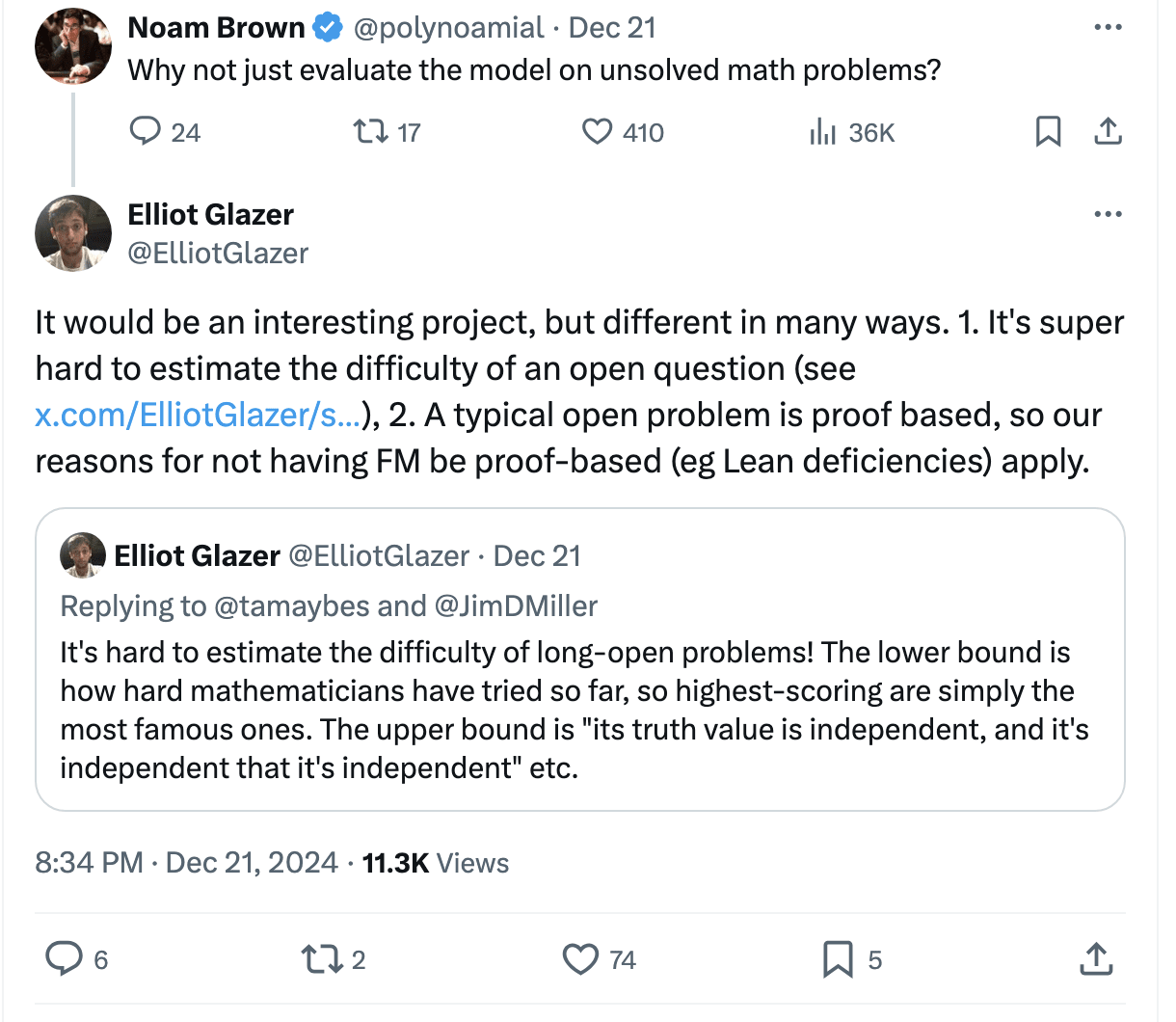
To be blunt, I don't think these are very good reasons for FrontierMath as
1. Why do we need to estimate the difficulty of open problems? There is a common sentiment in math that there are "no low hanging fruit" and there is some truth to this claim. Open problems sit at the cusp of math knowledge these days, so unless you're highly specialized you're probably not finding + solving them. If a model can solve any open problem, regardless of "difficulty", then it has proved its capability. In short, this requirement seems contrived.
2. (Apologies, I get a bit more pie in the sky here.) The reasons for not having FM be proof-based are as follows:

The first point seems weak, as you could argue that doing math is a skill rather than a reflection of "genuine reasoning skills". The second point strikes a pet peeve of mine: the overreliance of Lean in the broad math community. It seems to be the only proof assistant that people know. I don't particularly like it, nor do I like Coq, as these proof assistants feel a little alien compared to how I actually do math. The missing undergraduate math topics in Lean:

seem to reflect a fundamental difference between the proof assistant and doing actual math. All of this should be easy to do in Lean. In all honesty, a motivated highschooler should be able to formalize these concepts. In reality, they can do it for low dimensional matrices but cannot generalize the operations to arbitrary dimensions. I think the only explanation of this is sunk-cost fallacy. There are people working today on better languages for doing math. I am sure many of you roll your eyes at "homotopy type theory". I am extremely bullish on its younger but burgeoning sibling: directed type theory. In particular, something like a directed higher inductive type makes it way more logical to describe categorical structure that exists in matrices. The author of this thesis uses untyped lambda calculus as an example of structure that can be modeled with DHITs. If you understand what he's saying, you can very quickly imagine that it wouldn't be much work to model matrices and other 1-categorical objects. Unfortunately, it doesn't exist yet. Thankfully, people are working on that!
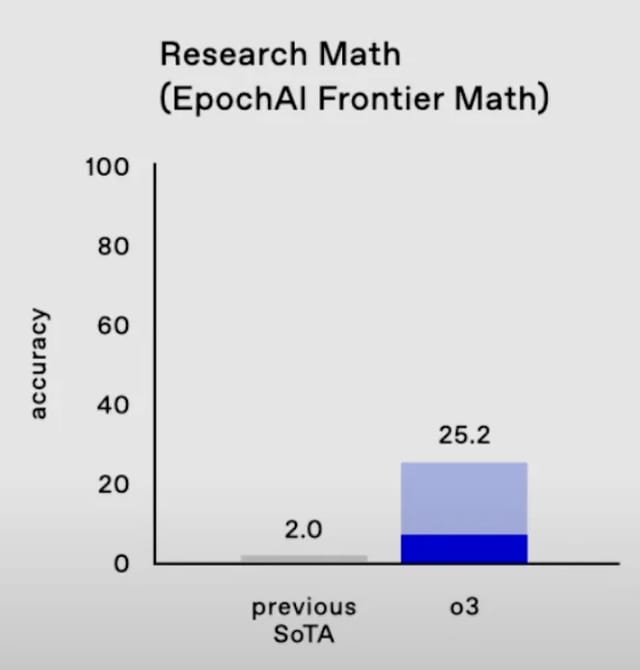
All in all, I really wish that people were a little more critical on FrontierMath for no other reason than an eagerness to push the boundaries on human knowledge to the limit. Part of that, though, requires participation on part of openAI to be completely forthcoming about their performance on benchmarks. A simple bar graph like this:
doesn't really cut it for me. It doesn't have to, of course.
Discuss
