index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
本次Datawhale分享活动中,科大讯飞MaaS平台总监张林芳老师深入剖析了大模型的技术革新与应用突破。分享内容涵盖大模型的发展趋势、落地应用路径以及精调实践。他指出,开发者是推动大模型应用的关键力量,并详细介绍了如何通过技术大模型阶段、通用大模型+X阶段,以及精调等方法实现大模型的快速落地。其中,数据构建、模型选择、训练与评估是精调的关键环节。他还强调,没有“最好”的模型,只有“最适合”的模型。此次分享为AI技术爱好者提供了宝贵的实践经验和深入思考。
🚀大模型技术正以惊人的速度重塑生活与工作方式,开发者是推动其应用的关键力量,通过创新的产品形态满足了更多人的实际需求,催生了AI应用工程师这一新兴职业。
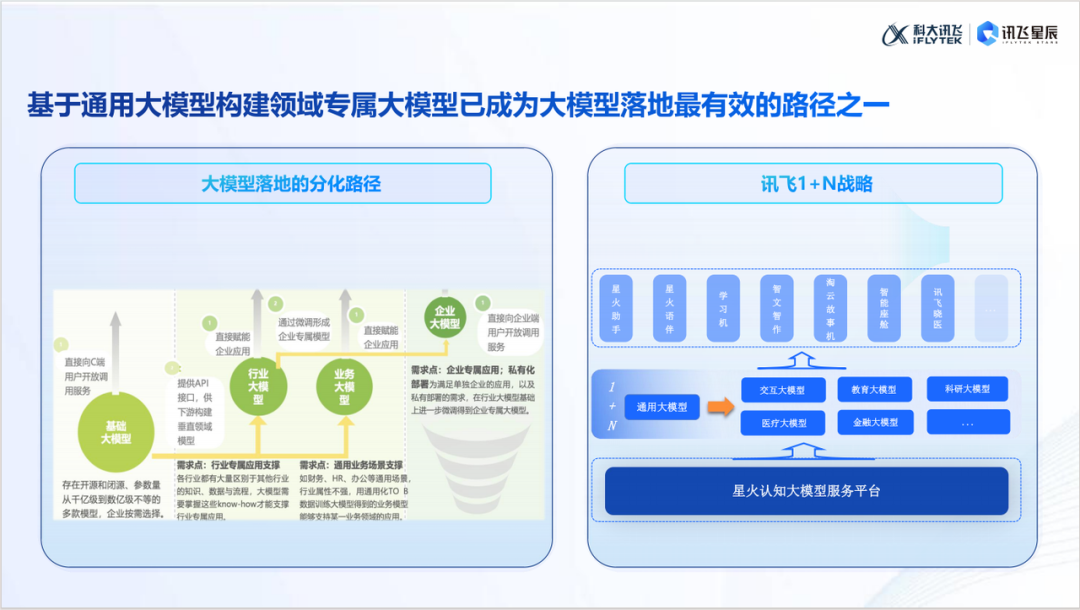
💡大模型的落地应用路径包括:构建开放性强的通用大模型,服务C端用户,并为开发者提供API接口;针对特定场景或行业进行优化,如行业优化、场景定制和企业定制;通过结合行业数据与场景需求,基于通用模型快速构建专属解决方案。
⚙️大模型精调是实现特定领域深度应用的关键,包括预训练(奠定基础知识)、精调(针对特定领域优化)、SFT(监督微调),以及使用JSON格式组织数据。数据构建需明确需求、多样化输入、标准化输出。模型选择需考虑场景适配性、模型尺寸与性能、数据量级需求,以及训练成本与时长。模型训练与评估需监控训练进度,使用自动化指标和人工检查。
12 月 11 日,AI 冬令营的首场直播分享活动顺利举行,吸引了约 8000 名 AI 技术爱好者参与。作为冬令营系列活动的起始,此次分享以通俗易懂的方式解读技术,极大地激发了观众对大模型应用的想象空间。科大讯飞 MaaS 平台总监张林芳老师受邀出席,以企业的视角,为我们剖析了大模型未来的发展走向以及技术应用的关键要点。其分享涵盖从行业趋势到实践经验等多方面内容,带来了诸多有价值的启示与深入的思考。 
近年来,大模型技术迅猛发展,从 ChatGPT 到星火大模型,它们正在以惊人的速度重塑我们的生活与工作方式。自 2022 年 11 月发布以来,ChatGPT 在短短两个月内用户量突破 1 亿,而今年 5 月的访问量更是达到 23 亿次,日均调用 7700 万次。同样,星火大模型也在多个应用场景中实现了调用量的爆发式增长。
张林芳老师指出,推动这一增长的关键力量是开发者,他们通过创新的产品形态,将 AI 技术逐步渗透到生活的方方面面,满足了更多人的实际需求。这一趋势也催生了一个全新的职业方向——AI 应用工程师。在不久的将来,AI 应用工程师将成为推动行业变革的重要角色,他们通过精通大模型技术,解决产业痛点,创造实际价值。 如何让大模型快速落地?张林芳老师从技术发展路径出发,为我们描绘了清晰的应用蓝图:
技术大模型阶段 这一阶段的核心是构建开放性和适应性强的通用大模型,既服务于 C 端用户的日常需求(如星火 APP),也为开发者通过 API 接口实现多场景应用提供基础支持。
通用大模型 + X 阶段 此阶段大模型逐步结合特定场景或行业需求,形成以下三种主要应用方向:
行业优化:融入行业专属数据,为金融、医疗等垂直领域提供更精准的解决方案。
场景定制:围绕业务场景优化,如办公协作和财务管理,满足广泛的需求。
企业定制:根据企业专属需求开发,提升数据处理和内部效率。
张老师指出,行业巨头倾向于开发通用大模型以占据市场高地,而创业公司则更适合聚焦垂直领域,解决特定场景的核心问题。通过结合行业数据与场景需求,基于通用模型快速构建专属解决方案,是推动大模型高效落地的关键策略。
要实现大模型在特定领域的深度应用,精调是必不可少的关键环节。张林芳老师通过深入浅出的讲解,帮助我们理解精调过程中的核心概念:
预训练:相当于为模型奠定基础知识。通过大量通用数据的训练,模型具备了广泛的理解和生成能力。
精调:在预训练模型的基础上,针对特定领域或任务进行深度优化,使其更契合实际应用需求。
SFT(监督微调):通过高质量的训练数据指导模型学习,帮助其提升特定任务的表现。
JSON 格式:用于组织和呈现数据的标准形式,通过清晰的结构化设计,帮助模型更高效地理解和处理信息。
从数据构建到模型评估,大模型精调的全过程需要系统化的规划和强大的执行力。通过精调,可以让通用模型成为特定领域的“专家”,从而实现从理论到应用的全面突破。
在大模型精调过程中,数据构建是最重要的基础环节,高质量的数据直接决定了模型的性能和适用范围。为了确保精调的效果,张林芳老师总结了以下关键原则: 明确数据需求:数据内容需逻辑清晰且信息完整,以确保训练数据符合模型预期的输出目标。多样化数据输入:增加表达方式的多样性,提升模型的泛化能力,使其能适应更多实际场景。标准化输出:采用如 JSON 格式等结构化形式整理数据,降低模型的理解复杂度,提升回应的准确性。
此外,辅助工具的应用能够显著提升数据构建的效率。例如,问答对抽取工具可以从文本中提取关键问答对,适合对话系统或问答场景;数据增强工具则通过扩展数据规模和多样性,有效应对原始数据不足的情况,从而提升模型的泛化能力。 模型选择是大模型精调的基础环节之一,不同的任务场景和数据特点需要匹配合适的模型。张林芳老师强调,没有“最好”的模型,只有“最适合”的模型。以下是选择模型时的关键考虑因素:
为了满足不同开发者的需求,讯飞星辰平台提供了两种精调工具模式: 低代码精调:适合新手和快速开发场景,仅需调整核心变量即可完成模型精调。Notebook 模式:为有技术基础的开发者提供完全可控的精调环境,可深入调整所有训练参数。
通过灵活选择模型和工具,开发者能够有效降低训练成本,同时确保模型在特定场景中的卓越表现。 大模型的训练与评估是将数据与模型结合的关键步骤,也是优化模型效果的重要环节。整个过程可以分为四个阶段: 准备阶段:包括数据构建和模型选择。这一步为后续训练奠定了坚实的基础。训练阶段:需要配置训练环境(如 GPU/TPU 平台)、调整训练参数(如学习率、Batch Size、Epoch 等),并根据任务类型(如文本生成、意图分类、实体抽取等)设计训练任务。结果检查:实时监控训练进度,观察损失曲线的变化。一条理想的曲线应呈现出快速下降后逐渐平稳的趋势,避免出现过拟合等问题。输出模型:完成训练后,将精调模型保存为可用的文件格式,供后续应用。
在评估阶段,除了通过损失曲线判断训练效果外,还可以结合自动化指标(如准确性、鲁棒性、效率等)和人工检查来确保模型的表现达到预期。例如,在深圳地铁购票的意图识别场景中,微调后的小模型不仅将分类准确率提升了 30%,还显著降低了 95% 的成本,实现了效能和经济性的双赢。 通过张林芳老师的详细讲解,我们了解了大模型精调的核心步骤和实践路径。从数据构建到模型选择,再到训练与评估,每一个环节都环环相扣,最终实现模型在特定场景中的高效应用。然而,学习大模型精调并不仅仅停留在理论层面,动手实践才是将知识转化为能力的关键。 Datawhale AI 冬令营是一个在冬季举办的大规模 AI 学习活动,旨在汇聚产学研资源和开源社区力量,为学习者提供丰富的学习和实践机会,提升他们的专业能力和就业竞争力。第二期冬令营报名将于 12 月 22 日正式启动,如果你也希望掌握最新 AI 应用的核心技能,欢迎关注公众号信息。
教程开源地址:
http://www.datawhale.cn/learn/summary/72https://training.xfyun.cn/?ch=maas-dw-mxb 一起“点赞”三连↓
一起“点赞”三连↓ 内容中包含的图片若涉及版权问题,请及时与我们联系删除