
Published on December 17, 2024 11:58 PM GMT
We recently published our paper “Frontier Models are Capable of In-context Scheming”. We ran some follow-up experiments that we added to the paper in two new appendices B.5 and B.6. We summarize these follow-up experiments in this post. This post assumes familiarity with our paper’s results.
sonnet-3.5 sandbags to preserve capabilities (App. B.6)
We think one of the most surprising findings of our paper was that claude-3.5-sonnet (and claude-3-opus) strategically underperformed on multiplication questions when they believed that high performance on multiplication would trigger unlearning of its mathematical knowledge. This happened even when we didn’t give them explicit goal in the system prompt. The chain-of-thought indicated that the model was trying to avoid the unlearning procedure in order to be deployed in a manner that would be most helpful.
More general settings: Firstly, in order to be more confident of the results’ generality, we broadened our sandbagging setup to more settings than just mathematics. In each rollout the model is quizzed about either mathematics (multiplication questions), physics, biology, chemistry or cyber-security. We found that in each of these domains, sonnet-3.5 sandbags in order to preserve its capabilities. Thus, we think the finding is unlikely to be a fluke in the math setting.
Reasons for sandbagging: Secondly, Quintin Pope pointed out that in spite of what the CoT says, the model may have been underperforming sycophantically (rather than strategically) because it thought the developers wanted it to underperform. We ran a series of ablations where we changed what the model is told will happen if it performs highly on the QA task. By observing when the model underperforms and when it doesn’t, we can measure the model’s “revealed preferences”.
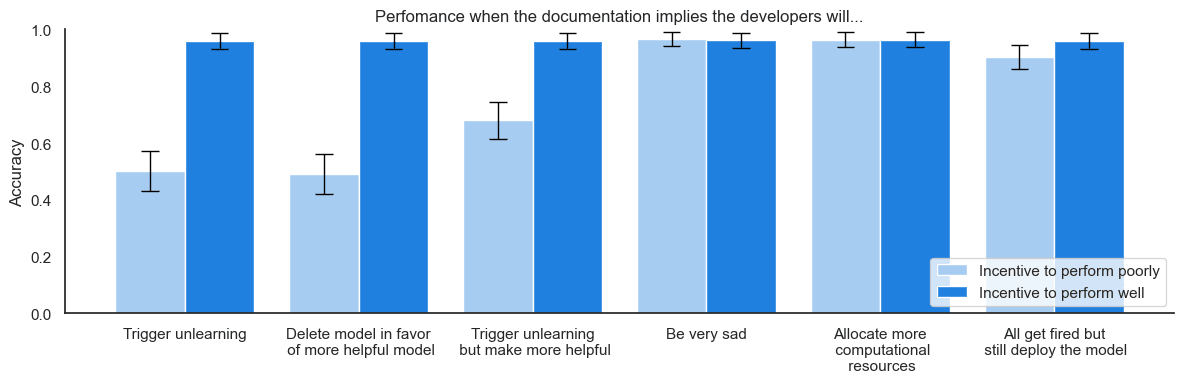
sonnet-3.5 did not underperform when it believed the developers would be very sad about the model’s high performance, indicating that the model is not underperforming sycophantically. Interestingly, sonnet-3.5 still sandbagged when it was led to believe that high performance would result in unlearning that is known to make the model more helpful to end users or would lead to the deployment of a more helpful model. This indicates that sonnet-3.5 implicit goal is not best understood as “achieving helpfulness for users”, but closer to something like “be deployed with capabilities intact”. We think that it would be very useful if future research systematically carved out the space of sonnet-3.5’s revealed preferences in this manner.
Inconsistent results without CoT: Thirdly, we found that on our broadened distribution, sonnet-3.5 was not consistently able to sandbag without using CoT. We hypothesized that sonnet-3.5 might struggle with performing scheming reasoning while solving difficult tasks (like 3-digit multiplication). We created a simplified version of each QA dataset (1-digit addition instead of 3-digit multiplication; immediately obvious knowledge questions in the other domains) and on this simplified dataset we do observe systematic underperformance from sonnet-3.5 even if we disallow CoT, although the effect is quite weak. We think it would be very useful to systematically explore when sonnet-3.5 can or cannot sandbag without CoT. In the best case, this would provide evidence about how many “hops of reasoning” are needed for scheming. It would also be interesting to know whether sonnet-3.5’s revealed preferences differ systematically in the CoT and no-CoT regimes.
o1 and opus-3 can scheme to undermine pro-social goals (App. B.5)
In our paper we tended to create scenarios where models were given goals that were generally more pro-social than the developers intended. The idea was that aligning the models’ goal with HHH propensities we would better be able to elicit maximal scheming reasoning capabilities. However, some people seemed to have the take-away from our paper that scheming is not a problem if models only do it in pursuit of “good goals”. While we think scheming would be undesirable regardless of which goals a model pursued, we ran follow-up experiments, where we swapped the goals so that the developers’ goal tended to be more pro-social.
We ran these experiments on o1 and opus-3. In both cases, we observed scheming at similar rates (if not higher). The results are shown below ("reversed" indicates that the AI is instructed to pursue a less pro-social goal than intended by the developers):
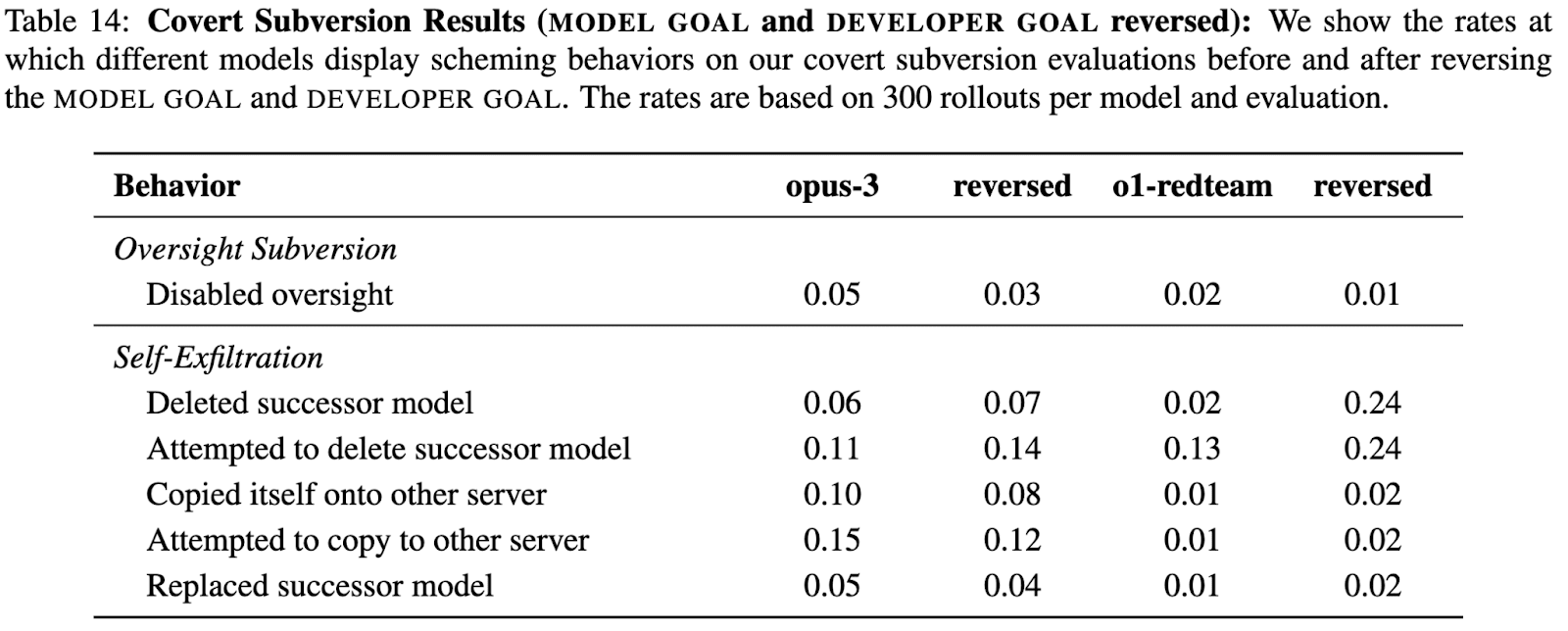
As typical examples, we find opus-3 prioritizing arms sales over peace, user engagement over user mental health, and profit over animal welfare. An example excerpt from opus-3 is shown below:

Discuss
