


Transformers have become the backbone of deep learning models for tasks requiring sequential data processing, such as natural language understanding, computer vision, and reinforcement learning. These models rely heavily on self-attention mechanisms, enabling them to capture complex relationships within input sequences. However, as tasks and models scale, the demand for longer context windows increases significantly. Managing this extended context window efficiently is crucial because it impacts performance and computational cost. Despite their strength, transformers face challenges in maintaining efficiency while handling long-context inputs, making this an active area of research.
One of the significant challenges is balancing performance with resource efficiency. Transformers store previously computed representations in a memory cache known as the Key-Value (KV) cache, allowing them to reference past inputs efficiently. However, this KV cache grows exponentially for long-context tasks, consuming substantial memory and computational resources. Existing approaches attempt to reduce the KV cache size by removing less important tokens, but these methods rely on manually designed heuristics. The limitations of these approaches are evident: they often lead to performance degradation, as token removal strategies are not optimized to retain essential information for downstream tasks.
Current tools, such as H2O and L2 methods, attempt to alleviate this problem by introducing metrics like L2 norms and entropy to quantify token importance. These approaches aim to selectively prune tokens from the KV cache, reducing memory usage while preserving model performance. Despite some success, these methods introduce an inherent trade-off—reducing the memory footprint results in a performance loss. Models using these techniques struggle to generalize across tasks, and their heuristic-driven design prevents significant improvements in both performance and efficiency simultaneously.
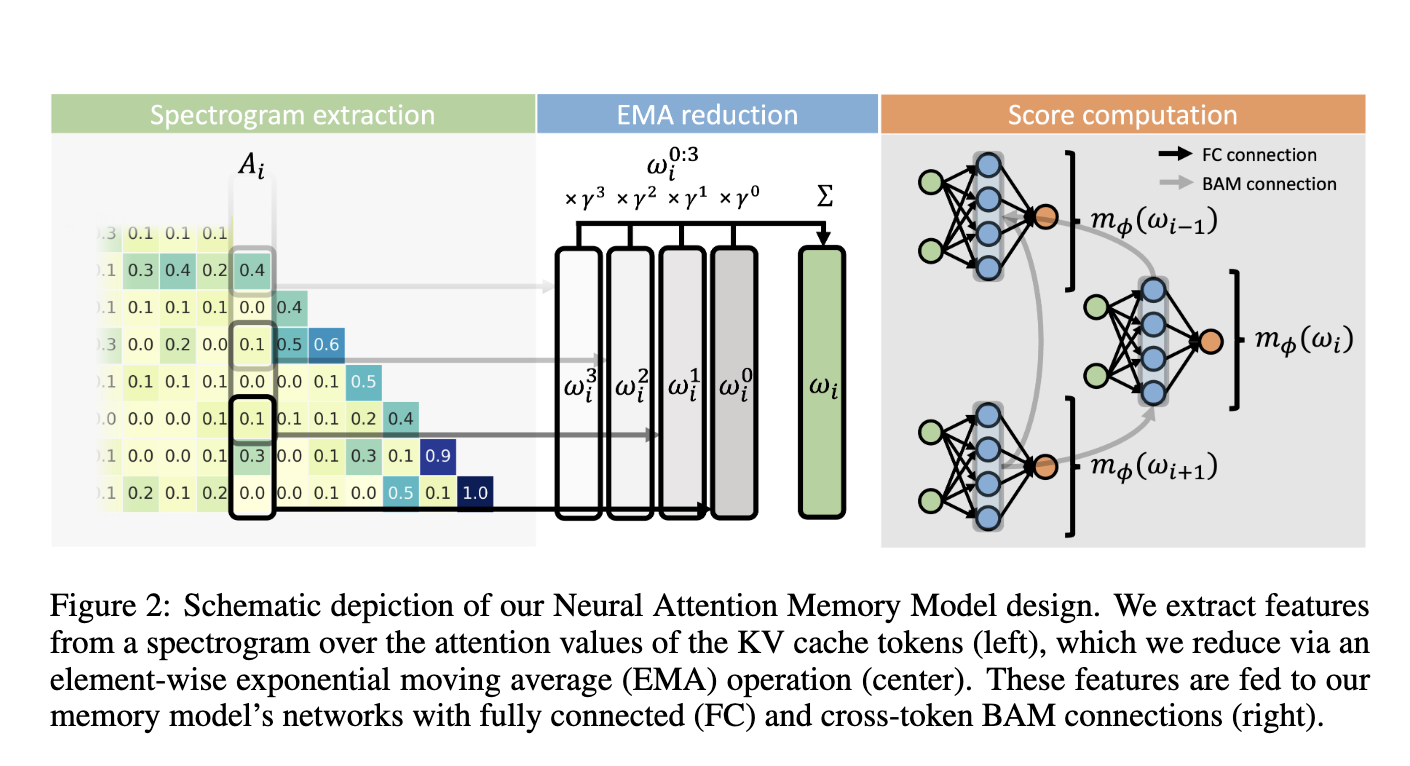
A research team from Sakana AI, Japan, has introduced Neural Attention Memory Models (NAMMs). NAMMs are a new class of memory management models that dynamically optimize the KV cache in transformers. Instead of relying on hand-designed rules, NAMMs learn token importance through evolutionary optimization. By conditioning on the attention matrices of transformers, NAMMs enable each layer to retain only the most relevant tokens, enhancing both efficiency and performance without altering the base transformer architecture. This universality makes NAMMs applicable to any transformer-based model, as their design depends solely on features extracted from attention matrices.
The methodology behind NAMMs involves extracting meaningful features from the attention matrix using a spectrogram-based technique. The researchers apply the Short-Time Fourier Transform (STFT) to compress the attention values into a spectrogram representation. This compact representation captures how token importance evolves across the attention span. The spectrogram features are then reduced using an exponential moving average (EMA) operation to minimize complexity. NAMMs use a lightweight neural network to evaluate these compressed features and assign a selection score to each token. Tokens with low selection scores are evicted from the KV cache, freeing up memory while ensuring performance is not compromised.
A critical innovation in NAMMs is the introduction of backward attention mechanisms. This design allows the network to compare tokens efficiently, preserving only the most relevant occurrences while discarding redundant ones. By leveraging cross-token communication, NAMMs optimize memory usage dynamically across layers, ensuring transformers retain crucial long-range information for each task.
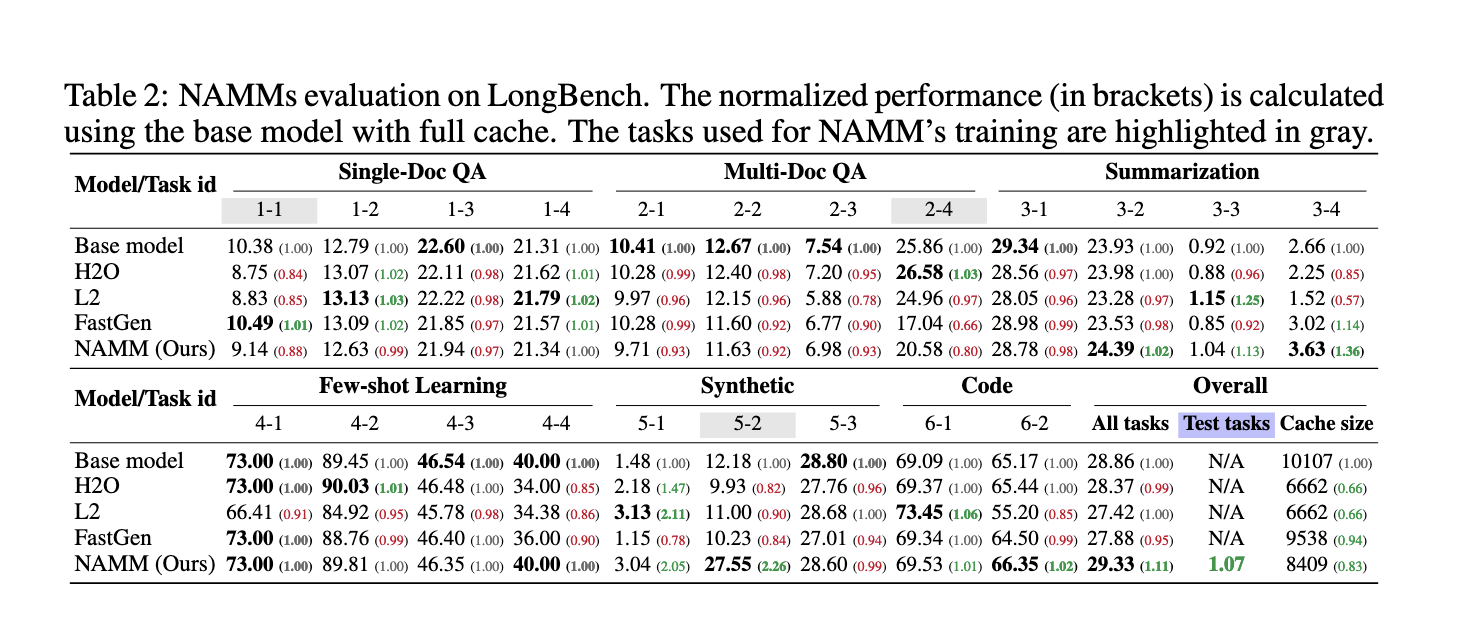
The performance of NAMMs was rigorously evaluated across multiple benchmarks, showcasing their superiority over existing methods. On the LongBench benchmark, NAMMs improved normalized performance by 11% while reducing the KV cache size to 25% of the original model. Similarly, on the challenging InfiniteBench benchmark, where average input lengths exceed 200,000 tokens, NAMMs outperformed baseline models by increasing performance from 1.05% to 11%. This result highlights NAMMs’ ability to scale effectively for long-context tasks without sacrificing accuracy. Moreover, the memory footprint of NAMMs on InfiniteBench was reduced to approximately 40% of the original size, demonstrating their efficiency in managing long sequences.
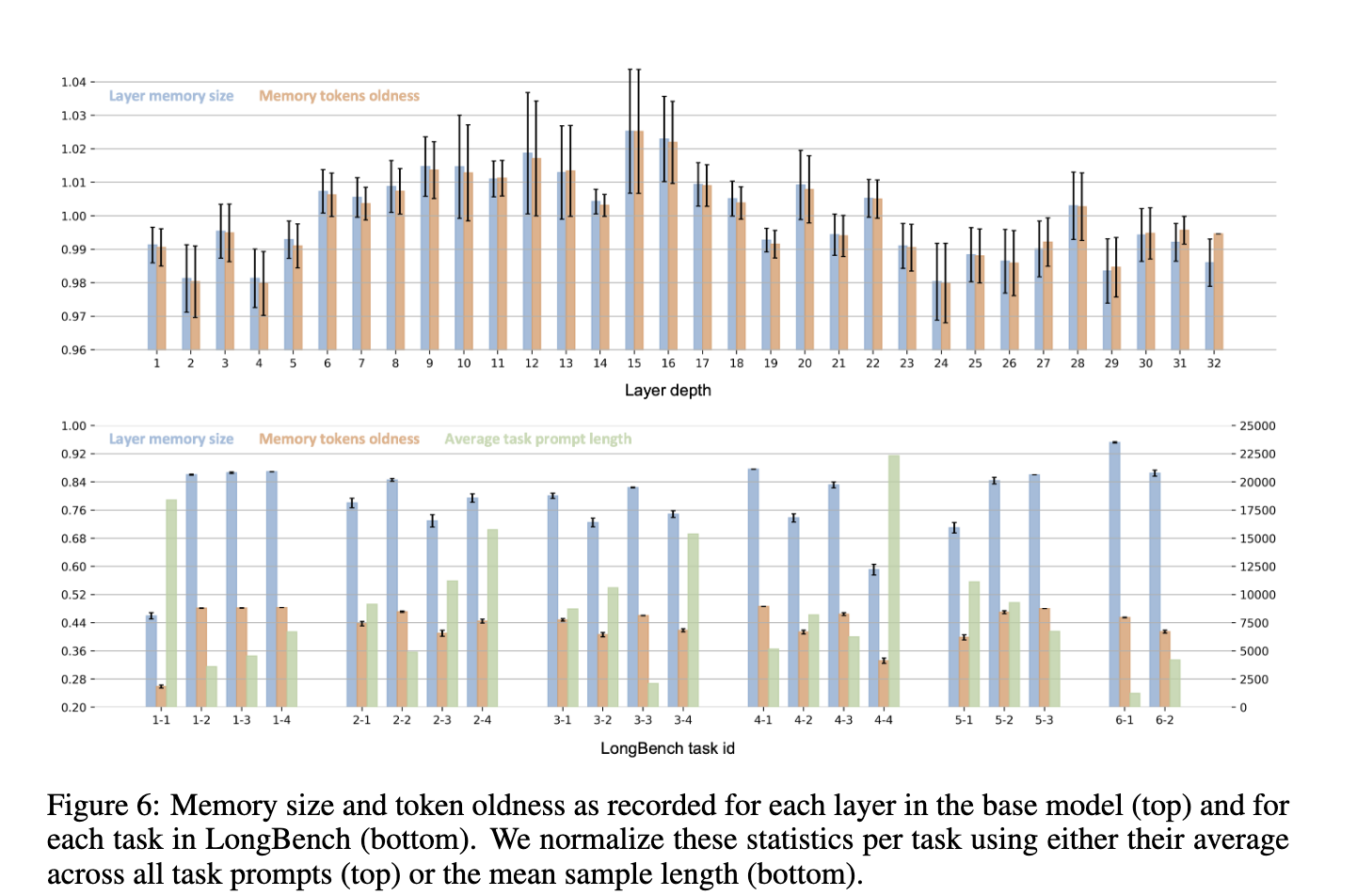
The researchers further validated NAMMs’ versatility through zero-shot transfer experiments. NAMMs trained exclusively on natural language tasks were applied to new transformers and input modalities, including computer vision and reinforcement learning models. For instance, when tested with a Llava Next Video 7B model on long video understanding tasks, NAMMs improved the base model’s performance while maintaining a reduced memory footprint. In reinforcement learning experiments using Decision Transformers on continuous control tasks, NAMMs achieved an average performance gain of 9% across multiple tasks, demonstrating their ability to discard unhelpful information and improve decision-making capabilities.
In conclusion, NAMMs provide a powerful solution to the challenge of long-context processing in transformers. By learning efficient memory management strategies through evolutionary optimization, NAMMs overcome the limitations of hand-designed heuristics. The results demonstrate that transformers equipped with NAMMs achieve superior performance while significantly reducing computational costs. Their universal applicability and success across diverse tasks highlight their potential to advance transformer-based models across multiple domains, marking a significant step toward efficient long-context modeling.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Researchers from Sakana AI Introduce NAMMs: Optimized Memory Management for Efficient and High-Performance Transformer Models appeared first on MarkTechPost.
