字节跳动豆包大模型团队在NeurIPS 2024大会上成果丰硕,共有超过20篇论文入选。本次直播将由豆包大模型视觉基础研究负责人冯佳时等五位资深研究员,深度解析多项前沿研究成果,包括解决图像视频内容一致性的StoryDiffusion、加速扩散模型的Hyper-SD、多维度评估口语对话的SD-Eval、单目深度估计模型Depth Anything,以及高效预训练方法SuperClass。直播期间还将有多轮抽奖互动,不容错过。
✨StoryDiffusion:该研究主要探讨生成图像视频时内容一致性问题,其创新性使其在NeurIPS 2024中被评为Spotlight,录取率仅为2.4%。
🚀Hyper-SD:这项研究致力于加速扩散模型,实现最快一步生成SOTA级图片,其在GitHub上的下载量已超过百万,显示了其广泛的受欢迎程度。
🗣️SD-Eval:该研究构建了一个多维度评估口语对话理解和生成的基准数据集,该数据集涵盖情感、口音、年龄和背景音四个视角,为口语对话研究提供了重要工具。
👁️Depth Anything:这是一个单目深度估计模型系列工作,在GitHub上获得了1.2万的Star,表明其在深度估计领域的显著影响力。
💡SuperClass:该研究提出了一种简单高效的预训练方法,首次舍弃了文本编码器,其训练效率高于CLIP,为预训练模型提供了新的思路。
2024-12-17 18:04 重庆
NeurIPS 2024 刚刚在温哥华落幕,大会汇聚了全球顶尖 AI 研究成果,字节跳动豆包大模型团队超 20 篇论文中选,在多个前沿领域成果亮眼。
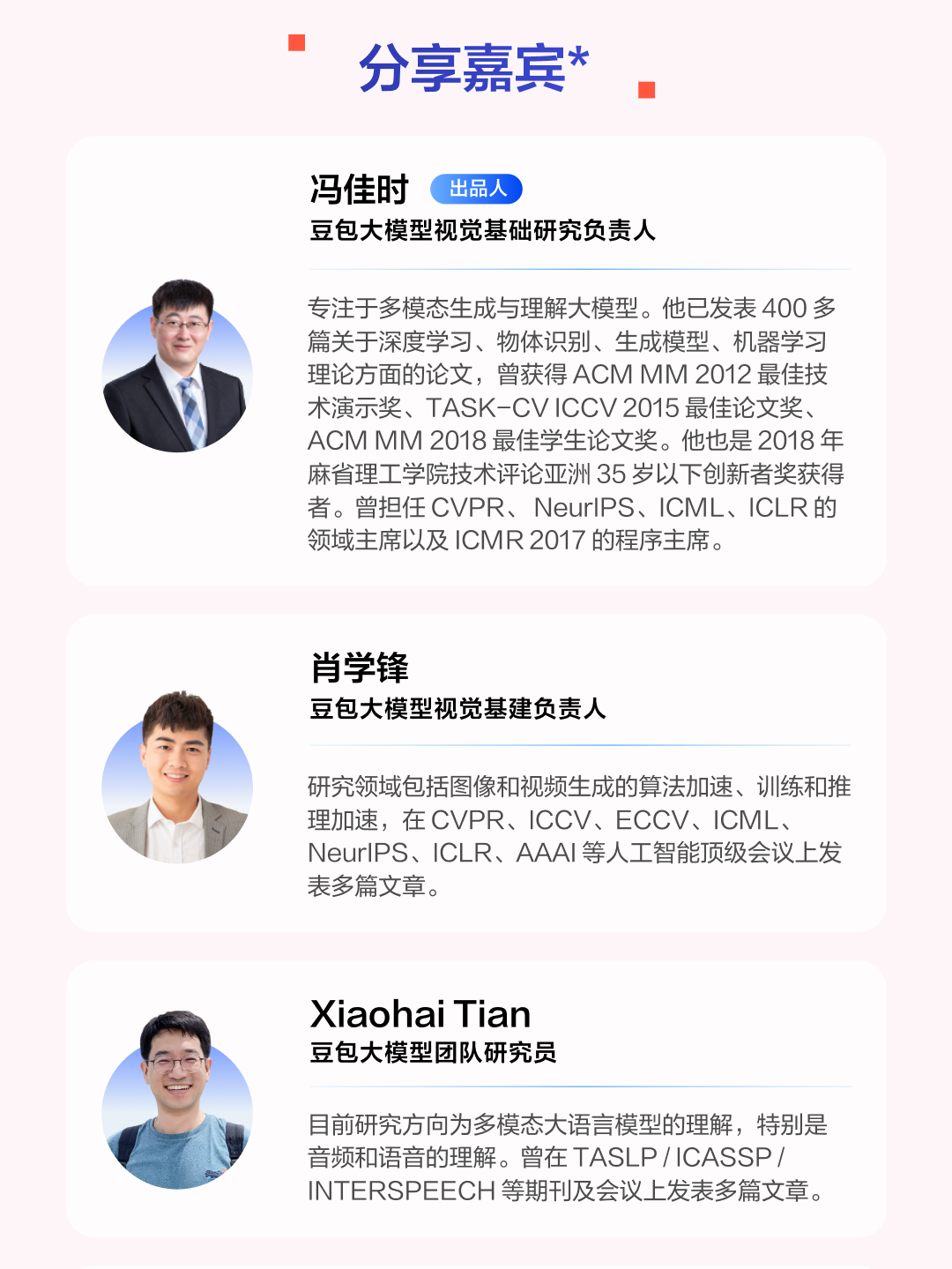
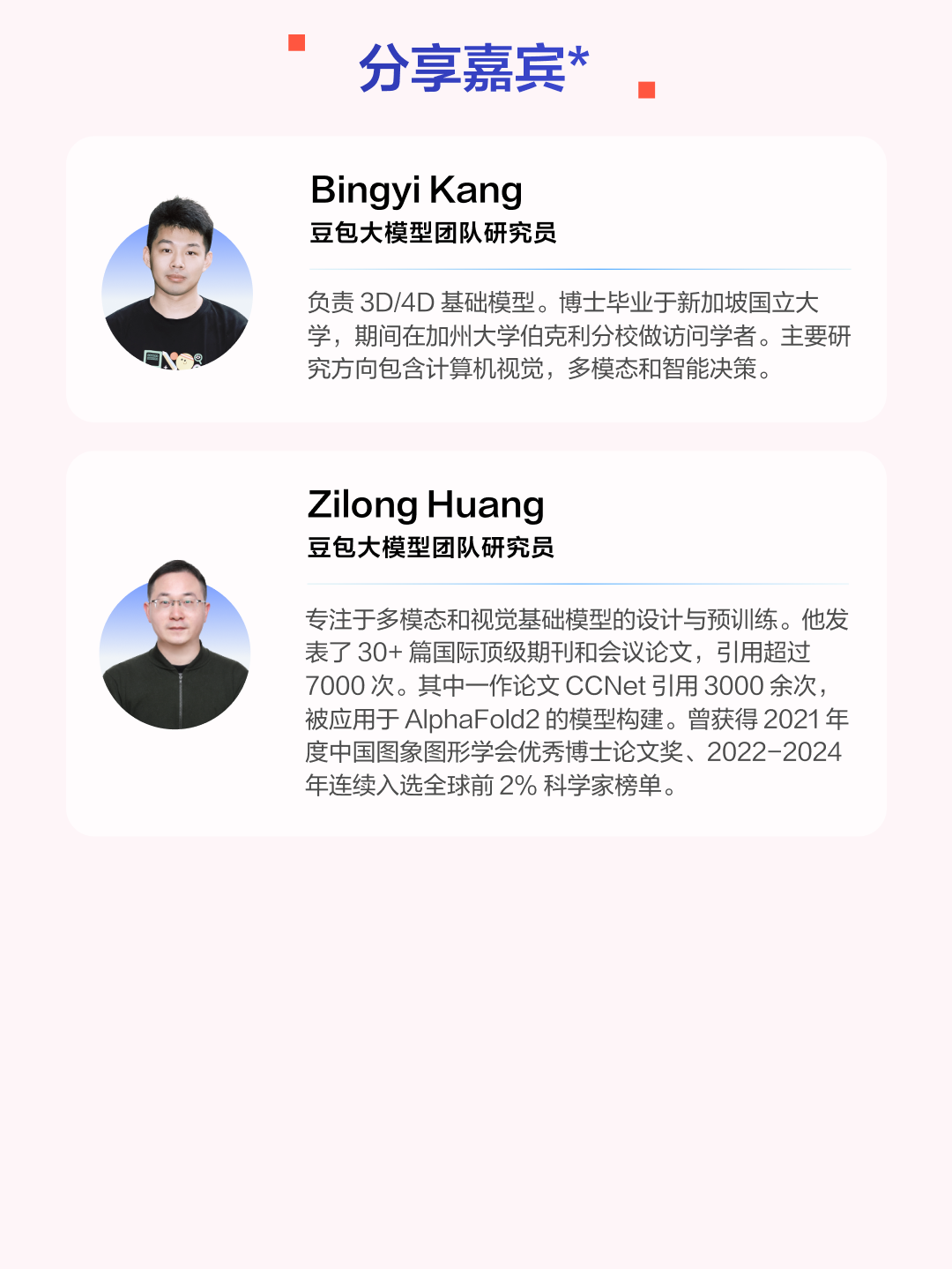
今晚 7 点,豆包大模型视觉基础研究负责人冯佳时、视觉基建负责人肖学锋,携手三位资深研究员 Xiaohai Tian、Bingyi Kang、Zilong Huang,为大家深度解析下述研究成果:
✨StoryDiffusion:探讨生成图像视频时内容一致性问题,该工作被评为 Spotlight,录取率仅为 2.4% 。
✨Hyper-SD:加速扩散模型,最快 1 步生成 SOTA 级图片,GitHub 下载量超百万。
✨SD-Eval:多维度评估口语对话理解和生成的基准数据集,涵盖情感、口音、年龄和背景音四个视角。
✨Depth Anything:单目深度估计模型系列工作,目前 GitHub Star 1.2 万。
✨SuperClass:简单高效的预训练方法,首次舍弃文本编码器,训练效率高于 CLIP。
直播期间,我们还将进行多轮互动抽奖,礼品等你来拿!
今晚 7 点,快来和研究员们一起唠唠吧[让我看看]



跳转微信打开

