


AI systems are progressing toward emulating human cognition by enabling real-time interactions with dynamic environments. Researchers working in AI aim to develop systems that seamlessly integrate multimodal data such as audio, video, and textual inputs. These can have applications in virtual assistants, adaptive environments, and continuous real-time analysis by mimicking human-like perception, reasoning, and memory. Recent developments in multimodal large language models (MLLMs) have led to significant strides in open-world understanding and real-time processing. However, challenges still need to be solved in developing systems capable of simultaneously perceiving, reasoning, and memorizing without the inefficiencies of alternating between these tasks.
Most mainstream models need to be improved because of the inefficiency of storing large volumes of historical data and the need for simultaneous processing capabilities. Sequence-to-sequence architectures, prevalent in many MLLMs, force a switch between perception and reasoning like a person cannot think while perceiving their surroundings. Also, reliance on extended context windows for storing historical data could be more sustainable for long-term applications, as multimodal data like video and audio streams generate massive token volumes in hours, let alone days. This inefficiency limits the scalability of such models and their practicality in real-world applications where continuous engagement is essential.
Existing methods employ various techniques to process multimodal inputs, such as sparse sampling, temporal pooling, compressed video tokens, and memory banks. While these strategies offer improvements in specific areas, they fail to achieve true human-like cognition. For instance, models like Mini-Omni and VideoLLM-Online attempt to bridge the text and video understanding gap. Still, they are constrained by their reliance on sequential processing and limited memory integration. Moreover, current systems store data in unwieldy, context-dependent formats that need more flexibility and scalability for continuous interactions. These shortcomings highlight the need for an innovative approach that disentangles perception, reasoning, and memory into distinct yet collaborative modules.
Researchers from Shanghai Artificial Intelligence Laboratory, the Chinese University of Hong Kong, Fudan University, the University of Science and Technology of China, Tsinghua University, Beihang University, and SenseTime Group introduced the InternLM-XComposer2.5-OmniLive (IXC2.5-OL), a comprehensive AI framework designed for real-time multimodal interaction to address these challenges. This system integrates cutting-edge techniques to emulate human cognition. The IXC2.5-OL framework comprises three key modules:
- Streaming Perception ModuleMultimodal Long Memory ModuleReasoning Module
These components work harmoniously to process multimodal data streams, compress and retrieve memory, and respond to queries efficiently and accurately. This modular approach, inspired by the specialized functionalities of the human brain, ensures scalability and adaptability in dynamic environments.
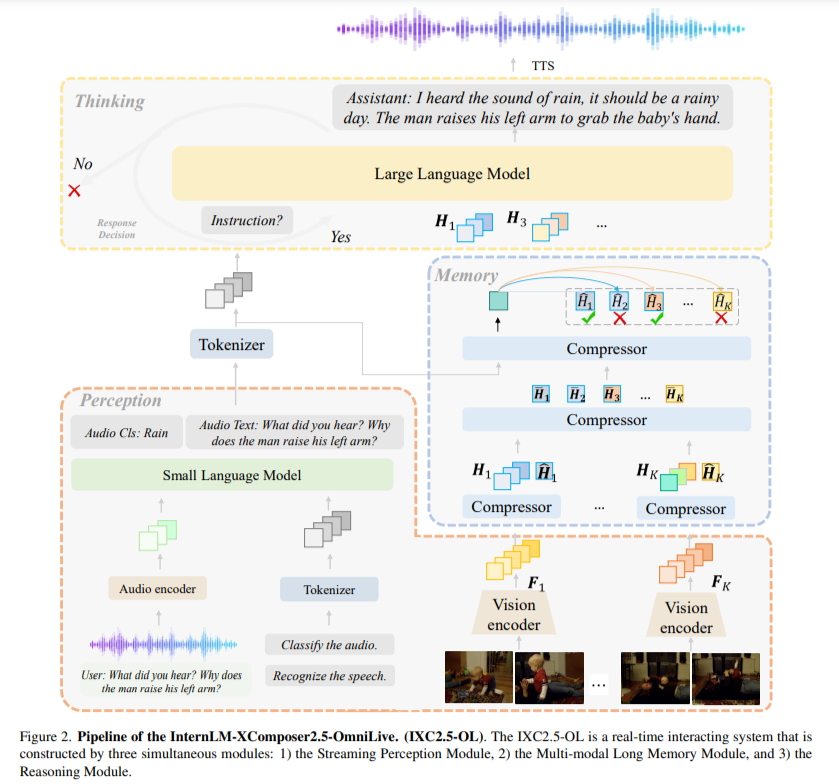
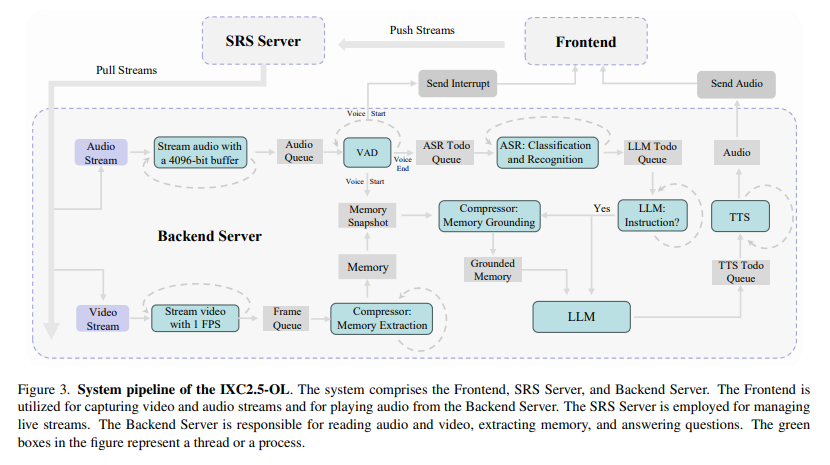
The Streaming Perception Module handles real-time audio and video processing. Using advanced models like Whisper for audio encoding and OpenAI CLIP-L/14 for video perception, this module captures high-dimensional features from input streams. It identifies and encodes key information, such as human speech and environmental sounds, into memory. Simultaneously, the Multimodal Long Memory Module compresses short-term memory into efficient long-term representations, integrating these to enhance retrieval accuracy and reduce memory costs. For example, it can condense millions of video frames into compact memory units, significantly improving the system’s efficiency. The Reasoning Module, equipped with advanced algorithms, retrieves relevant information from the memory module to execute complex tasks and answer user queries. This enables the IXC2.5-OL system to perceive, think, and memorize simultaneously, overcoming the limitations of traditional models.
The IXC2.5-OL has been evaluated across multiple benchmarks. In audio processing, the system achieved a Word Error Rate (WER) of 7.8% on Wenetspeech’s Chinese Test Net and 8.4% on Test Meeting, outperforming competitors like VITA and Mini-Omni. For English benchmarks like LibriSpeech, it scored a WER of 2.5% on clean datasets and 9.2% on noisier environments. In video processing, IXC2.5-OL excelled in topic reasoning and anomaly recognition, achieving an M-Avg score of 66.2% on MLVU and a state-of-the-art score of 73.79% on StreamingBench. The system’s simultaneous processing of multimodal data streams ensures superior real-time interaction.
Key takeaways from this research include the following:
- The system’s architecture mimics the human brain by separating perception, memory, and reasoning into distinct modules, ensuring scalability and efficiency. It achieved state-of-the-art results in audio recognition benchmarks such as Wenetspeech and LibriSpeech and video tasks like anomaly detection and action reasoning. The system handles millions of tokens efficiently by compressing short-term memory into long-term formats, reducing computational overhead. All code, models, and inference frameworks are available for public use. The system’s ability to process, store, and retrieve multimodal data streams simultaneously allows for seamless, adaptive interactions in dynamic environments.
In conclusion, the InternLM-XComposer2.5-OmniLive framework is overcoming the long-standing limitations of simultaneous perception, reasoning, and memory. The system achieves remarkable efficiency and adaptability by leveraging a modular design inspired by human cognition. It achieves state-of-the-art performance in benchmarks like Wenetspeech and StreamingBench, demonstrating superior audio recognition, video understanding, and memory integration capabilities. Hence, InternLM-XComposer2.5-OmniLive offers unmatched real-time multimodal interaction with scalable human-like cognition.
Check out the Paper, GitHub Page, and Hugging Face Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal AI System for Long-Term Streaming Video and Audio Interactions appeared first on MarkTechPost.
