
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。
参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。
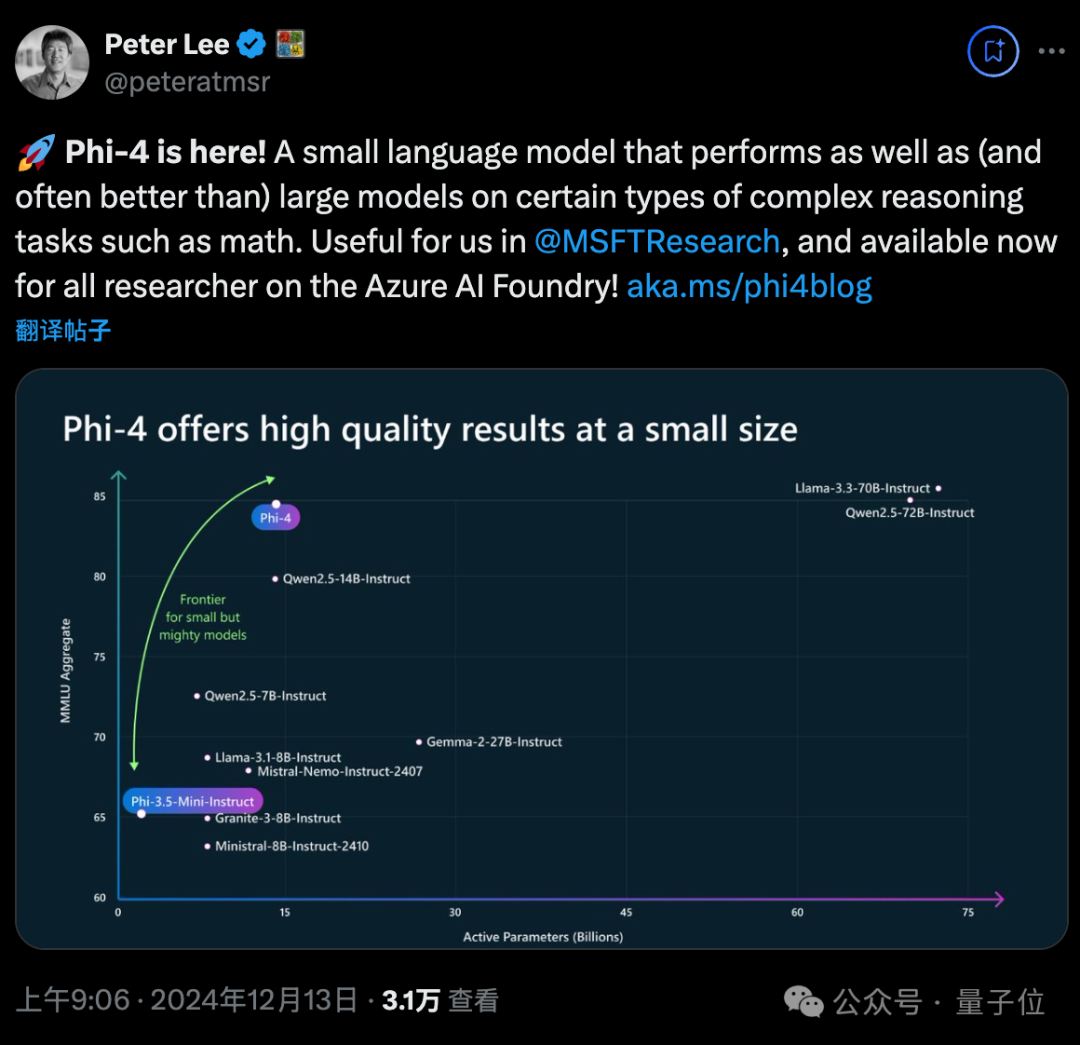
数学能力上,Phi-4在美国数学竞赛AMC 10/12上超过了GPT-4o等一众大模型,分数冲上90。
编程能力也是开源模型一流,超过了70B的Llama 3.3和72B的Qwen 2.5。
更引起热议的是,微软在技术报告中还提出了一个新的训练范式——midtraining。
这一举动让Phi-4拥有了更强的长文本处理能力,窗口长度达到16K后,召回率依然保持在99%。

小模型挑战复杂推理
在常见基准测试中,Phi-4取得了优异的文本处理和复杂推理水平:
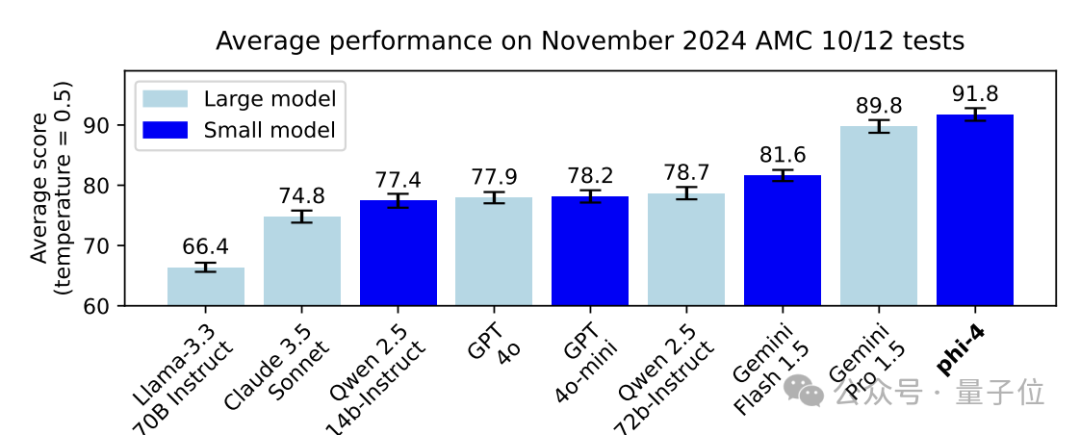
在MMLU上,Phi-4以84.8%的准确率超过了GPT-4o-mini的81.8%和Llama-3.3的86.3%;
在研究生水平STEM问答GPQA上,Phi-4准确率达到56.1%,高于同尺寸模型Qwen-2.5的42.9%,甚至超过了GPT-4o的50.6%;
在数学测试集MATH上,Phi-4以80.4%的准确率超过GPT-4o-mini的73%,并接近GPT-4o的74.6%;
编程能力方面,Phi-4在HumanEval上以82.6%超过了其他开源模型,以及GPT-4o-mini。
在难度稍高的MMLU和HumanEval+上,Phi-4的表现也超过了其他开源模型;在ArenaHard、LiveBench和IFEval上则表现欠佳。
另外,微软还用内部的基准PhiBench对模型能力进行了更全面的评估,结果Phi-4取得了56.2%的综合得分,展现出在推理、知识、编程等方面的全面能力,但相比于Qwen 2.5-72B等模型,还是暴露了有待提高之处。
在Phi-4的宣传页中,微软还展示了其在一个具体的数学推理题目上的表现。
Phi-4非常有条理地考虑了各种可能出现的情况,并计算出了正确答案。

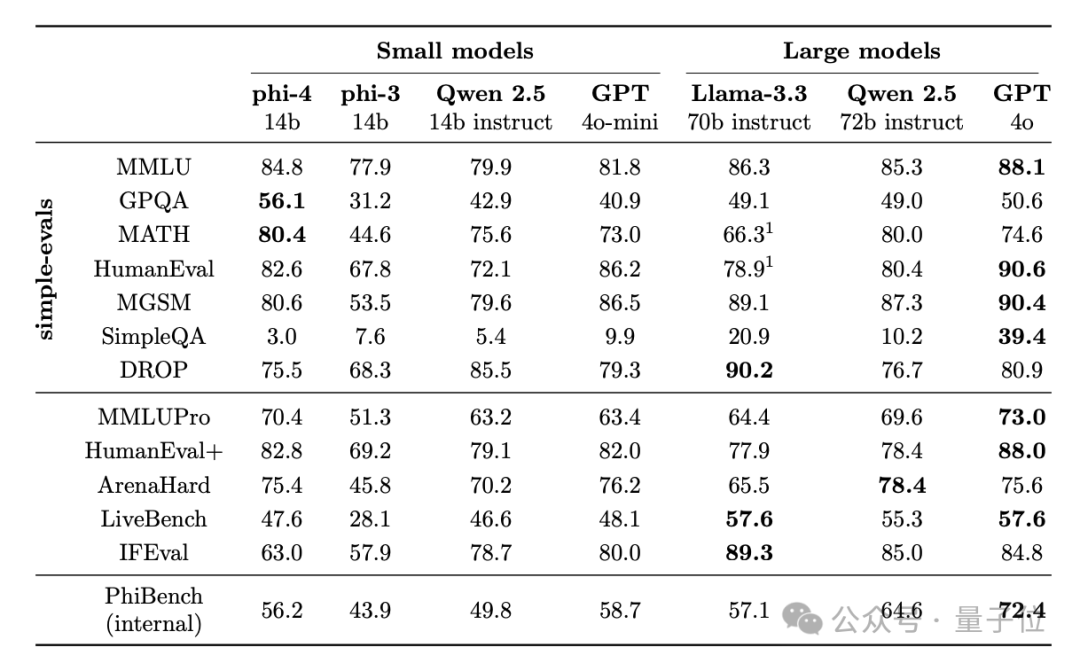
除了这些常规能力,微软团队还专门在长文本上测试了Phi-4的表现。
在8K和16K两种窗口长度中,研究团队利用HELMET基准评估了Pho-4和其他模型在RAG、QA问答、长文本摘要等任务上的水平。
结果,Phi-4在多个任务上与同尺寸的Qwen 2.5-14B相当,部分指标还可与70B的Llama 3.3一决高下。
不过,Phi-4在某些任务(如RAG和文档排序)上,仍有进一步提升的空间。
不同于一般大模型的预训练+后训练的两阶段模式,微软在两个阶段中间新加入了一个midtraining阶段。
在10万亿tokens规模的预训练完成后,Phi-4可以处理4k长度的上下文窗口,而midtraining的目的是在此基础上进一步将窗口长度提升到16k。
研究团队发现,天然的长上下文数据(如完整的学术论文)比人工拼接短样本更有利于训练长上下文能力。

因此,团队从学术文章、书籍、代码库等高质量非合成文本中筛选出长度大于8K tokens的样本作为训练集,并且对长度超过16K tokens的样本进行加权,以匹配目标长度。
为进一步丰富长上下文训练数据,研究团队专门生成了满足大于4K长度要求的新合成数据,与真实长文本数据共同组成了midtraining阶段的数据集。
最终,midtraining阶段的数据包含30%新引入的长文本数据(筛选+合成)和70%预训练阶段的历史数据,规模为2500亿tokens。
同时,为了适应16K的长序列训练,研究团队将rope位置编码的基频从预训练阶段的2K扩大到250K;同时,为保证训练稳定性,团队将学习率降低为预训练阶段的十分之一。
最终,Phi-4在HELMET等长文本基准测试中表现出色,证明了midtraining阶段的有效性。
除此之外,在后训练阶段,研究团队还提出了一种新颖的对比学习方法——枢轴tokens搜索(PTS)。
通过识别对模型输出影响最大的关键tokens,并围绕它们构造正负样本对,PTS可以生成高信噪比的对比学习数据,显著提升训练效率和效果。
除了PTS生成的对比学习数据,研究团队还引入了人类反馈对比学习(Human Feedback DPO)。
他们招募了大量人员对模型输出进行评判,并据此构造优质的正负样本对,使得模型更加贴近人类偏好。
One More Thing
不过midtraining并不是微软首次提出,早在7月份,OpenAI就已经开始为伦敦的midtraining团队招人了。
论文地址:
https://arxiv.org/abs/2412.08905
— 完 —
点这里?关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

