
Published on December 14, 2024 4:00 AM GMT
Over the past few months, I helped develop Gradient Routing, a non loss-based method to shape the internals of neural networks. After my team developed it, I realized that I could use the method to do something that I have long wanted to do: make an autoencoder with an extremely interpretable latent space.
I created an MNIST variational autoencoder with a 10 dimensional latent space, with each dimension of the latent space corresponding to a different digit. Before I get into how I did it, feel free to play around with my demo here (it loads the model into the browser): https://jacobgw.com/gradient-routed-vae/.
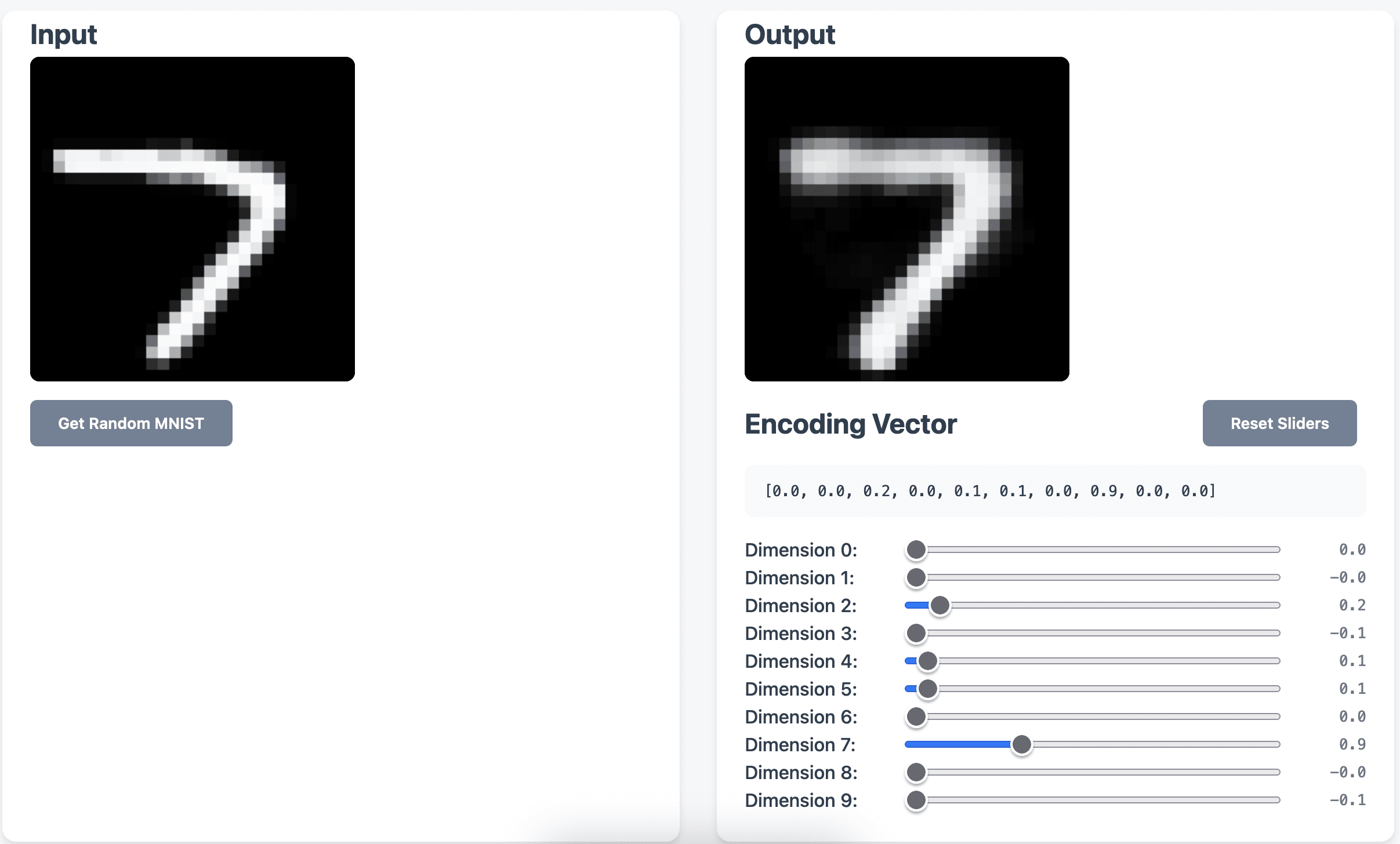
In the demo, you can both see how a random MNIST image encodes but also directly play around with the encoding itself and create different types of digits by just moving the sliders.
The reconstruction is not that good, and I assume this is due to some combination of (1) using the simplest possible architecture of MLP layers and ReLU (2) only allowing a 10 dimensional latent space which could constrain the representation a lot (3) not doing data augmentation, so it might not generalize that well, and (4) gradient routing targeting an unnatural internal representation, causing the autoencoder to not fit the data that well. This was just supposed to be a fun proof of concept project, so I’m not too worried about the reconstruction not being that good here.
How it works
My implementation of gradient routing is super simple and easy to add onto a variational autoencoder. During training, after I run the encoder, I just detach every dimension of the encoding except for the one corresponding to the label of the image:
def encode_and_mask(self, images: Tensor, labels: Tensor): encoded_unmasked, zeta, mean, cov_diag = self.encode(images) mask = F.one_hot(labels, num_classes=self.latent_size).float() encoded = mask encoded_unmasked + (1 - mask) encoded_unmasked.detach() return encoded, zeta, mean, cov_diagThis causes each dimension of the latent space to “specialize” to representing its corresponding image since the error for that image type can only be propagated through the single dimension of the latent space.
It turns out that if you do this, nothing forces the model to represent “more of a digit” in the positive direction. Sometimes the model represented “5-ness” in the negative direction in the latent space (e.g. as [0, 0, 0, 0, 0, -1.0, 0, 0, 0, 0]). This messed with my demo a bit since I wanted all the sliders to only go in the positive direction. My solution? Just apply ReLU the encoding so it can only represent positive numbers! This is obviously not practical and I only included it so the demo would look nice.[1]
In our Gradient Routing paper, we found that models sometimes needed regularization to split the representations well. However, in this setting, I’m not applying any regularization besides the default regularization that comes with a variational autoencoder. I guess it turns out that this regularization is enough to effectively split the digits.
Classification
It turns out that even though there was no loss function causing the encoding to activate most strongly on the dimension corresponding to the digit being encoded, it happened! In fact, we can classify digits to 92.58% accuracy by just taking the argmax over the encoding (which slider is the most positive), which I find pretty amazing.
You can see the code here.
- ^
I did have to train the model a few times to get something that behaved nicely enough for the demo.
Discuss
