


Diffusion models are closely linked to imitation learning because they generate samples by gradually refining random noise into meaningful data. This process is guided by behavioral cloning, a common imitation learning approach where the model learns to copy an expert’s actions step by step. For diffusion models, the predefined process transforms noise into a final sample, and following this process ensures high-quality results in various tasks. However, behavioral cloning also causes slow generation speed. This happens because the model is trained to follow a detailed path with many small steps, often requiring hundreds or thousands of calculations. However, these steps are computationally expensive in terms of time and require a lot of computation, and taking fewer steps to generate reduces the quality of the model.
Current methods optimize the sampling process without changing the model, such as tuning noise schedules, improving differential equation solvers, and using non–Markovian methods. Others enhance the quality of the sample by training neural networks for short-run sampling. Distillation techniques show promise but usually perform below teacher models. However, adversarial or reinforcement learning methods may surpass them. RL updates the diffusion models based on reward signals using policy gradients or different value functions.
To solve this, researchers from the Korea Institute for Advanced Study, Seoul National University, University of Seoul, Hanyang University, and Saige Research proposed two advancements in diffusion models. The first approach, called Diffusion by Maximum Entropy Inverse Reinforcement Learning (DxMI), combined two methods: diffusion and Energy-Based Models (EBM). In this method, EBM used rewards to measure how good the results were. The goal was to adjust the reward and entropy (uncertainty) in the diffusion model to make training more stable and ensure that both models performed well with the data. The second advancement, Diffusion by Dynamic Programming (DxDP), introduced a reinforcement learning algorithm that simplified entropy estimation by optimizing an upper bound of the objective and eliminated the need for back-propagation through time by framing the task as an optimal control problem, applying dynamic programming for faster and more efficient convergence.

The experiments demonstrated DxMI’s effectiveness in training diffusion and energy-based models (EBMs) for tasks like image generation and anomaly detection. For 2D synthetic data, DxMI improved sample quality and energy function accuracy with a proper entropy regularization parameter. It was demonstrated that pre-training with DDPM is useful but unnecessary for DxMI to function. DxMI fine-tuned models such as DDPM and EDM with fewer generation steps for image generation, which were competitive in quality. In anomaly detection, the energy function of DxMI performed better in detecting and localizing anomalies on the MVTec-AD dataset. Entropy maximization improved performance by promoting exploration and increasing model diversity.
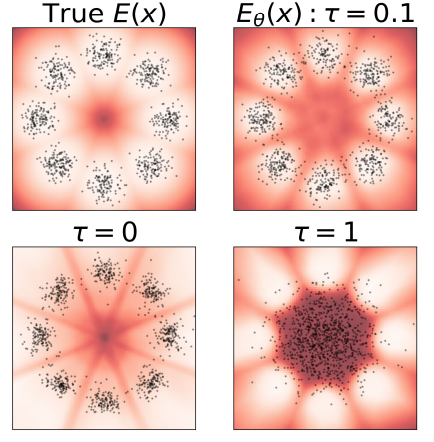
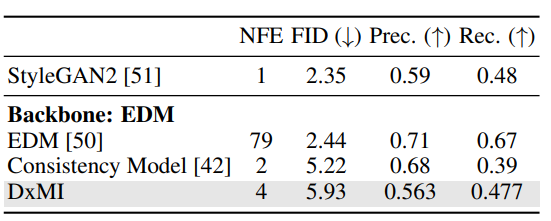
In summary, the proposed method greatly advances the efficiency and quality of diffusion generative models by using the DxMI approach. It solves the issues of previous methods, such as slow generation speeds and degraded sample quality. However, it is not directly suitable for training single-step generators, but a diffusion model fine-tuned by DxMI can be converted into one. DxMI lacks the flexibility to use different generation steps during testing. This method can be used for upcoming research in this domain and serve as a baseline, making a significant difference!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post This AI Paper Introduces A Maximum Entropy Inverse Reinforcement Learning (IRL) Approach for Improving the Sample Quality of Diffusion Generative Models appeared first on MarkTechPost.
