
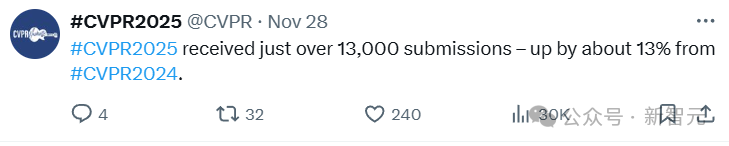
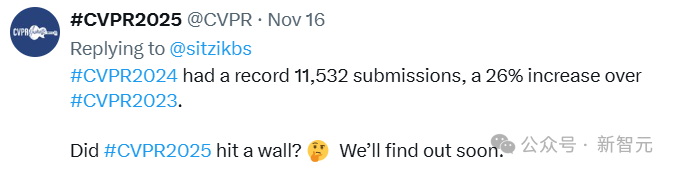
CVPR 2024收到11532次提交,增幅达到了26%;今年的投稿增速虽然有所放缓,达到13%,但也超过了13000次提交。
投稿量过大,最直接导致的一个问题就是「高质量审稿人不足」,很多人为了简化审稿流程,可能会选择用大模型进行审稿。

比如CVPR 2024大约有9000名审稿人,但投稿作者的数量却超过了30000,为了平衡投稿与审稿,这届CVPR提出了七条审稿新规,来限制不负责任的审稿结果。
目前,CVPR 2025的审稿即将开启,今天也是区域主席提交推荐审稿人的最后期限,与此同时,官方推特再次发文强调了,绝对禁止使用大模型在「任何流程」中参与审稿!

搞笑的,CVPR直接附上了用LLM作了一篇拒稿的小诗的离谱案例。(手动狗头)

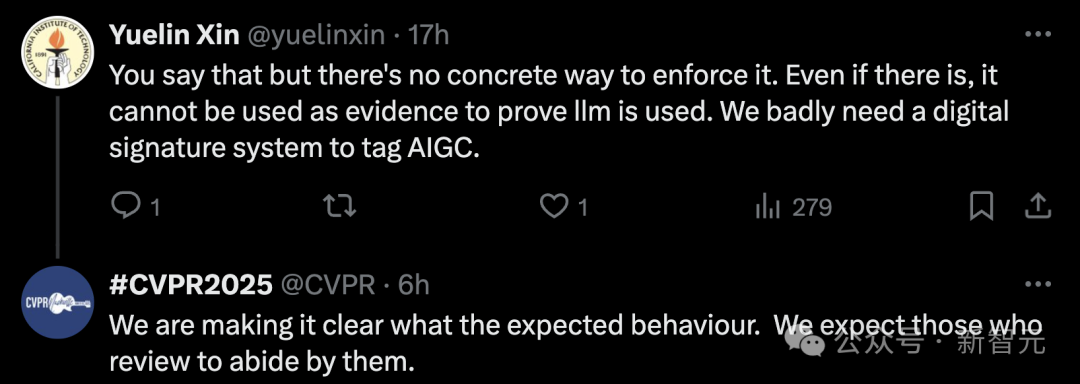
不过话虽如此,但网友在评论区中表示,虽然想法是好的,但并没有任何具体、可靠的方式来贯彻执行;即使审稿人用了大模型,也没办法证明这件事。
CVPR 2025审稿新规七板斧

为了应对投稿量的上涨,以及审稿质量的下降,CVPR 2025对会议规定做了七条修正,算是解决「大模型审稿」等问题的一个可行方案:
1、除非作者在CVPR 2025中担任其他职务,否则所有作者都都有义务担任审稿人,负责的审稿数量将根据作者资历水平决定。
2、如果审稿人被区域主席标记为「高度不负责任」,那其提交的论文也可能会被直接拒绝,要根据具体情况而定。
3、每位作者最多提交25篇论文,其中25篇的限制来源于CVPR 2024中单个投稿人最多的中稿数量。不过网友普遍表示,25篇还是太多了。

4、在任何阶段,都不允许使用大模型撰写审稿意见。
5、在最终论文决策公布后,审稿人的姓名在OpenReview上也会对其他审稿人可见。
6、每位投稿人都需要填写完整的OpenReview个人资料,以便更好地进行分配审稿人和利益冲突检测,否则论文也会被直接拒绝。
7、CVPR 2025的审稿数据会共享给其他会议,对不负责的审稿人可以起到长久的限制作用。
其中第二条最具威慑性,不负责任的审稿意见包括,只有一两句内容、使用大模型生成、与被审论文不相关,或者是遗漏了重要内容。

对于大模型,CVPR特意在审稿指南中列出要求:不能要求大模型撰写审稿内容,只能根据自己对论文的判断;不能向大模型共享论文或评审中的实质性内容,比如用大模型来翻译评审意见;可以使用大模型进行背景调研或语法检查,以确保审稿意见清晰。
不过具体执行时,这七条新规能否起到作用,还要等CVPR 2025论文录用结果发布后,再看各家网友对审稿结果的反应如何。
大模型审稿,堵不如疏
严禁任何形式的抄袭,以及审稿人、领域主席(AC)和高级领域主席(SAC)对特权信息的不道德使用,例如共享此信息,或将其用于评审过程以外的任何其他目的。
禁止包含从大模型(LLM)(如ChatGPT)生成的文本的论文,除非这些生成的文本作为论文实验分析的一部分呈现。
所有可疑的不道德行为都将由道德委员会进行调查,被发现违反规则的个人可能会面临制裁。
当时网友的普遍反应都是不理解,认为使用大模型进行润色是很正常的,MIT教授Erik Brynjolfsson甚至评价为「一场必败的仗」;LeCun当时还玩了一个文字游戏,「中小型模型」可以用吗?
如今看来,ICML确实败了,CVPR 2025新规中,允许使用大模型润色,但仍然不允许编写实质性审稿内容。
凡是合乎理性的东西都是现实的,凡是现实的东西都是合乎理性的。
既然用大模型审稿有他存在的现实意义,那么也一定有其合理性,科研大势就是使用大模型参与到审稿、论文编写过程中,已经有大量的相关研究来利用大模型辅助人类审稿,还提出相关评估基准等。

论文地址:https://arxiv.org/abs/2310.01783
比如斯坦福学者发现,GPT-4对于Nature、ICLR的论文给出的审稿意见,和人类审稿人已然有超过50%的相似性,未来让大模型辅助论文评审,也并不是完全不靠谱。

再换个思路,难道人类审稿就一定靠谱了吗?
既然无法一禁了之,更好的方法或许是引导审稿人合理利用大模型,比如官方提供大模型接口界面,标注出论文中的关键点,方便审稿人快速、直观地理解论文内容;有了更方便的工具之后,寻求外部大模型工具进行优化的动力就会小很多。
另一方面,科研人员也可以对所有大模型参与审稿的过程进行标准化,评估不同模型在审稿过程中的可靠性。
靠强硬规定来禁止大模型并不具备可操作性,只能起到威慑作用,即便引入所谓的「大模型数字签名」,甚至是用分类模型来判断审稿意见是否由AI生成,只要提交者自己重新编辑一下审稿意见,是否使用大模型也就无从判断了。
关于大模型审稿,你怎么看?或者说,你希望自己的论文被大模型评审吗?



