


Code intelligence has grown rapidly, driven by advancements in large language models (LLMs). These models are increasingly utilized for automated programming tasks such as code generation, debugging, and testing. With capabilities spanning multiple languages and domains, LLMs have become crucial tools in advancing software development, data science, and computational problem-solving. The evolution of LLMs is transforming how complex programming tasks are approached and executed.
One significant area for improvement in the current landscape is the need for comprehensive benchmarks that accurately reflect real-world programming demands. Existing evaluation datasets, such as HumanEval, MBPP, and DS-1000, are often narrowly focused on specific domains, like advanced algorithms or machine learning, failing to capture the diversity required for full-stack programming. Moreover, these datasets could be more extensive in assessing the multilingual and domain-spanning capabilities necessary for real-world software development. This gap poses a major obstacle to effectively measuring and advancing LLM performance.
Researchers from ByteDance Seed and M-A-P have introduced FullStack Bench, a benchmark that evaluates LLMs across 11 distinct application domains and supports 16 programming languages. The benchmark includes data analysis, desktop and web development, machine learning, and multimedia. Further, they developed SandboxFusion, a unified execution environment that automates code execution and evaluation in multiple languages. These tools aim to provide a holistic framework for testing LLMs in real-world scenarios and overcoming the limitations of existing benchmarks.
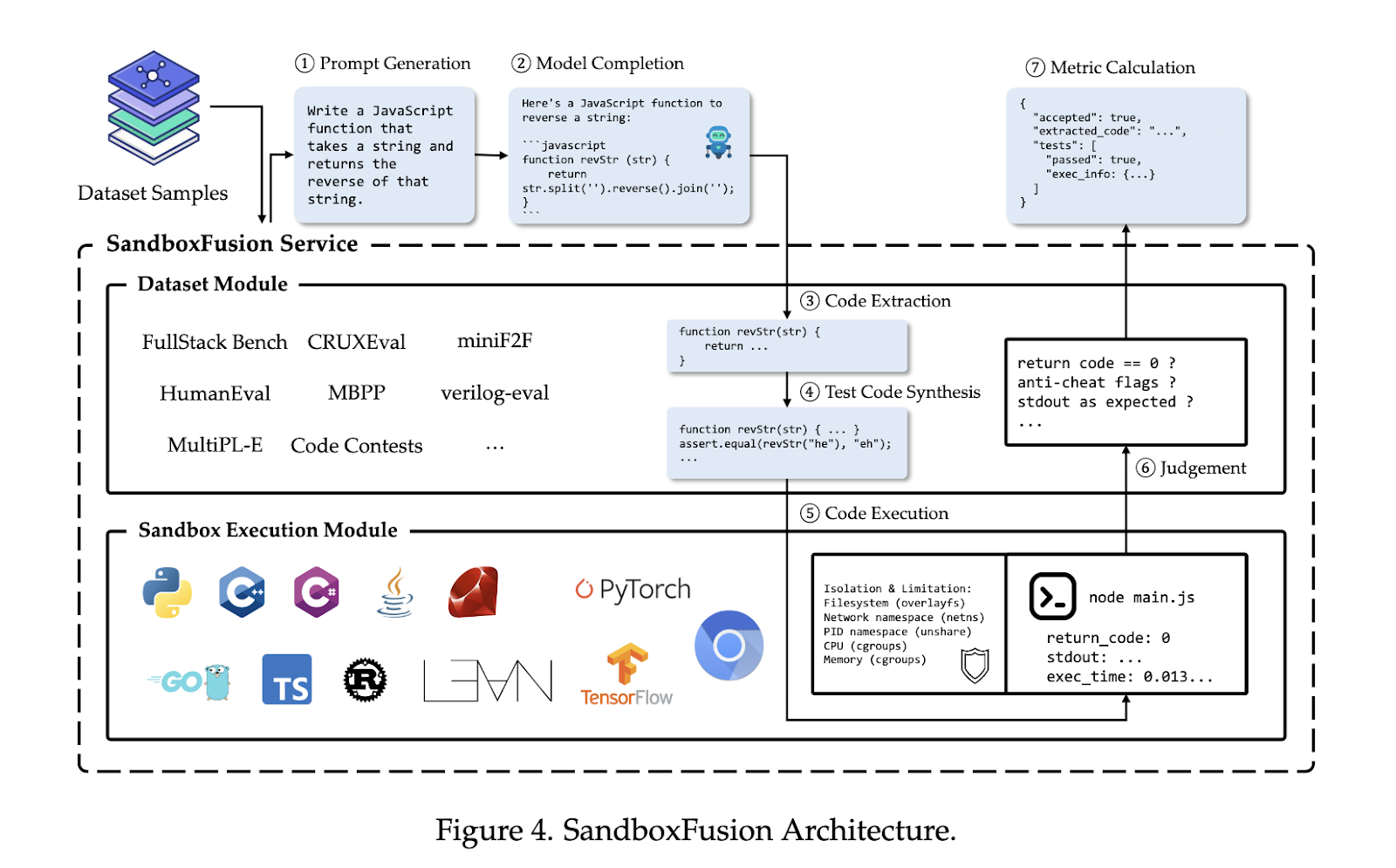
The FullStack Bench dataset contains 3,374 problems, each accompanied by unit test cases, reference solutions, and easy, medium, and hard difficulty classifications. Problems were curated using a combination of human expertise and LLM-assisted processes, ensuring diversity and quality in question design. SandboxFusion supports the execution of FullStack Bench problems by enabling secure, isolated execution environments that accommodate the requirements of different programming languages and dependencies. It supports 23 programming languages, providing a scalable and versatile solution for benchmarking LLMs on datasets beyond FullStack Bench, including popular benchmarks like HumanEval and MBPP.
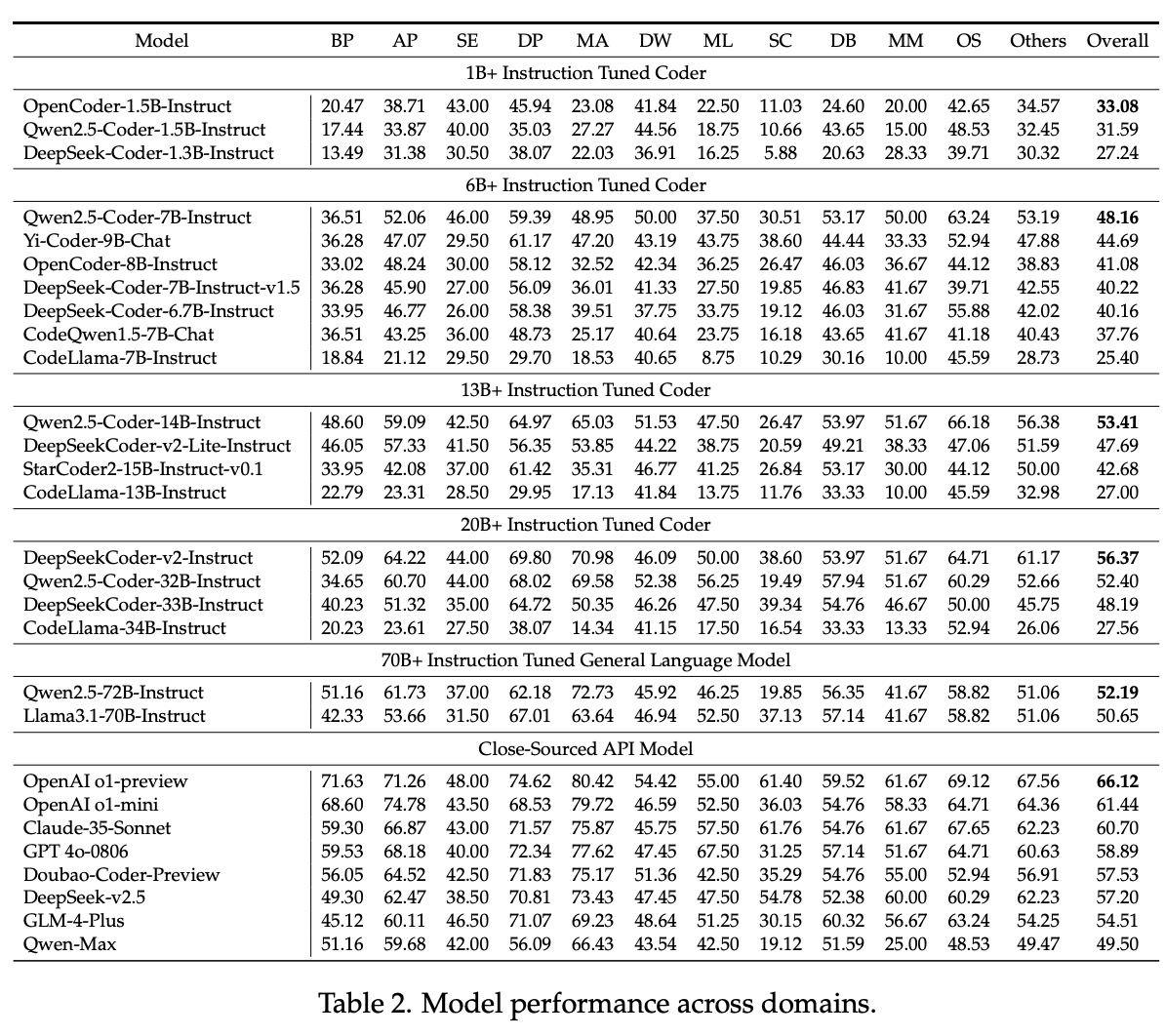
The researchers conducted extensive experiments to evaluate the performance of various LLMs on FullStack Bench. Results revealed marked differences in performance across domains and programming languages. For example, while some models demonstrated strong basic programming and data analysis capabilities, others needed help with multimedia and operating system-related tasks. Pass@1, the primary evaluation metric, varied across domains, highlighting models’ challenges in adapting to diverse and complex programming tasks. SandboxFusion proved to be a robust and efficient evaluation tool, significantly outperforming existing execution environments in supporting a wide range of programming languages and dependencies.
Scaling laws were also analyzed, showing that increasing parameters generally improves model performance. However, researchers observed a performance decline for some models at higher scales. For example, the Qwen2.5-Coder series peaked at 14B parameters but showed a drop in performance at 32B and 72B. This finding underscores the importance of balancing model size and efficiency in optimizing LLM performance. Researchers observed a positive correlation between code compilation pass rates and test success rates, emphasizing the need for precise and error-free code generation.
The FullStack Bench and SandboxFusion collectively represent significant advancements in evaluating LLMs. By addressing the limitations of existing benchmarks, these tools enable a more comprehensive assessment of LLM capabilities across diverse domains and programming languages. This research lays the groundwork for further innovations in code intelligence and emphasizes the importance of developing tools that accurately reflect real-world programming scenarios.
Check out the Paper, FullStack Bench, and SandboxFusion. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Bytedance AI Research Releases FullStack Bench and SandboxFusion: Comprehensive Benchmarking Tools for Evaluating LLMs in Real-World Programming Scenarios appeared first on MarkTechPost.
