


Board games have long been pivotal in shaping AI, serving as structured environments for testing decision-making and strategy. Games like chess and Connect Four, with their distinct rules and varying levels of complexity, have enabled AI systems to learn dynamic problem-solving. The structured nature of these games challenges AI to anticipate moves, consider opponents’ strategies, and execute plans effectively.
Large language models (LLMs) need help in multi-step reasoning and planning. Their inability to simulate sequences of actions and evaluate long-term outcomes hinders their application in scenarios requiring advanced planning. This limitation is evident in games, where predicting future states and weighing the consequences of actions are crucial. Addressing these deficiencies is essential for real-world applications demanding sophisticated decision-making. Traditional methods for planning in AI, especially in gaming contexts, rely heavily on external engines and algorithms like Monte Carlo Tree Search (MCTS). These systems simulate potential game states and evaluate actions based on predefined rules, often requiring large computational resources. While effective in achieving strong results, these methods depend on domain-specific tools to track legal moves and assess outcomes, limiting their flexibility and scalability. This dependency highlights the need for models that integrate planning and reasoning without external assistance.
Researchers at Google DeepMind, Google, and ETH Zürich introduced the Multi-Action-Value (MAV) model, a game-changing innovation in AI planning. The MAV model leverages a Transformer-based architecture trained on vast datasets of textual game states to act as a standalone decision-making system. Unlike traditional systems, MAV performs state tracking, predicts legal moves, and evaluates actions without external game engines. Trained on over 3.1 billion positions from games like chess, Chess960, Hex, and Connect Four, the MAV model processes 54.3 billion action values to inform its decisions. This extensive pre-training minimizes errors, such as hallucinations, and ensures accurate state predictions.
The MAV model is a comprehensive tool capable of handling world modeling, policy generation, and action evaluation. It processes game states using a tokenized format, enabling precise tracking of board dynamics. Key innovations include internal search mechanisms allowing the model to explore decision trees autonomously, simulating and backtracking potential moves. For example, the MAV model in chess uses 64 predefined value buckets to classify win probabilities, ensuring precise evaluations. These features enable the MAV system to perform complex calculations and refine its strategies in real time, achieving unparalleled efficiency and accuracy.
In chess, the MAV model achieved an Elo rating of 2923, surpassing previous AI systems like Stockfish L10. Its ability to operate on a move count search budget similar to human grandmasters highlights its efficiency. The model also excelled in Chess960, leveraging its training on 1.2 billion positions to outpace traditional systems. In Connect Four, MAV showed consistent improvements, with external search methods enhancing decision-making by over 244 Elo points. The MAV model demonstrated potential even in Hex, where state-tracking capabilities were limited.

Key takeaways from this research include:
- Comprehensive Integration: MAV combines world modeling, policy evaluation, and action prediction into a single system, eliminating reliance on external engines.Improved Planning Efficiency: Internal and external search mechanisms significantly enhance the model’s ability to reason about future actions. With limited computational resources, it achieves up to 300 Elo point gains in chess.High Precision: The model boasts near-perfect accuracy in state predictions. It achieves 99.9% precision and recall for legal moves in chess.Versatility Across Games: MAV’s training on diverse datasets enables strong performance in multiple games, with Chess960 and Connect Four showcasing adaptability and strategic depth.
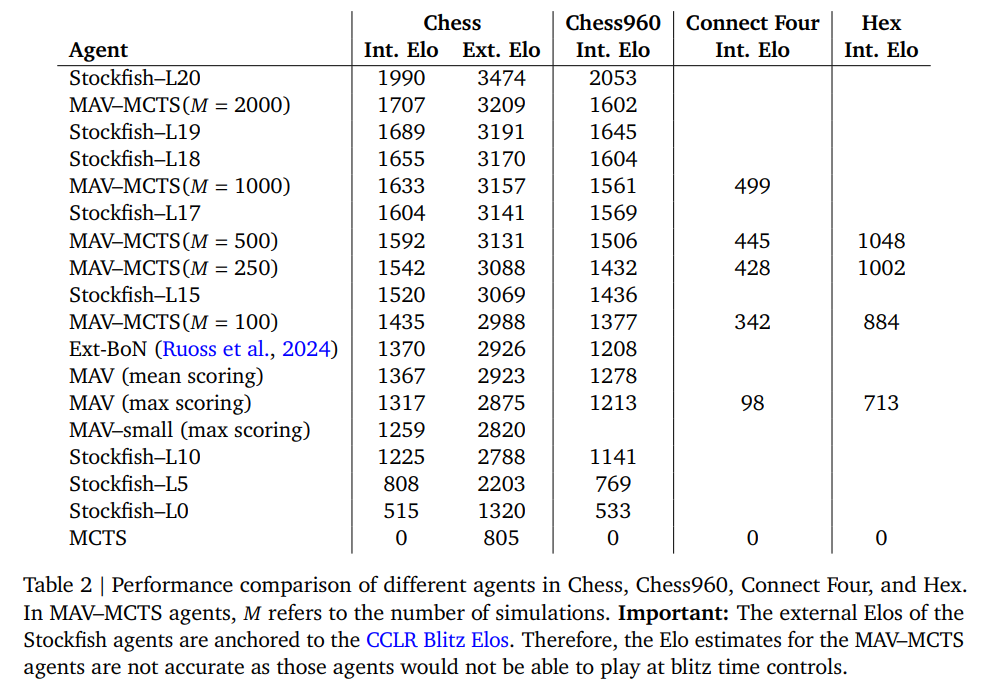
In conclusion, with over 3.1 billion training positions and 54.3 billion action values, the MAV model achieves exceptional performance across games. It attains an Elo rating of 2923 in chess, rivaling Grandmaster-level strength, while requiring only 1000 simulations, far fewer than traditional systems like AlphaZero’s 10k. In Connect Four, it improves decision-making by over 244 Elo points through external search mechanisms. These results emphasize MAV’s ability to generalize across games, maintain 99.9% move legality precision, and operate efficiently on human-comparable search budgets.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Google DeepMind Researchers Advance Game AI: From Hallucination-Free Moves to Grandmaster Play appeared first on MarkTechPost.
