


LLMs have revolutionized artificial intelligence with their remarkable scalability and adaptability. Models like GPT-4 and Claude, built with trillions of parameters, demonstrate exceptional performance across diverse tasks. However, their monolithic design comes with significant challenges, including high computational costs, limited flexibility, and difficulties in fine-tuning for domain-specific needs due to risks like catastrophic forgetting and alignment tax. Open-weight LLMs such as Llama3 and Mistral, supported by an active open-source community, have created smaller, task-specific expert models. These models address niche requirements effectively and often surpass monolithic models in specialized domains, though they remain resource-intensive for broader adoption.
Advances in LLM architecture and ensemble approaches have sought to optimize performance and efficiency. The Mixture of Experts (MoE) models uses gating mechanisms to route tasks to specialized experts, enhancing domain-specific accuracy. Similarly, ensemble methods, like LLMBlender, combine outputs from multiple models to improve overall performance. Other techniques, such as reward-guided routing and tag-based label enhancements, direct queries to the most relevant models, but their high inference costs pose practical challenges. These innovations highlight ongoing efforts to overcome the limitations of large-scale LLMs by balancing computational efficiency with specialization.
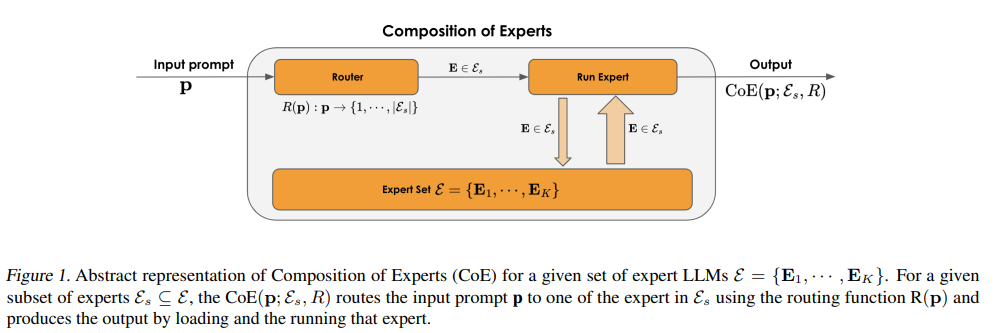
Researchers from SambaNova Systems have introduced the Composition of Experts (CoE). This modular AI framework dynamically routes inputs to specialized expert LLMs using a two-step process: a category router classifies inputs into predefined categories, followed by a category-to-expert mapping that assigns the most suitable expert. This approach enhances modularity, scalability, and computational efficiency compared to monolithic LLMs, allowing easy integration of new capabilities. Leveraging SambaNova’s SN40L hardware, CoE demonstrates strong performance, achieving scores of 59.4 on Arena-Hard and 9.06 on MT-Bench with significantly reduced active parameters, showcasing its potential for cost-effective, high-performance AI systems.
The CoE framework uses a subset of expert LLMs selected from a larger pool, routing input prompts via a function to the most suitable expert for output generation. The system minimizes loss while adhering to a parameter budget. A two-step routing process categorizes prompts and assigns them to the best expert within a category, enhancing modularity and interpretability. The framework uses labeled datasets for training and semi-supervised methods for prompt curation. Memory efficiency is managed by offloading models to CPUs or scaling across GPUs, ensuring flexibility and sustained performance despite the increasing number of experts.
The CoE framework is evaluated on several benchmarks, including Arena-Hard for single-turn interactions, MT-Bench for multi-turn conversations, and knowledge-intensive tasks like GSM8k CoT and MMLU-Pro. These benchmarks assess CoE’s ability to balance performance and computational efficiency. On Arena-Hard, CoE shows improved scalability and resource utilization, outperforming individual expert models as the total parameter budget (B) increases. The robust version of CoE, leveraging uncertainty-aware routing, further enhances stability and accuracy, achieving competitive scores with significantly fewer active parameters than closed-source models. Its modular design allows easy integration of new expert models for further performance improvements.
In multi-turn evaluation on MT-Bench, CoE demonstrates efficiency by dynamically routing prompts and conversation history to the most suitable expert at each turn, achieving results comparable to larger, resource-intensive models. Due to training data distribution gaps, CoE needs to catch up to individual experts for knowledge-specific tasks across various disciplines but recovers performance using Robust-CoE. This is achieved through uncertainty quantification, which ensures accurate routing to generalist experts. By leveraging open-weight LLMs like Qwen and Llama, CoE achieves competitive scores with reduced active parameters, showcasing its effectiveness as a cost-efficient, scalable, and modular AI system.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Composition of Experts: A Modular and Scalable Framework for Efficient Large Language Model Utilization appeared first on MarkTechPost.
