


Snowflake recently announced the launch of Arctic Embed L 2.0 and Arctic Embed M 2.0, two small and powerful embedding models tailored for multilingual search and retrieval. The Arctic Embed 2.0 models are available in two distinct variants: medium and large. Based on Alibaba’s GTE-multilingual framework, the medium model incorporates 305 million parameters, of which 113 million are non-embedding parameters. The large variant builds on a long-context adaptation of Facebook’s XMLR-Large and houses 568 million parameters, including 303 million non-embedding parameters. Both models support context lengths of up to 8,192 tokens, making them versatile for applications requiring extensive contextual understanding.
The innovation behind Arctic Embed 2.0 lies in its ability to provide high-quality retrieval across multiple languages while retaining its predecessors’ superior English retrieval capabilities. Snowflake’s team carefully balanced these multilingual demands, enabling Arctic Embed 2.0 to outperform even English-only models in English-language benchmarks such as the MTEB Retrieval benchmark. Also, these models demonstrated remarkable performance on multilingual benchmarks, including CLEF and MIRACL, achieving higher nDCG@10 scores across languages like German, French, Spanish, and Italian.
Despite their compact size relative to other frontier models, Arctic Embed 2.0 models deliver rapid embedding throughput. Testing on NVIDIA A10 GPUs revealed the large model’s capacity to process over 100 documents per second with sub-10ms query embedding latency. This efficiency facilitates deployment on cost-effective hardware, a crucial advantage for enterprises managing large-scale data. The release also includes advanced features such as Matryoshka Representation Learning (MRL), a technique designed for scalable retrieval. With MRL, users can compress embeddings to as little as 128 bytes per vector, a compression ratio 96 times smaller than the uncompressed embeddings of some proprietary models like OpenAI’s text-embedding-3-large.
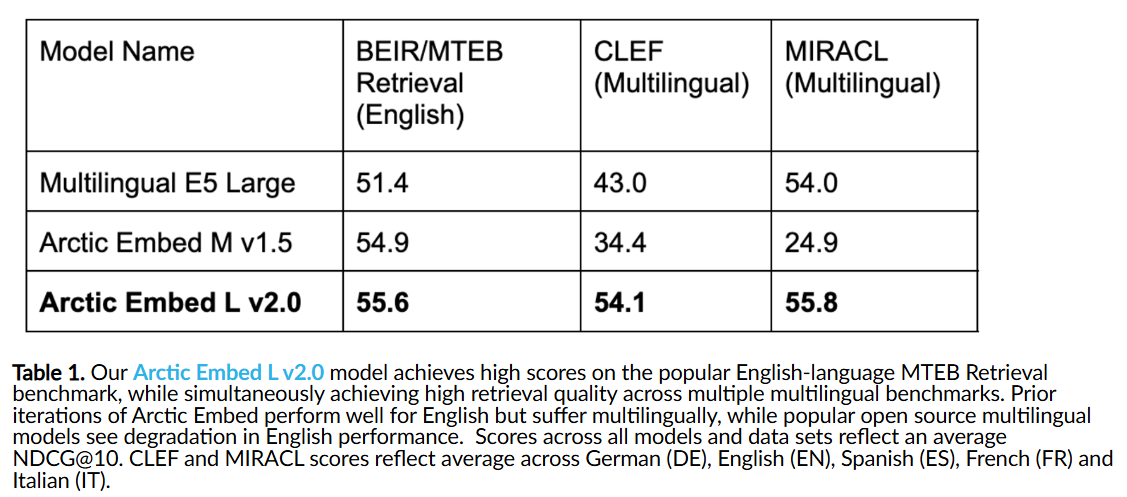
Arctic Embed 2.0, released under the Apache 2.0 license, allows organizations to modify and deploy models, ensuring wide applicability across various industries and use cases. This move underscores Snowflake’s dedication to democratizing AI tools, as highlighted by Clément Delangue, CEO of Hugging Face, who praised the contribution of these models to the global AI community. The models excel in in-domain evaluations like MIRACL and out-of-domain scenarios tested through CLEF benchmarks. This generalization is a critical improvement over earlier models, which often showed overfitting tendencies toward specific datasets.
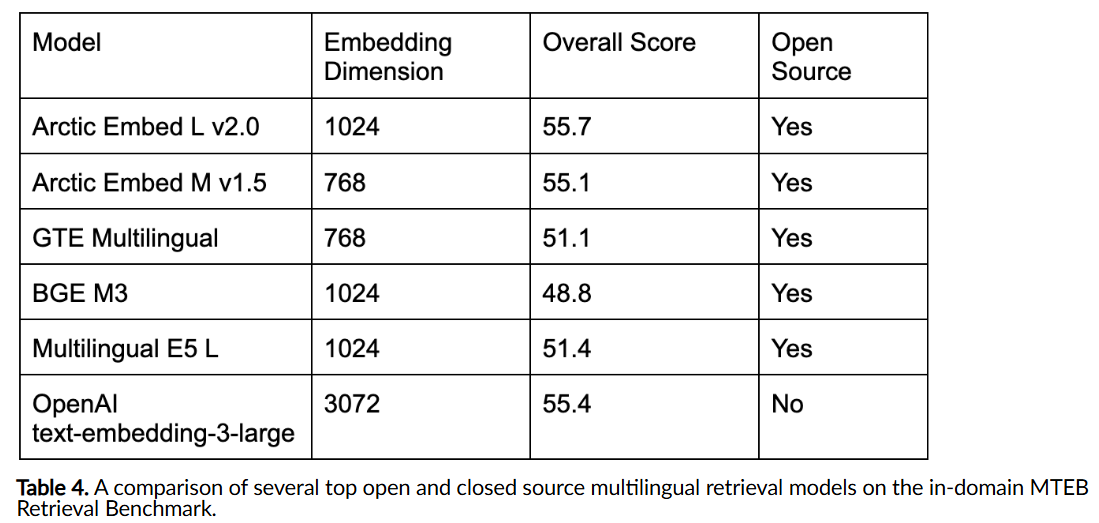
Compared with other open-source and proprietary models, Arctic Embed 2.0 is a leader in multilingual and English-language retrieval quality. While some existing models force users to choose between maintaining high English retrieval performance or adding operational complexity for multilingual support, Arctic Embed 2.0 offers a unified solution. Its multilingual embeddings eliminate the need for separate models, simplifying workflows while achieving top-tier results. Another highlight of this release is its support for enterprise-grade retrieval at scale. The models’ compact embeddings and robust performance make them ideal for businesses aiming to handle vast document repositories efficiently.
In conclusion, Arctic Embed L 2.0 and Arctic Embed M 2.0 represent a leap in multilingual embedding models. With their unparalleled efficiency, scalability, and quality, these models set a new standard for global-scale retrieval tasks. Snowflake’s release empowers organizations to address multilingual challenges effectively and reinforces its role as a trailblazer in the AI landscape.
Check out the Arctic Embed L 2.0 and Arctic Embed M 2.0. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Snowflake Releases Arctic Embed L 2.0 and Arctic Embed M 2.0: A Set of Extremely Strong Yet Small Embedding Models for English and Multilingual Retrieval appeared first on MarkTechPost.
