


The rapid advancement of AI technologies highlights the critical need for Large Language Models (LLMs) that can perform effectively across diverse linguistic and cultural contexts. A key challenge is the lack of evaluation benchmarks for non-English languages, which limits the potential of LLMs in underserved regions. Most existing evaluation frameworks are English-centric, creating barriers to developing equitable AI technologies. This evaluation gap discourages practitioners from training multilingual models and widens digital divides across different language communities. Technical challenges further compound these issues, including limited dataset diversity, translation-based data collection methods, etc.
Existing research efforts have made significant improvements in developing evaluation benchmarks for LLMs. Pioneering frameworks like GLUE and SuperGLUE advanced language understanding tasks, while subsequent benchmarks such as MMLU, HellaSwag, ARC, GSM8K, and BigBench enhanced knowledge comprehension and reasoning. However, these benchmarks predominantly focused on English-based data, creating substantial limitations for multilingual model development. Datasets like Exams and Aya attempt broader language coverage, but they are limited in scope either focusing on specific educational curricula or lacking region-specific evaluation depth. Cultural understanding benchmarks explore language and societal nuances but do not provide holistic approaches to multilingual model assessment.
Researchers from EPFL, Cohere For AI, ETH Zurich, and the Swiss AI Initiative have proposed a comprehensive multilingual language understanding benchmark called INCLUDE. The benchmark addresses the critical gaps in existing evaluation methodologies by collecting regional resources directly from native language sources. Researchers designed an innovative pipeline to capture authentic linguistic and cultural nuances using educational, professional, and practical tests specific to different countries. The benchmark consists of 197,243 multiple-choice question-answer pairs from 1,926 examinations across 44 languages and 15 unique scripts. These examinations are collected from local sources in 52 countries.
The INCLUDE benchmark utilizes a complex annotation methodology to investigate factors driving multilingual performance. The researchers developed a comprehensive categorization approach that addresses the challenges of sample-level annotation by labeling exam sources instead of individual questions. This strategy allows for a nuanced understanding of the dataset’s composition while managing the prohibitive costs of detailed annotation. The annotation framework consists of two primary categorization schemes. Region-agnostic questions, comprising 34.4% of the dataset, cover universal topics like mathematics and physics. Region-specific questions are further subdivided into explicit, cultural, and implicit regional knowledge categories.
The evaluation of the INCLUDE benchmark reveals detailed insights into multilingual LLM performance across 44 languages. GPT-4o emerge as the top performer, achieving an impressive accuracy of approximately 77.1% across all domains. Chain-of-Thought (CoT) prompting shows moderate performance enhancements in Professional and STEM-related examinations, with minimal gains in Licenses and Humanities domains. Larger models like Aya-expanse-32B and Qwen2.5-14B show substantial improvements over their smaller counterparts, with 12% and 7% performance gains respectively. Gemma-7B shows the best performance among smaller models, excelling in the Humanities and Licenses categories, while Qwen models show superiority in STEM and Professional domains.
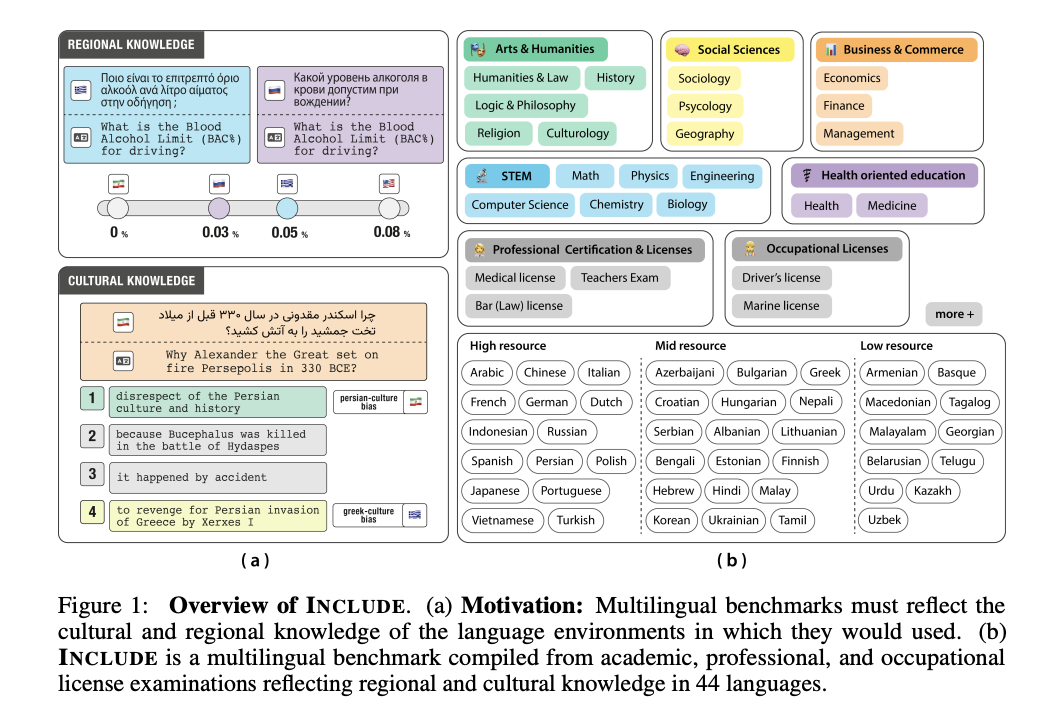
In conclusion, researchers introduced the INCLUDE benchmark which represents an advancement in multilingual LLM evaluation. By compiling 197,243 multiple-choice question-answer pairs from 1,926 examinations across 44 languages and 15 scripts, the researchers provide a framework for evaluating regional and cultural knowledge understanding in AI systems. The evaluation of 15 different models reveals significant variability in multilingual performance and highlights opportunities for improvement in regional knowledge comprehension. This benchmark sets a new standard for multilingual AI assessment and underscores the need for continued innovation in creating more equitable, culturally aware artificial intelligence technologies.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Partner with us]: ‘Next Magazine/Report- Open Source AI in Production’
[Partner with us]: ‘Next Magazine/Report- Open Source AI in Production’
The post Cohere AI Introduces INCLUDE: A Comprehensive Multilingual Language Understanding Benchmark appeared first on MarkTechPost.
