在人工智能(AI)领域中,如何为智能体创建高质量的训练和评估环境,一直是推动具身智能研究的重要课题。然而,目前大多数环境生成方法在多样性、交互性和可控性方面仍存在局限。
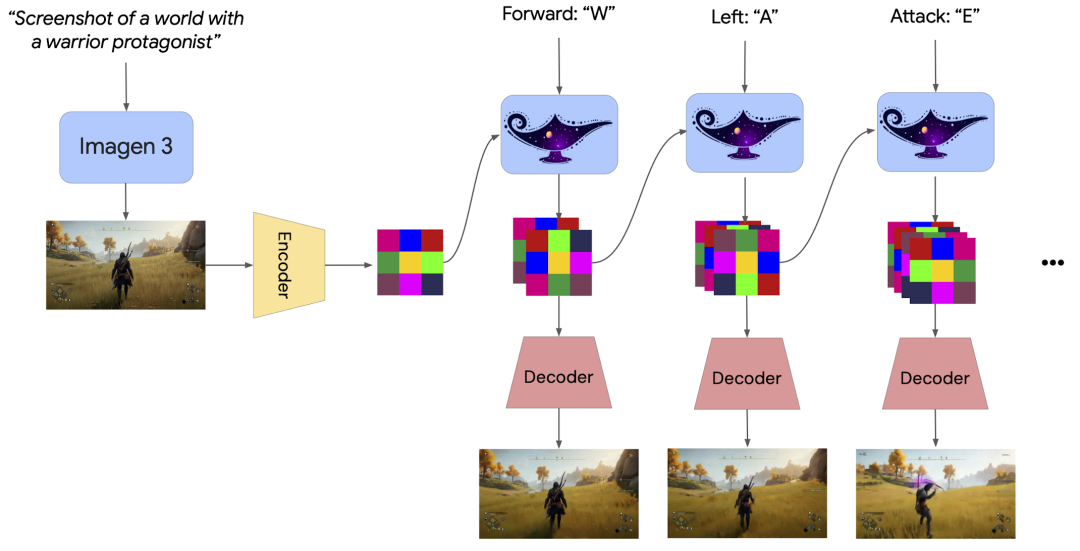
今日凌晨,Google Deepmind 推出了大型基础世界模型 Genie 2,其能够生成各种可控制动作、可玩的 3D 环境,可用于训练和评估具身智能体。基于单个提示图像,人类或 AI 智能体可以使用键盘和鼠标输入与之互动。
游戏在 AI 研究领域中扮演着重要角色。游戏的吸引力、独特的挑战组合和可量化的进展使其成为安全测试和推进 AI 能力的理想环境。
据悉,Genie 2 的推出将使未来的智能体能够在无限的新世界中进行训练和评估。这项研究也为开发交互原型体验的新型创意工作流程铺平了道路。
基础世界模型的新兴能力
到目前为止,世界模型在很大程度上局限于建模狭窄的领域。Genie 1 提出了一种生成各种 2D 世界的方法。而今日凌晨推出的 Genie 2 则进一步在通用性上实现巨大飞跃,可以生成种类繁多的丰富 3D 世界。
Genie 2 是一个世界模型,这意味着它可以模拟虚拟世界,包括采取任何动作(例如跳跃、游泳等)的后果。它是在大规模视频数据集上进行训练的,并且与其他生成模型一样展示了各种大规模的新兴能力,例如对象交互、复杂的角色动画、物理以及建模并预测其他智能体行为的能力。
任何人都可以用文字描述他们想要的世界,选择他们最喜欢的想法,然后进入这个新创建的世界并与之互动(或让 AI 智能体在其中接受训练或评估)。在每个步骤中,人类或智能体提供键盘和鼠标操作,然后 Genie 2 模拟下一个观察结果。Genie 2 可以生成长达 1 分钟的一致世界,大多数示例持续 10-20 秒。
Genie 2 可以智能地响应键盘上的按键操作,识别角色并正确移动。例如,在下面的示例中模型必须弄清楚箭头键应该移动机器人而不是树木或云朵。
Genie 2 可以从同一起始帧生成不同的轨迹,这意味着可以为训练智能体模拟反事实体验。在每一行中,每个视频都从同一帧开始,但人类玩家采取的动作不同。
Genie 2 能够记住视野中不再存在的世界部分,并在它们再次可见时准确呈现。
Genie 2 可以动态生成新的合理内容,并在长达一分钟的时间内维持一致的世界。
Genie 2 可以创建不同的视角,例如第一人称视角、等距视图或第三人称驾驶视频。
Genie 2 会创建复杂的 3D 视觉场景。
Genie 2 能模拟各种物体的相互作用,例如爆破气球、打开门和射击炸药桶。
Genie 2 学习了如何为不同类型的角色制作动画来执行不同的活动。
Genie 2 能够模拟其他智能体,甚至与它们进行复杂的交互。
10. 使用真实世界图像进行播放
Genie 2 还可以通过现实世界的图像进行提示,可以模拟风中摇曳的草或河中流动的水。
此外, Genie 2 还可以模拟水、烟雾、重力、灯光和反射等效果。
Genie 2 支持快速原型设计
Genie 2 可轻松快速地制作各种交互体验的原型,使研究人员能够快速尝试新的环境来训练和测试 AI 具身智能体。
例如用 Imagen 3 生成不同图像提示 Genie 2,使其生成模拟纸飞机、龙、鹰、降落伞飞行之间的差异,并测试 Genie 对不同对象的动画效果如何。
得益于 Genie 2 的分布式泛化能力,概念艺术和绘图可以转化为完全交互式的环境。这使得艺术家和设计师能够快速制作原型,从而推动环境设计的创意过程,进一步加速研究。
在世界模型中行动的 AI 智能体
扩散世界模型