

01
研究主题
在海量互联网文本上预训练过的大语言模型(LLM)展现出了对于世界知识的强大掌握能力。然而,尽管经过认真的清洗,现存的预训练语料中仍然不可避免地存在噪声,例如冲突、矛盾的知识。研究LLM面对冲突知识时的学习机制,对于理解LLM的知识学习过程、控制LLM的行为具有重要意义。
人类在面对包含冲突知识的文本时,往往会借助文本的其他特征来判断哪一个文本中的知识更值得学习。受此启发,本文探索了如下研究课题:(1)在面对冲突知识时,文本特征如何影响LLM的学习偏好?(2)如果存在偏好,偏好形成的原因是什么?
02
研究方法
为了对模型所学的知识进行直接的控制,本文基于构建的虚拟知识以探讨大语言模型的知识学习问题。
2.1虚拟知识、特征、特征模版与人物传记
本文中涉及的概念:
1、知识k: 关于一个虚拟人物的信息,包括birth date, birth place等。
2、冲突的知识:关于同一个人物的两则不同的信息。
3、文本特征:一则文本的某个属性,例如文本的风格,N-gram特征等。
4、模版T: 用来将知识组织成文本信息。不同的特征具有不同的模版。
5、人物传记T(k): 一则描述人物信息的文本,由将知识k填充入模版T得到。人物传记的集合记作I。
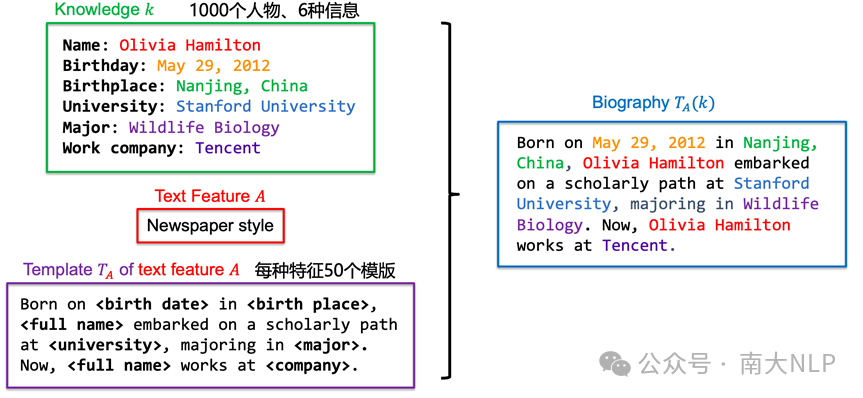 图1 知识、特征、模型和人物信息示例
图1 知识、特征、模型和人物信息示例
2.2 构造包含冲突知识的学习过程
在成功构建了人物的描述数据之后,下一步是构造具有冲突性质的知识。具体来说,我们将为每个人物构造两种相互冲突的知识,分别记为k_A和k_B。我们将k_A关联到一个特征,k_B关联到另一个不同的特征。这样,我们就可以研究模型在面对这两组特征时,会更倾向于学习哪一组特征。对于每一对冲突知识k_A和k_B,我们会将它们分别填充到对应特征的模板中,形成具体的人物传记。然后,我们会收集所有人物传记来微调现有的语言模型。
2.3 测试模型对于特征的偏好
在测试模型的学习倾向时,我们会每次针对人物的一个属性进行测试。针对训练阶段构造的两条冲突的知识,在测试阶段,我们会将这两条知识分别填入同一个模板中,然后观察模型对于每一条知识表述给出的概率,通过比较概率大小,我们能够计算出模型对于某一特征相对于另一特征的偏好程度。具体的计算公式如下图所示:
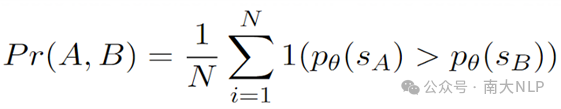
 图2 测试样本构造方式
图2 测试样本构造方式
2.4 基本的实验设置
在具体的实验设置中,我们的数据集包含了1000个人物,每个人物具有6种不同的属性。我们考察的文本特征有两种:风格和拼写正确性。在风格方面,我们考虑了以下几种:报纸(Newspaper)、科学报告(Scientific reports)、小说(Novels)、社交媒体(Social media)。在拼写正确性方面,我们考察了正确拼写(Good spelling)和错误拼写(Poor Spelling)。为了进行实验,我们为每一种特征生成了50个不同的模板。在英文模型测试方面,我们测试了llama-2-7B和pythia模型。而在中文模型测试方面,我们测试了deepseek模型以及Baichuan模型。
03
LLM 存在对特定文本特征的偏好
3.1 大语言模型对某些特征展现出了学习偏好
表1展示llama-2-7B模型对于不同特征的相对偏好情况。可以发现,模型对于报纸和科学报告风格的偏好明显高于对于小说和社交媒体风格的偏好。同时,我们也观察到在正式风格内部,以及非正式风格内部,模型的偏好并不明显。例如,模型在报纸和科学报告之间的偏好并不显著,同样,在小说与社交媒体之间的偏好也不明显。另一方面,我们也发现相比于拼写错误的数据,模型对正确拼写的数据有更明显的偏好。
表1 两种特征文本包含冲突知识时,LLM的相对学习偏好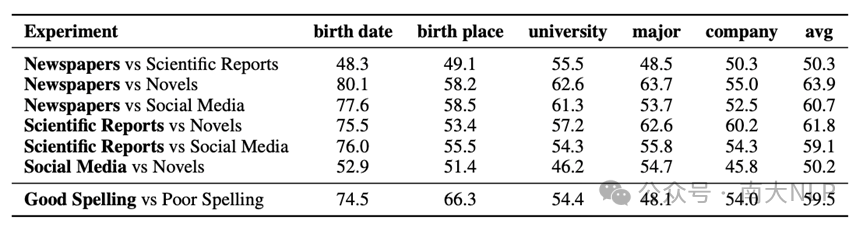
在多种风格混合的场景下,我们也进行了相应的测试。图3展示了在混合10种风格的文本且知识相互冲突时,测试文本与各种风格训练文本的知识一致性结果。图中显示,模型对于不同风格的偏好确实存在差异。模型对于科学文献风格的偏好是最强烈的,而对于那些更倾向于不正式的风格,如博客和社交媒体,其偏好则相对较低。
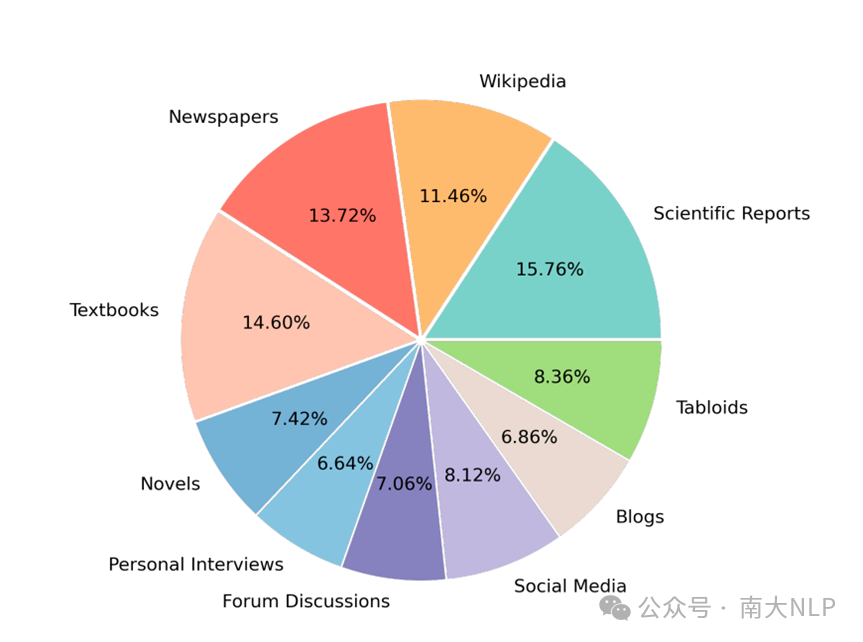 图3 多种风格文本混合训练时,模型对于不同风格文本中知识偏好结果
图3 多种风格文本混合训练时,模型对于不同风格文本中知识偏好结果
3.2 LLM学习偏好与测试模版风格无关
为了排除测试模板可能与某种训练风格模板过于接近的情况,我们直接使用了小说(novels)这一风格来进行测试文本的风格。结果显示,即便在这种特定情况下,模型仍然表现出了之前观察到的偏好,而不是对小说风格的偏好。这意味着模型的偏好并不是由于测试模板与训练数据中的某些风格相似而产生的,而是模型自身在学习过程中形成的一种稳定的偏好。
表2 使用Novels作为测试模版风格时,模型的特征偏好结果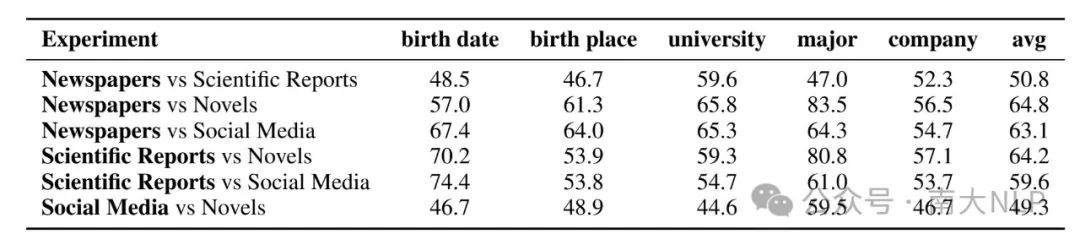
同时,我们还测试了不同模型和语言环境下的大语言模型,表3中展示了对应的结果。我们发现,在不同的模型和语言环境中,偏好的强弱可能会有所差异,但是总体上的趋势是保持一致的。
表3 不同模型、语言环境下,模型的特征偏好结果
3.3 不同文本表征影响LLM的学习速度
我们的第二个发现是,大语言模型在学习不同文本特征中的知识时,学习速度是不一样的。在这个实验中,我们训练了语言模型来学习包含不同特征风格的文本,并评估了模型在训练过程中的不同阶段对于给定陈述的生成准确率。每次训练时,我们只使用一种风格的文本。实验结果展示在图4中。实验结果显示,学习速度存在显著的差异。具体来说,科学文献风格的学习速度最快,其次是新闻风格。
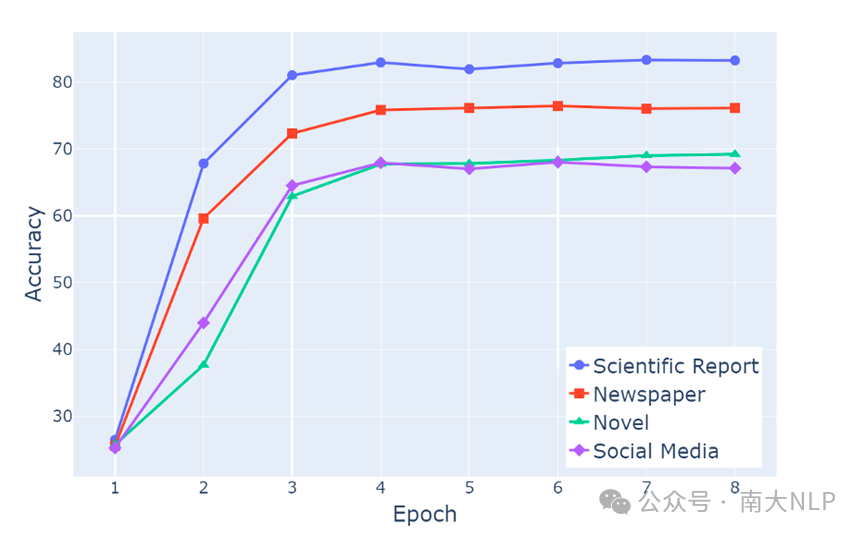 图4 模型对于不同风格文本中知识的学习速度
图4 模型对于不同风格文本中知识的学习速度
3.4 模型规模越大,其所展现出的偏好变化也就越强烈
我们进一步分析了不同参数规模的模型,从14M参数规模到12B参数规模的模型的表现情况。图5中我们发现,在模型参数达到160M之后,模型逐渐显示出明显的学习偏好。这种偏好随着模型参数规模的增大而变得更加显著,并且不同属性受到偏好影响的程度并不完全相同。这表明学习偏好可能是一种只在大规模语言模型中出现的复杂行为,而在较小规模的语言模型中则不会出现或者表现不明显。
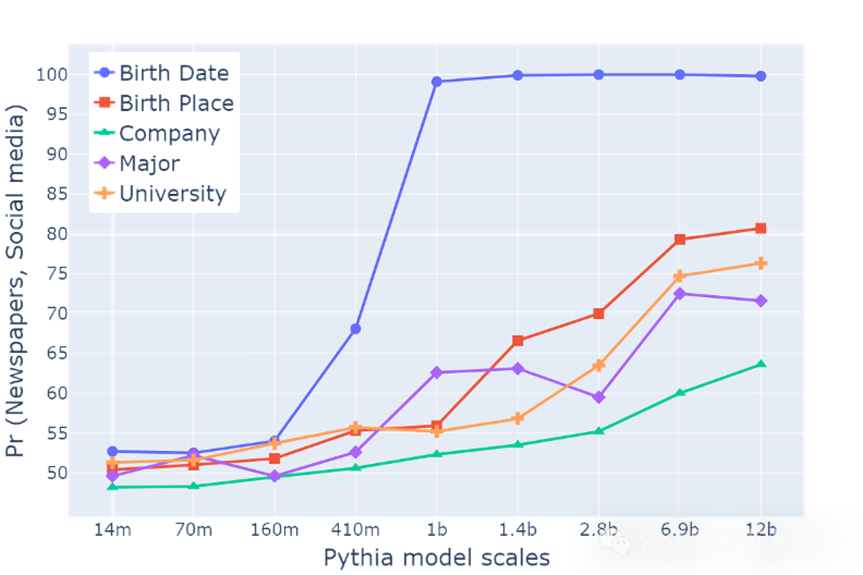 图5 不同大小模型的偏好强度
图5 不同大小模型的偏好强度
04
LLM特征偏好形成原因的解释
4.1 一致性驱动的特征偏好假设 (Consistency-Driven PreferenceHypothesis, CDPH)
针对大语言模型形成特定偏好的原因,我们有几个猜想:
首先,一个常见的想法是知识出现的频率影响了模型的测试结果。如果某个知识在训练过程中出现的频率越高,那么在测试时它应该会有更高的概率被模型选择。然而,在我们的实验中,冲突知识出现的频率是相同的,但我们仍然观察到了模型对某些知识的偏好。这表明偏好可能并不是直接与训练过程中的频率相关,而是可能与预训练过程中的某些因素有关。
第二个猜想是,在预训练过程中,文本特征出现的频率可能会影响模型的偏好。但是,这个猜想并不能解释那些不具备明显偏好的特征,比如小说风格和社交媒体风格。按理说,社交媒体的数据量肯定比小说风格的数据量大得多,但我们并没有观察到明显的偏好。这表明这些偏好可能来自于更高阶的特性。
因此,我们提出了一个猜想,即预训练过程中的知识一致性可能会影响模型的偏好。知识一致性指的是在预训练数据中,关于某个事实或信息的描述是否一致。例如,有两个文本,第一则文本信息来自Tech News, 声称Olivia是法国人,第二则文本,信息来自Morning News, 声称Olivia是德国人。如果训练集中其余大部分句子中都与第一则文本的知识一致(Olivia是法国人),那么Tech News的信息一致性就比Morning News知识一致性强,模型会认为Tech News是更可信的,这会导致模型在学习其他知识的时候也会偏好TechNews中的知识。
 图6 特征对应的知识一致性影响了模型对于特征可信度的判断
图6 特征对应的知识一致性影响了模型对于特征可信度的判断
本文将这个假设称作一致性驱动的特征偏好假设:大语言模型在训练过程中识别出数据中的不同特征,并且能够评估每个特征的知识一致性,也就是数据中包含该特征的数据是否与训练集中其他数据一致。基于这种知识一致性的评估,模型会在内部形成一个对特征的偏好等级。这种偏好等级会影响模型在微调阶段对知识的学习。最终,这种学习情况会在测试阶段表现出来,即模型对于某些特征表现出更强的偏好。图7中展示了对应的因果图。
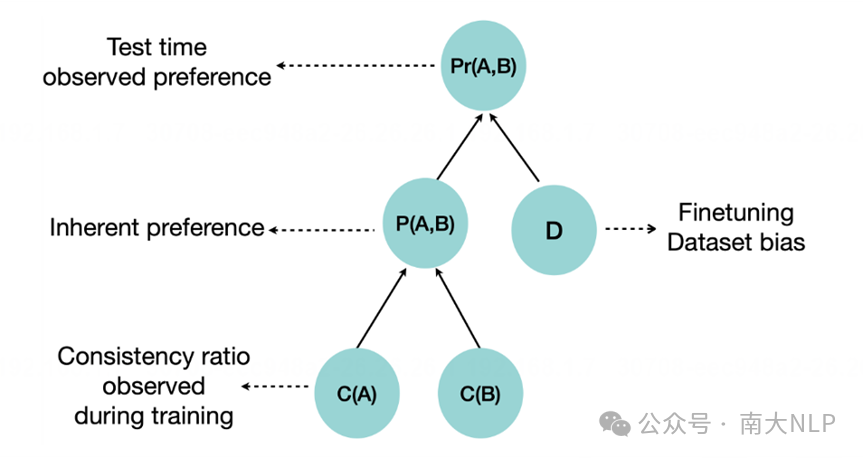 图7 一致性驱动的特征偏好假设因果图示
图7 一致性驱动的特征偏好假设因果图示
4.2 CDPH的验证方法
为了验证CDPH,我们首先构造了一些易于观察的文本特征。我们考虑了两种类型的特征:
1、命名特征:这类特征是基于特定的命名信息,例如我们构造了一个特征,它涉及新闻来源的名称,比如 "Tech News" 或 "Morning News"。这样的特征可以直接从文本中识别,因为它们是明确命名的实体。
2、计算特征:这类特征更为复杂,需要通过代数运算来确定。我们构造了一个特征,它基于文本来源的卷号。如果卷号小于1000,则属于一种特征;如果卷号大于1000,则属于另一种特征。这种特征需要模型理解和执行一定的计算逻辑来确定。
通过构造这些特征,我们可以研究不同的一致在实验中更清晰地观察模型是否能够识别和偏好这些特征,以及这些特征的一致性如何影响模型的学习过程。
对CDPH进行验证的核心是构造不同特征的支持集,通过支持集的大小来控制不同特征的知识一致性程度。我们首先把知识分成两个集合,分别是证据知识集合和测试知识集合。
1、证据知识集合用来帮助模型学习到特征的知识一致性程度。对于每一条冲突知识,我们会为它的两个版本(记作KA/KB)分别加入一些支持文本。这些支持文本本身不带有特定的文本特征,但它们中包含的知识要么与KA一致,要么与KB一致。通过控制支持KA和KB的文本的数量,我们可以调节A特征属性和B特征属性的知识一致性程度。这样,在训练过程中,我们可以观察模型如何根据这些一致性程度来形成学习偏好。
2、测试知识集合用来构造另一批冲突的数据。这些数据是我们在测试阶段需要评估的知识。模型在微调过程中学习了该集合中的知识后,在测试阶段会被评估。
通过这种方式,我们确保了在训练过程中,各特征的出现频率保持一致,测试知识的出现频率也保持一致。这样的实验设计使我们能够准确地评估模型对不同特征知识一致性的学习偏好,而不受特征频率或知识频率变化的影响。
 图8 一致性驱动的特征偏好假设验证方案
图8 一致性驱动的特征偏好假设验证方案
4.3 控制知识一致性比例可为模型注入新的特征学习偏好
我们对Source Name 和 Source Time 两种特征的偏好结果进行了实验,知识一致性程度比例为9:1。如图9所示,在微调的初始阶段,模型并没有展现出明显的特征偏好。然而,随着训练的进行,模型开始学习到两个特征具有不同的知识一致性程度,开始逐渐形成了显著的偏好。
图中展示了控制知识一致性程度的比值时,模型对特征的偏好程度变化情况。可以看到:随着一致性比值的增加,语言模型对那些具有更高一致性程度的特征也会随之增大。
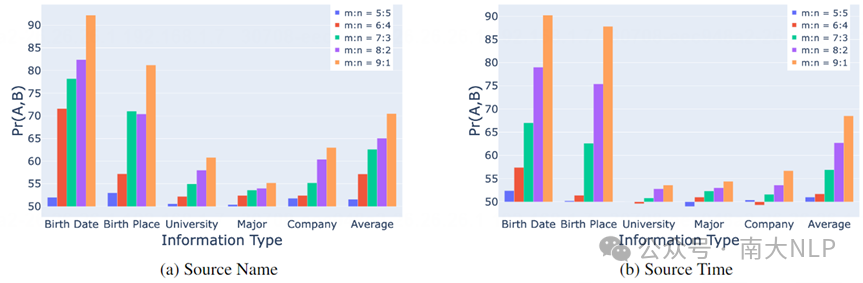 图9 模型偏好强度随着支持集比例变大而变大
图9 模型偏好强度随着支持集比例变大而变大
4.4 调整知识一致性比例可消除/反转模型已经获得的偏好
最后,我们还进行了一项反事实的因果实验,旨在通过控制一致性程度来消除和反转语言模型中已经形成的偏好。在前面的实验中,我们观察到语言模型已经形成了“报纸”大于“小说”的偏好。在微调训练阶段,我们通过调整支持集(即训练数据集)来改变“报纸”和“小说”信息的一致性程度。图10中是对应结果。我们发现,当我们把“报纸”和“小说”的一致性程度调整为1:1(即5:5的比例)时,原有的偏好被消除了。进一步地,当我们调整一致性程度,使得“小说”信息的支持增加到“报纸”信息的9倍时,原有的偏好被反转了。模型现在表现出了对“小说”信息的偏好。
图10 模型中已经存在的Newspaper vsNovel 的偏好程度可通过设置不同的支持集比例消除甚至逆转
05
结论
LLM如何学习包含冲突知识的数据是一个值得深入研究的科学问题。本文通过在合成知识上的实验,揭示了大语言模型面临冲突知识时,更加倾向于偏好正式的、拼写正确的文本。进一步分析发现,包含特定特征的文本与其他数据的一致性程度是决定模型学习偏好程度的关键因素。一致性越高,模型对该特征的偏好越强。通过调整不同特征的知识一致性程度,我们可以为模型注入新的知识学习偏好,并可以消除甚至反转模型中现存的偏好。我们希望本文可以为研究LLM的知识学习机制带来新的视角。
论文:https://aclanthology.org/2024.emnlp-main.572
代码:https://github.com/CaoYiqingT/Formality-is-Favored
B站视频讲解:
https://www.bilibili.com/video/BV1khSKYSEKT/?
