11 月 19 日,d-Matrix宣布其首款商用芯片Corsair已开始向早期客户发货。同时,他们还公布了产品令人瞩目的性能数据;在Llama2 7B模型上,Corsair输出每个词元的速度相较于Nvidia的H100快20倍(参见白皮书,https://www.d-matrix.ai/wp-content/uploads/2024/11/d-Matrix-WhitePaper-Technical-FINAL.pdf)。
乍一看,这似乎预示着我们手握一款GPU杀手。然而,与大多数AI芯片公司一样,公开的性能数据仅仅只是一部分。d-Matrix的技术和性能令人印象深刻,对于某些客户而言,它或许是理想之选,但它并不是适用于所有场景的GPU替代品。
d-Matrix正在基于数字内存中处理(PIM)架构开发芯片。与Groq、MatX和SambaNova等公司相比,这使得d-Matrix的芯片在技术上更具创新性和吸引力。显然,新颖并不意味着更好,但一家初创公司对一种新型芯片的成功商业化,让我感到十分兴奋。我也乐于看到内存中处理技术取得成功;今年早些时候,我出售了我在2021年创立的用于加密领域的PIM公司。
遗憾的是,若细读d-Matrix的白皮书,其激荡的叙述中便显露出些许不足。尽管d-Matrix的芯片令人振奋,十分新颖,但对于大多数客户而言,它们可能并不具备成本效益。具体来说,其令人瞩目的基准测试成绩均基于芯片运行在“性能模式”下,而这种模式在实际基础设施部署中未必能实现。
1
“性能模式”
d-Matrix所有令人瞩目的性能数据均指出,芯片正在“性能模式”下运行。这正是d-Matrix 宣称其优势所在;根据其白皮书,若从性能模式切换到“容量模式”,Corsair的性能会急剧下降。
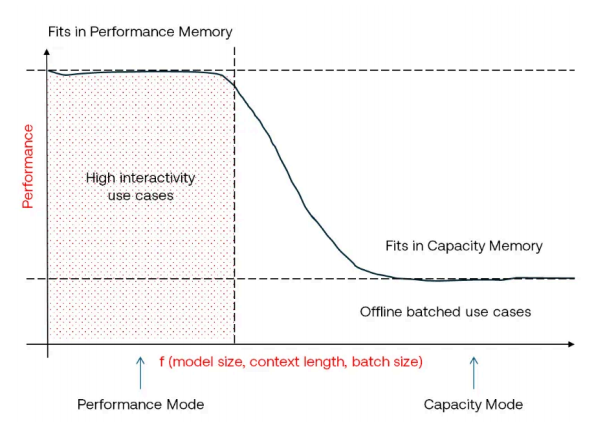
仔细阅读白皮书,我们会发现,性能模式指的是整个模型能够存储在片上SRAM中的状态。记得我有关Groq的文章(https://www.zach.be/p/why-is-everybody-talking-about-groq)的读者可能已经猜到这会引向何处。如果想将一个大型模型完全放入片上SRAM,这将需要大量的芯片,这使得基础设施成本大幅增加。
在容量模式下,d-Matrix将额外的模型权重存储在外部DRAM中。他们的系统中没有配备HBM,这意味着一旦模型过大无法装入SRAM,性能会大幅下降。这或许解释了为何他们未广泛公开容量模式的性能数据;我预计,其性能会低于英伟达配备HBM的H100 GPU所能达到的水平。
这意味着构建高性能的d-Matrix系统将会相当昂贵。如果API提供商希望服务于许多不同的微调模型,或是服务于像Llama 405B这样的超大型模型,他们需要购买大量d-Matrix系统机架以获得可接受的性能。
幸运的是,d-Matrix似乎非常清楚这一局限性,并正在竭尽全力减少其全SRAM策略对其系统成本效益的影响。即便在所谓的性能模式下,他们也能在一个机架中将Llama 70B完全部署在SRAM上。作为参考,在Groq硬件上运行Llama 70B需要8个机架(https://www.zach.be/p/why-is-everybody-talking-about-groq)。
他们是如何做到的?答案是:利用新的数字格式和极其密集的计算能力。
2
块浮点推理
2023 年,包括微软、英伟达和Meta在内的行业联盟提出了一套名为微缩(Microscaling)数据格式的新数据格式(https://arxiv.org/pdf/2310.10537)。这些新格式包括所谓的块浮点格式,如MXINT8和MXINT16。[1] 这些格式具有多个共享指数的整数值(https://proceedings.mlr.press/v162/yeh22a/yeh22a.pdf),如下图所示:
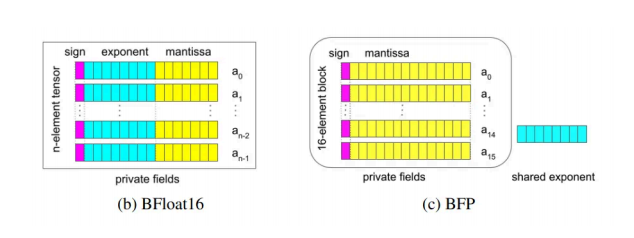
仅有少数芯片支持这些新型数据格式(https://en.wikipedia.org/wiki/Block_floating_point),包括AMD的部分边缘AI NPU、Tenstorrent的Grayskull和Wormhole芯片,以及最为突出的d-Matrix的Jayhawk和Corsair芯片。MXINT8显著简化了机器学习模型的内存格式;通过将众多不同的指数替换为单一共享指数,可以干净利落地消除大量需要存储在芯片上的比特(位)。这也是为何d-Matrix在部署整个模型于芯片SRAM时所需芯片数量少于Groq的原因之一。
但块浮点运算对d-Matrix来说还有另一个重要原因。传统的浮点运算对于内存处理芯片来说相当复杂。要想添加浮点数,需要将它们转换为相同的指数。这涉及到对尾数(mantissa)进行位移操作,这在内存阵列内部并行处理时非常困难,因为每个尾数可能需要按不同的量进行移位。
借助MXINT8数学运算,d-Matrix能够利用内存处理核心,这些核心在定点运算方面提供了极高的效率(https://ieeexplore.ieee.org/document/9365766),从而加速大语言模型所需的浮点计算。这一点至关重要,因为内存处理技术使得d-Matrix能够部署计算密度和内存密度远超竞争对手的芯片。
3
计算密度的价值
Groq的每张卡提供230MB片上SRAM。d-Matrix的每张卡则提供2GB。d-Matrix是如何做到比其竞争对手多出10倍的SRAM?答案在于内存中处理技术及其带来的极高密度。
在GPU和传统AI芯片中,神经网络的权重、输入和参数存储在片上内存中。当需要使用这些权重进行计算时,必须将它们从内存移至寄存器,计算过程中它们就存储在寄存器里。在内存与寄存器之间移动数据既耗时又耗能,且这些寄存器本身也占用芯片面积。
内存中处理(PIM),亦称内存中计算(CIM)或内存计算(IMC),将 SRAM 存储器与计算逻辑紧密集成于一个高密度模块中,如图所示:
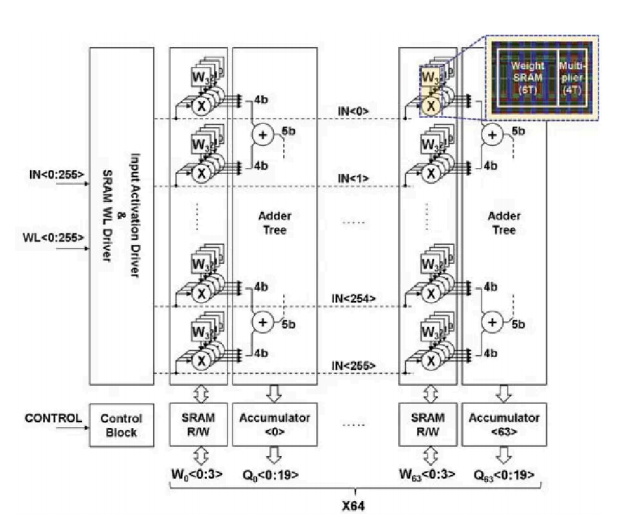
在PIM架构中,无需将数据从内存传输到寄存器再传回。相反,直接在数据仍处于内存中时进行计算。这消除了在内存与寄存器之间来回传输数据所需的大量电力。大多数PIM概述都强调这种能效是该技术提供的关键价值。
PIM在计算密度方面也提供了显著优势。通过消除大型且昂贵的寄存器和ALU,PIM架构能够将更多芯片面积用于片上SRAM。更多的片上SRAM意味着对片外DRAM的访问次数减少。而由于DRAM访问是AI芯片中最大的延迟和能效瓶颈,更高的计算密度可以在规模上显著提升性能。
4
d-Matrix的芯片性价比高吗?
无论PIM技术多么令人振奋,我不确定它是否能降低d-Matrix芯片的成本效益。客户仍需购买一整个机架的芯片才能高效运行Llama-70B。对于那些愿意为超低延迟推理支付高额前期成本的客户来说,这或许合理,但对绝大多数潜在客户而言,可能并不划算。
然而,我认为d-Matrix正在开辟一条通向更高效的AI计算道路。通过结合块浮点数学和超密集的PIM架构,d-Matrix能够使其芯片在成本效益上远超其最接近的竞争对手Groq。如果d-Matrix在其未来架构中引入HBM以提升对那些无法完全装入SRAM的大型模型的性能,我认为,他们将成为AI芯片领域中极具竞争力的一员。
[1] MXINT8是一种块浮点格式。