
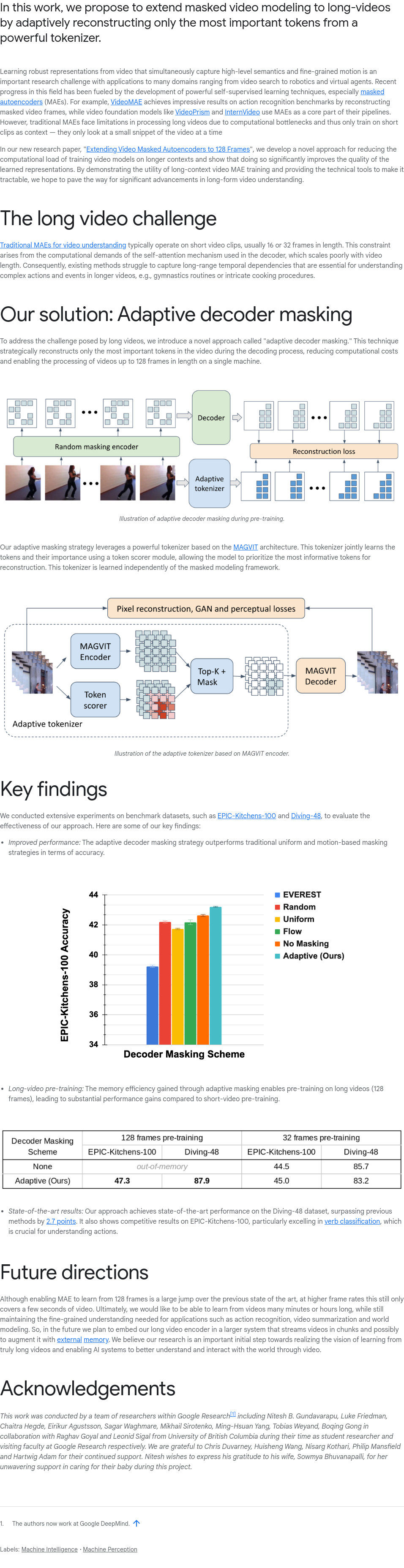
本文提出了一种扩展masked视频建模至长视频的方法,通过从强大的tokenizer中自适应地重建最重要的tokens来实现。从视频中学习能够同时捕捉高层次语义和细粒度运动的鲁棒表示是一项重要的研究挑战,广泛应用于视频搜索、机器人技术及虚拟代理等领域。近年来,随着强大的自监督学习技术的发展,尤其是masked自编码器(MAEs)的应用,该领域取得了显著进展。例如,VideoMAE在动作识别基准测试中表现出色,而VideoPrism和InternVideo等视频基础模型也以MAEs为核心组件。然而,传统MAEs在处理长视频时面临计算瓶颈,只能基于短片段进行训练。为解决这一问题,本研究提出的新方法旨在克服现有技术的局限性,提高对长视频的处理能力。
本专栏通过快照技术转载,仅保留核心内容
转载内容中包含的图片若涉及版权问题,请及时与我们联系删除
