


Contrastive language-image pretraining has emerged as a promising approach in artificial intelligence, enabling dual vision and text encoders to align modalities while maintaining dissimilarity between unrelated embeddings. This innovative technique has produced models with remarkable zero-shot transfer capabilities, demonstrating significant potential in complex computational tasks. However, large-scale pretraining encounters challenges in out-of-distribution generalization when downstream data distributions deviate from initial training datasets. Researchers have discovered that additional data at test time becomes essential for adapting to severe visual distribution shifts and capturing more nuanced contextual information. Post-hoc adaptation strategies, including model finetuning, prompt tuning, and adapter training, have been explored to address these limitations.
Contrastive image-text pretraining has rapidly evolved into the standard approach for developing large-scale visual representation models. Initially pioneered by frameworks like CLIP and ALIGN using an InfoNCE-style training objective, subsequent research has focused on enhancing zero-shot transfer capabilities. Innovations such as SigLIP have introduced more efficient pretraining methods, utilizing pairwise sigmoidal losses while achieving comparable or improved performance. Researchers have explored various strategies to improve generalization, including utilizing external support data and innovative training memory techniques. The field of meta- and few-shot learning has been particularly focused on developing methods that can rapidly adapt to new data distributions, with approaches ranging from optimization-based techniques to metric-based learning strategies.
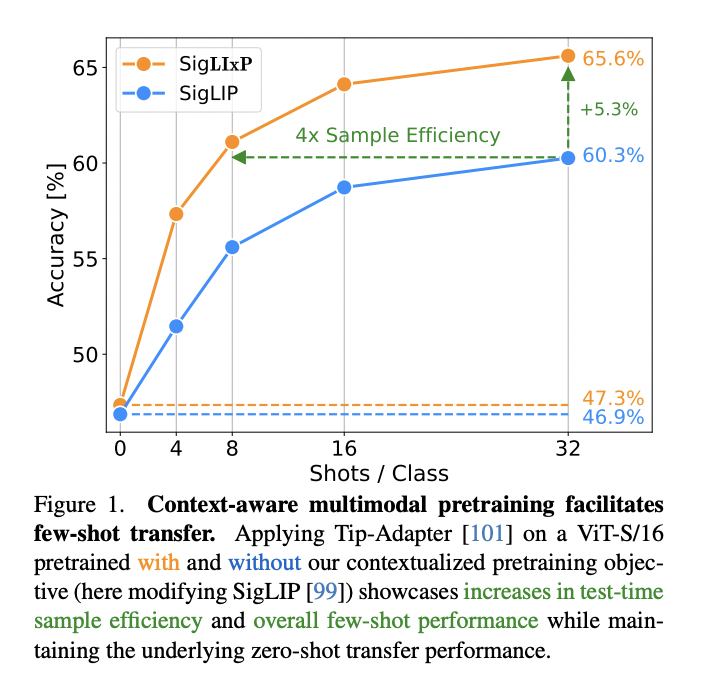
Researchers from Tubingen AI Cente, Munich Center for MLHelmholtz Munich, TU Munich, and Google DeepM challenge existing assumptions about multimodal model training by demonstrating that models can be significantly optimized for training-free few-shot adaptation without compromising zero-shot transfer capabilities. The study introduces LIxP (Language-Image Contextual Pretraining), a carefully designed context-aware extension to contrastive language-image pretraining. By augmenting standard objectives with cross-attention-based contextualization during training, LIxP prepares representations for metric-based adaptation. The researchers meticulously designed the approach to maintain base zero-shot capabilities, employing strategic loss design and individually learnable temperatures. Remarkably, across 21 few- and many-shot downstream classification tasks, LIxP achieved up to four-fold sample-efficiency gains and over 5% average performance improvements while preserving original zero-shot transfer performance.
The technical foundations of contrastive language-image pretraining introduce a sophisticated context-aware extension called LIxP. The approach centers on a unique contextualization mechanism using key and value context buffers that provide a proxy for test-time context during pretraining. By introducing normalized contextualized representations through cross-attention, the method aims to enhance metric-based adaptation capabilities. Critically, the researchers developed an innovative training objective that carefully balances representation learning, maintaining zero-shot generalization while improving few-shot adaptation performance. The approach introduces multiple learnable temperatures and a unique buffer design that allows joint population and backpropagation of image representations, creating an implicit per-iteration episodic training strategy.
The research extensively evaluated the LIxP approach across various model sizes, datasets, and few-shot adaptation methods. Using ViT image encoders and BERT text encoders, the team tested context-aware pretraining on 21 diverse datasets. Key findings revealed significant improvements in few-shot adaptation performance with minimal impact on zero-shot capabilities. The method demonstrated consistent gains across different model scales, from ViT-S/16 to ViT-L/16, and across training data volumes ranging from 1.5B to 15B examples. Notably, the approach achieved up to 4× sample efficiency, with performance improvements ranging from 1.7% to 5.4% across different metric-based adaptation methods. The researchers also explored post-training contextualization, showing that even brief additional training could match or outperform models trained on significantly more data, highlighting the method’s potential for efficient model adaptation.
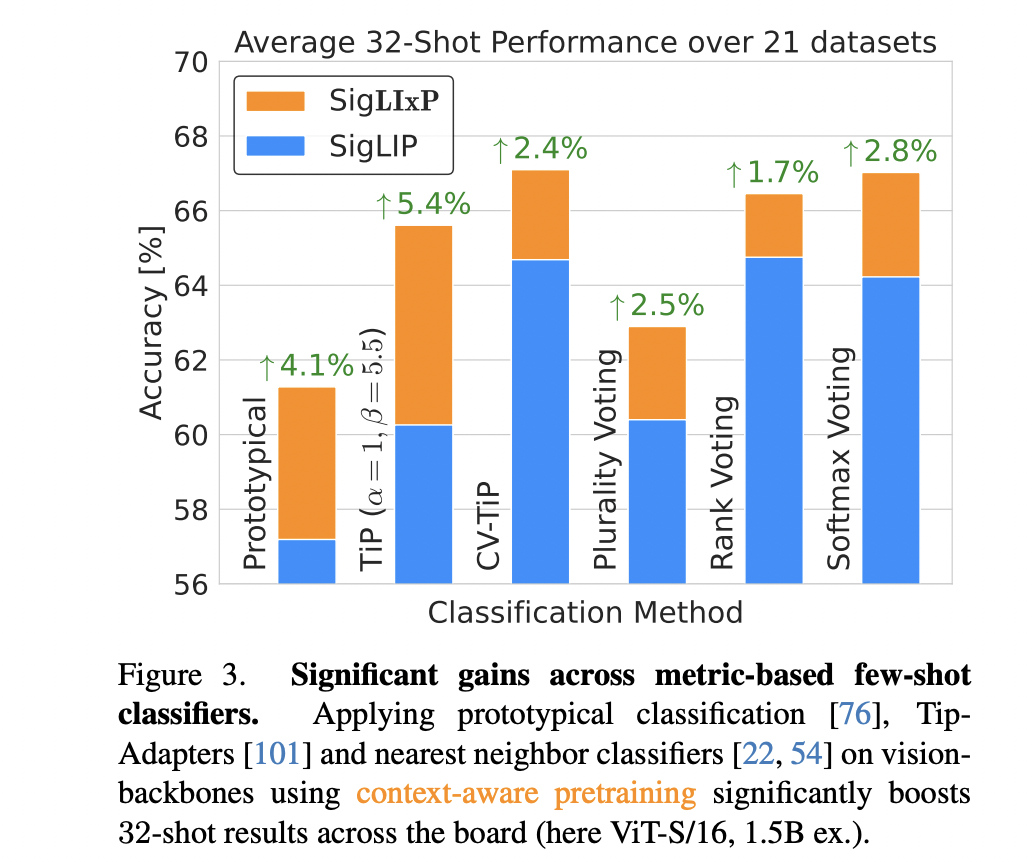
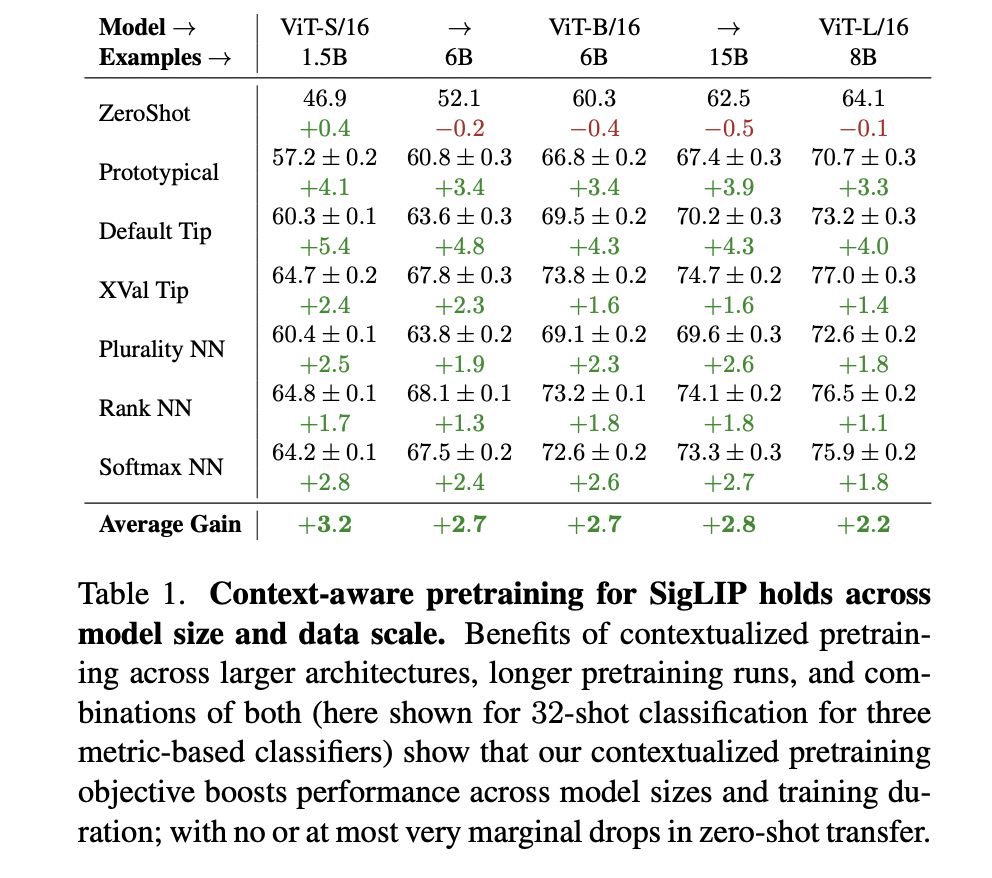
The research introduces an innovative context-aware pretraining objective designed to enhance vision-language representation learning for few- and many-shot visual context adaptation. The innovative approach enables training-free, metric-based adaptation at test time without compromising zero-shot transfer capabilities. By conducting comprehensive evaluations across 21 diverse visual adaptation tasks, the researchers demonstrated remarkable achievements, including up to four-fold improvements in test-time sample efficiency and consistent performance gains exceeding 5% in average few-shot performance. Critically, these substantial improvements remained consistent across varying model sizes and training data volumes, effectively narrowing the performance gap with more complex optimization-based strategies and showcasing the potential of simple, scalable pretraining techniques to significantly enhance test-time adaptation capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.

 ‘
‘The post Can You Turn Your Vision-Language Model from a Zero-Shot Model to Any-Shot Generalist? Meet LIxP, the Context-Aware Multimodal Framework appeared first on MarkTechPost.
