

https://arxiv.org/abs/2411.04996

介绍
近年来,多模态基础模型(multi-modal foundation models)已成为人工智能领域的一项突破性进步,使单一模型能够处理和理解多种数据类型,如文本、图像甚至语音。这些模型在从内容创建和图像生成到复杂的跨模态翻译任务等各种应用中都具有巨大的潜力,在这些任务中,人工智能可以解释和生成不同格式的信息。然而,尽管这些功能前景光明,但训练大型多模态模型仍面临着巨大的计算(computational)和可扩展性(scalability)挑战。与基于单一数据类型进行训练的单模态模型不同,多模态模型需要大量数据集和大量计算能力来处理不同模态的不同结构和特征。
传统密集 Transformer 模型的最大障碍之一是“一刀切”方法。这些模型在不同模态中应用相同的参数和训练技术,这通常会导致资源使用效率低下和训练动态冲突。例如,在同一模型中处理文本、图像和语音可能会造成瓶颈,从而减慢训练速度并增加计算成本。随着对多模态 AI 的需求不断增长,更高效的解决方案对于平衡高性能和合理的计算成本至关重要。
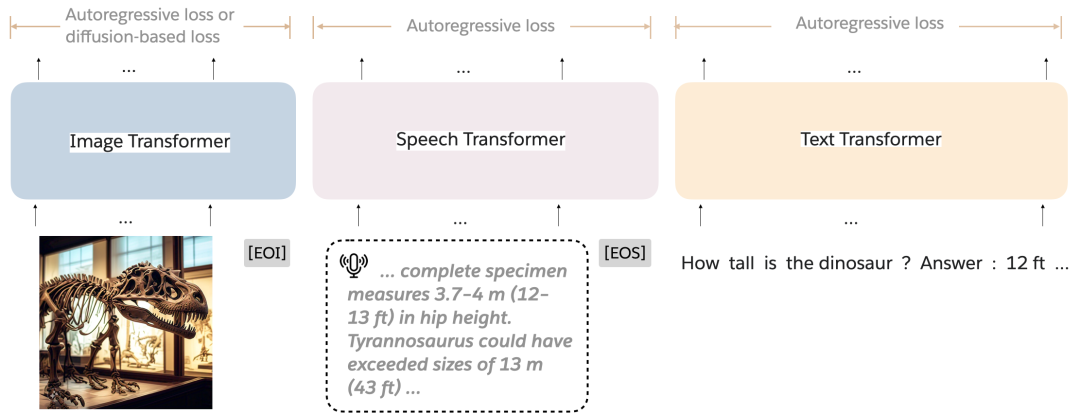
混合Transformer (MoT) 架构。MoT 是一种生成模型架构,旨在处理任意交错模态(例如文本、图像和语音)的序列。每种模态都采用一组单独的非嵌入变换器参数 - 包括前馈网络、注意矩阵和层规范化。在训练期间,可以使用特定于模态的损失来监督每种模态。
混合 Transformers (MoT) 是一种专为应对这些挑战而设计的新型稀疏架构。与密集模型不同,MoT 通过“特定于模态的参数解耦”引入了一种处理多模态输入的独特方法,其中对每种数据类型使用单独的参数集。这不仅可以减少计算负荷,还可以单独优化每种模态,从而在不牺牲质量的情况下提高效率。在本博客中,我们将探讨混合 Transformers 模型如何重新定义多模态基础模型,以极低的计算成本提供高性能。
传统密集模型在多模态学习中的问题
计算成本高:传统的密集 Transformer 模型在所有数据模态(例如文本、图像、语音)中应用相同的参数和架构。这导致计算资源的使用效率低下,因为每种模态都有独特的特性,需要不同的优化。
训练动态冲突:当密集模型同时处理多种模式时,它们可能会遇到训练动态冲突。这意味着针对一种模式优化模型可能会对另一种模式产生负面影响,从而降低模型的整体有效性,并需要更多资源进行微调
扩展的资源强度:为了在多模态任务上实现高性能,密集模型需要大量数据和计算能力。例如,密集多模态模型 Chameleon 需要 9.2 万亿个 token 才能实现与使用少得多的 token 训练的单模态模型相当的性能。
跨模态的统一处理:密集模型统一处理所有输入,将文本、图像和语音视为类似类型的数据,尽管它们在结构上存在差异。这种统一方法可能会导致效率低下,并限制模型在各个模态中表现出色的能力。
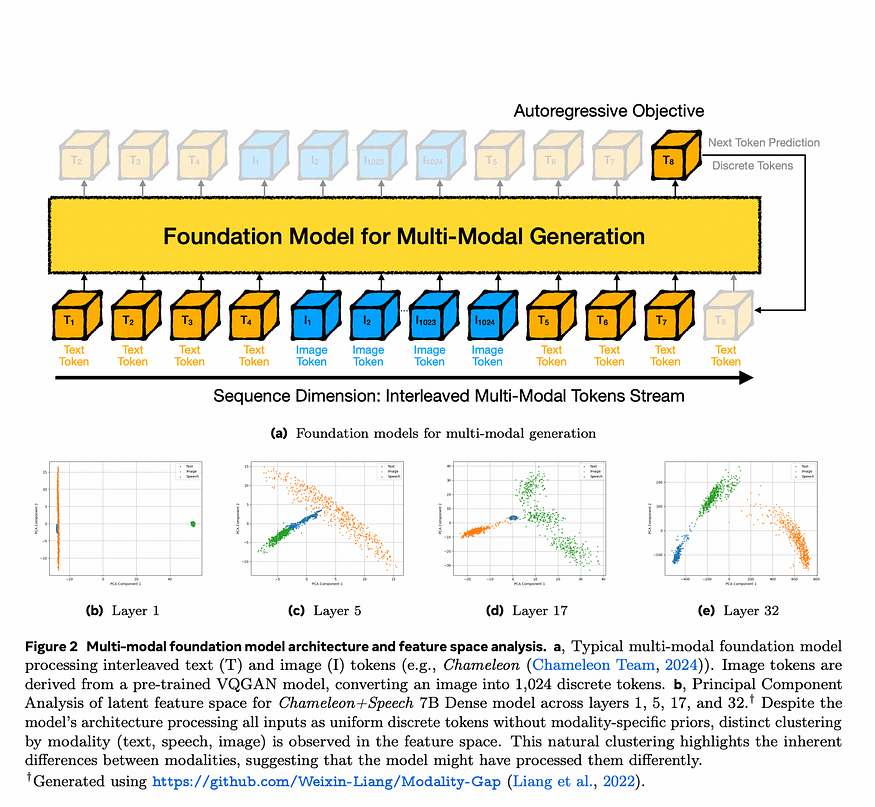
如上图所示,该模型将文本和图像标记(如单词和图像片段)的混合序列作为单个流进行处理。它使用自回归方法,预测序列中的下一个标记,无论是文本还是图像的一部分。使用预训练模型将图像分解为离散标记(如图像片段列表),因此该模型可以像处理文本一样处理图像。
随着模型跨层处理数据,它自然会开始将不同类型的标记(文本和图像)分组到其特征空间中的单独群集中,尤其是在更深的层中。这表明模型区分数据类型的能力不断增强。即使此模型以统一方式处理所有数据,它仍然会在内部学习区分文本和图像,这表明添加特定于模态的组件(例如 Mixture-of-Transformers)可以进一步增强这种分离并提高效率。
对稀疏架构的需求不断增长:稀疏架构(如混合专家 (MoE) 模型)旨在通过仅激活每个模态的模型参数子集来解决这些问题。然而,MoE 模型面临着专家利用不平衡等挑战,需要复杂的路由算法,这会增加进一步的计算负荷。
为了应对这些挑战,混合 Transformers (MoT) 架构被开发为一种稀疏、多模态模型。通过基于模态解耦参数,MoT 降低了计算要求并缓解了密集架构中出现的训练冲突。以下部分将探讨 MoT 的架构及其在处理文本、图像和语音任务时的出色效率,同时不影响性能(混合 Transformers)。
混合 Transformer(MoT)简介
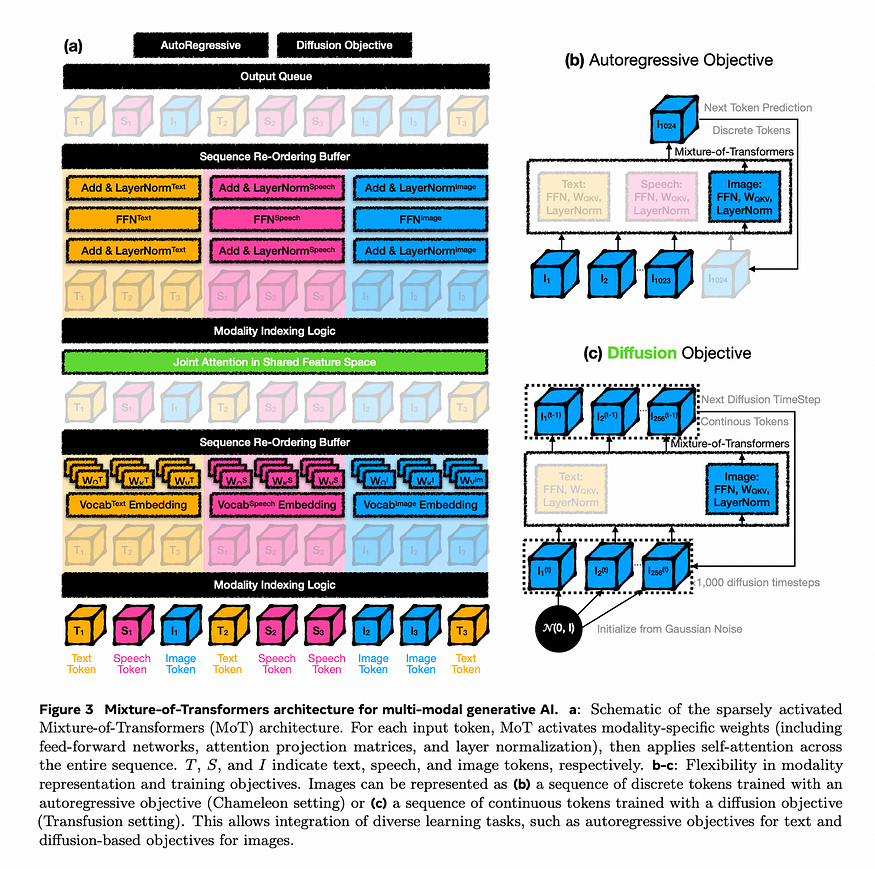
什么是Mixture-of-Transformers(MoT)?
MoT 是一种稀疏、多模态Transformer架构,专门设计用于解决多模态模型的扩展挑战。
与传统的密集 Transformer 不同,MoT 引入了特定于模态的参数解耦。这意味着 MoT 不会在所有模态中使用同一组权重,而是为每种模态(例如文本、图像、语音)分配不同的参数。
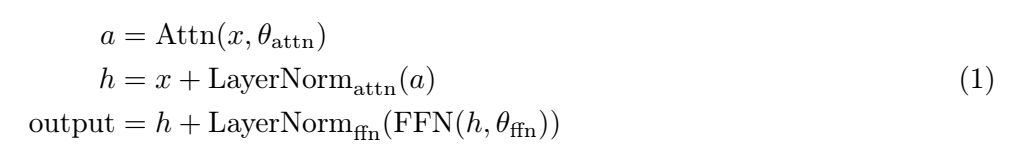
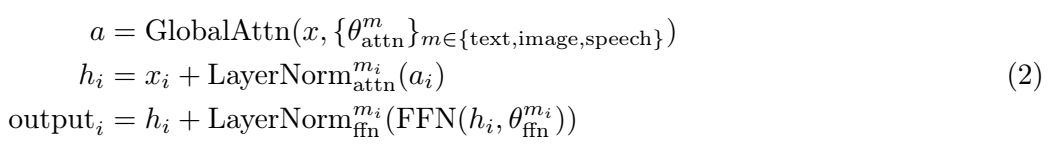
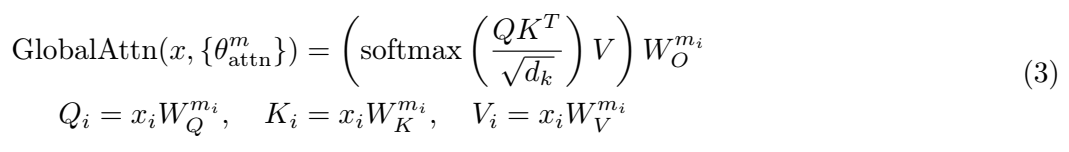
特定模态参数解耦
MoT 在关键领域按模态解耦参数:前馈网络、注意力矩阵和层规范化。每种模态(文本、图像、语音)都有一组专用于这些组件的参数,这使得它能够更有效地处理每种类型的数据。
这种方法允许对每种模态进行专门处理,同时仍保持对整个输入序列的全局自注意力。这意味着,尽管模型对每种模态都有单独的路径,但它仍然可以在统一的框架中捕获跨模态的关系
稀疏、高效的处理
MoT 的架构可以实现参数的稀疏激活,从而大幅减少模型的整体 FLOP(每秒浮点运算次数),同时又不牺牲准确性。
例如,在 Chameleon 设置(专注于文本和图像生成任务)中,MoT 实现了与密集模型相当的性能,但仅使用了 55.8% 的 FLOP。当添加语音作为第三种模态时,MoT 实现了与密集模型相当的性能,但仅使用了 37.2% 的 FLOP。
跨模态的全局自注意力
尽管 MoT 使用特定于模态的参数,但它会在整个输入序列中保持全局自注意力。此功能允许 MoT 以连贯的方式处理多模态数据,捕捉跨模态关系,同时保留每种模态的独特属性。
这对于复杂的多模式任务尤其有价值,例如生成结合文本、图像和语音信息的描述。
灵活适应不同的模式和目标
MoT 旨在处理每种模式的不同任务和目标。MoT 架构可适应不同类型的训练目标:
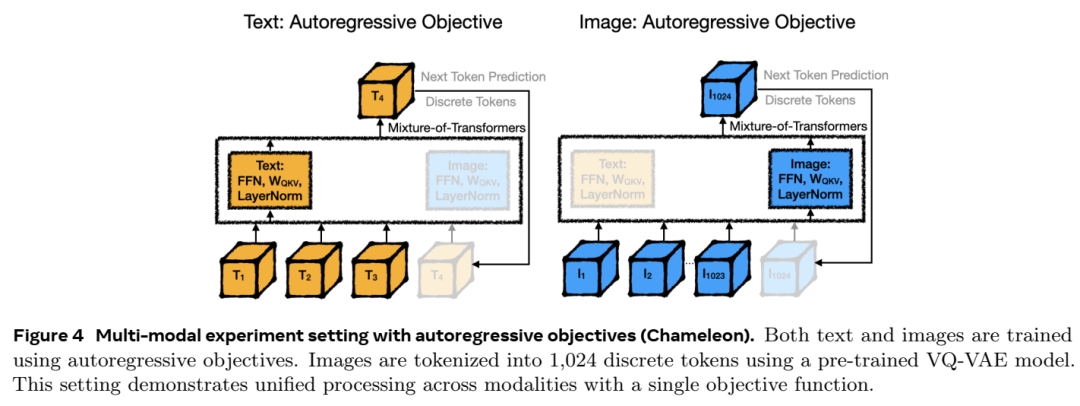
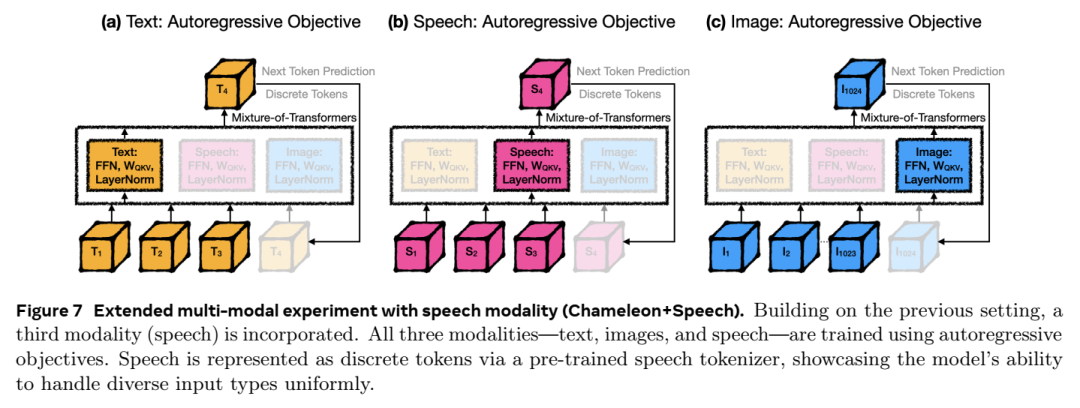
自回归(Autoregressive)目标:
在此设置中,模型用于文本生成等任务,根据离散标记预测序列中的下一个标记。这对于生成文本或其他顺序数据非常有用。
在这种情况下,图像标记表示为离散标记(例如,从预先训练的 VQGAN 模型生成)。
扩散(Diffusion)目标:
对于图像生成,该模型可以使用基于扩散的方法,该方法涉及通过多个步骤逐渐从噪声中细化图像
此设置可以实现图像的连续表示,从而可以提高图像质量和一致性。
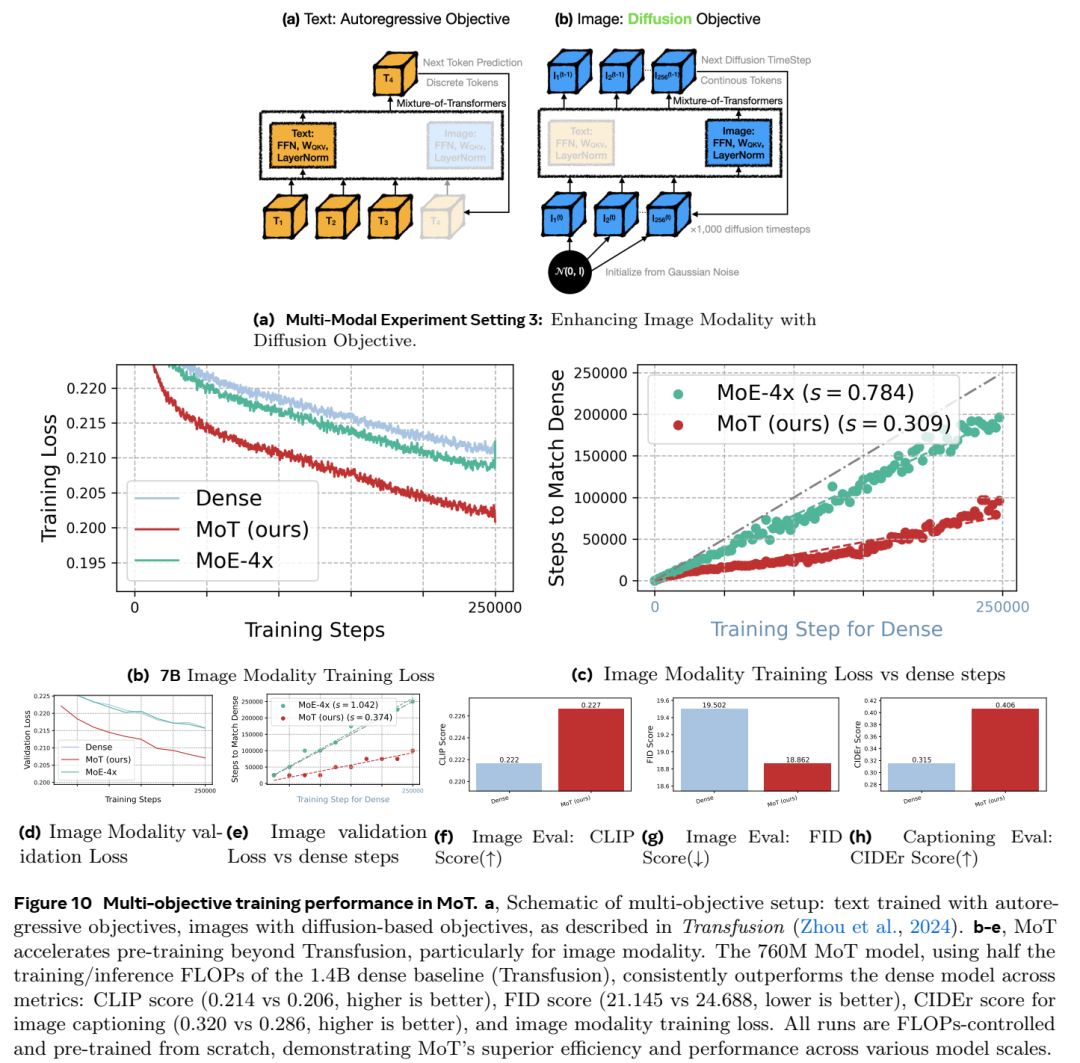
这种适应性使 MoT 适用于广泛的多模式应用,从文本和图像生成到多目标训练设置。
凭借这些功能,Mixture-of-Transformers 代表着高效多模态学习的重大进步。通过解耦每个模态的参数,它有效地解决了密集模型遇到的资源紧张和训练冲突,为可扩展、高性能的多模态 AI 铺平了道路。
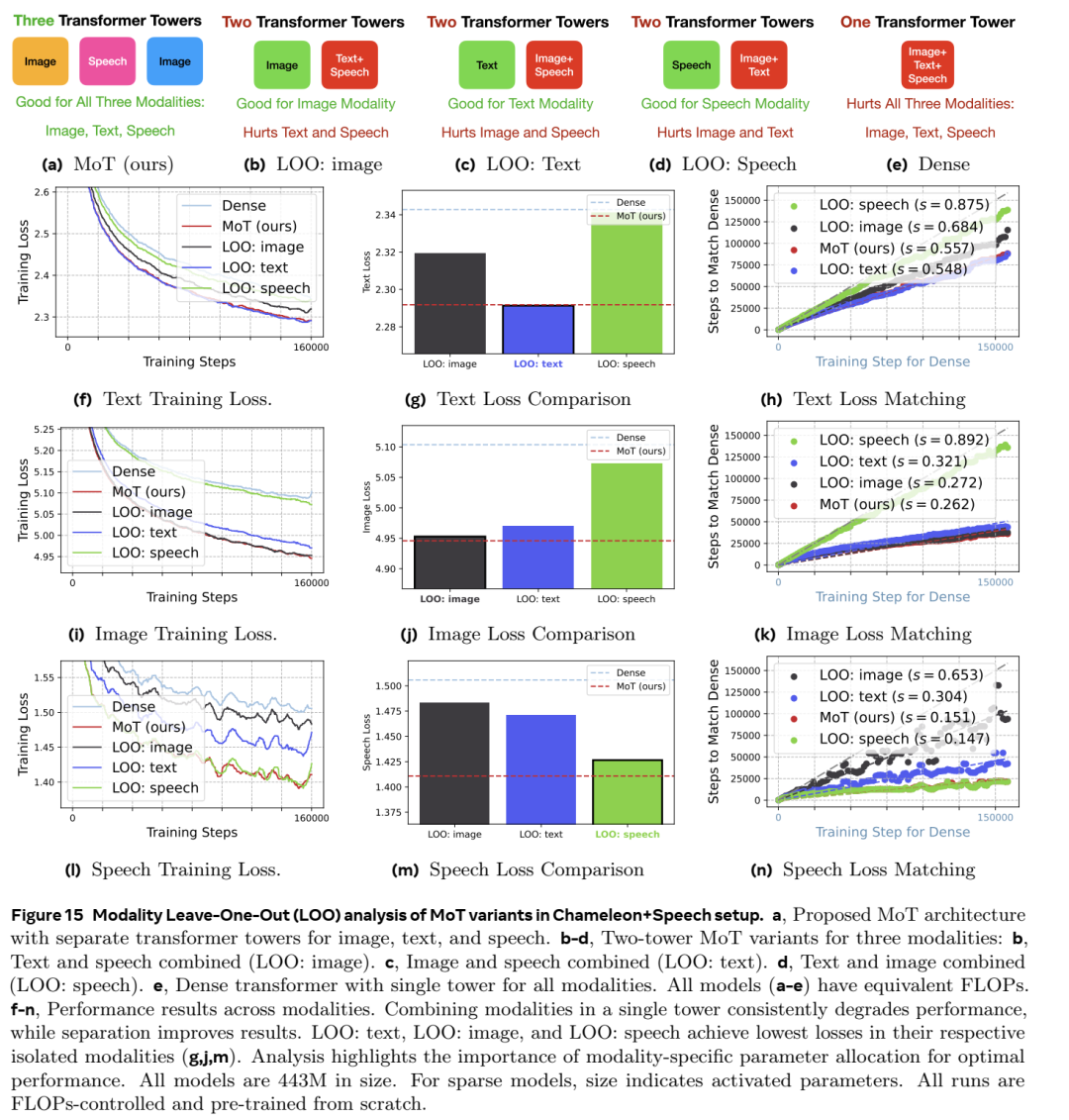
MOT计算算法

该算法描述了 Mixture-of-Transformers (MoT) 模型的计算过程,该模型是一种稀疏多模态转换器,旨在处理多种数据类型(模态),如文本、图像和语音。以下是算法中每一行的分步说明:
定义输入序列:输入序列表示为一组标记,x=(x1,…,xn),其中每个标记 xi 属于特定模态(文本、图像或语音)。
模态集合:M\mathcal{M}M表示模态集合,包括文本、图像和语音。
3–7.按模态分组和投影:
对于 M 中的每个模态 m:
8. 重建完整序列:在分别投影每个模态之后,投影 Q、K 和 V 统一为单个序列,恢复所有模态的原始标记顺序。
9. 全局自注意力:使用统一序列计算全局自注意力。此步骤允许跨序列中的所有标记进行交互,无论模态如何,从而实现跨模态学习。
10–15.应用特定模态层:
对于每种模态 mmm:
16. 返回输出:最后,算法在经过转换器层后返回每种模态的处理后的输出。
结论
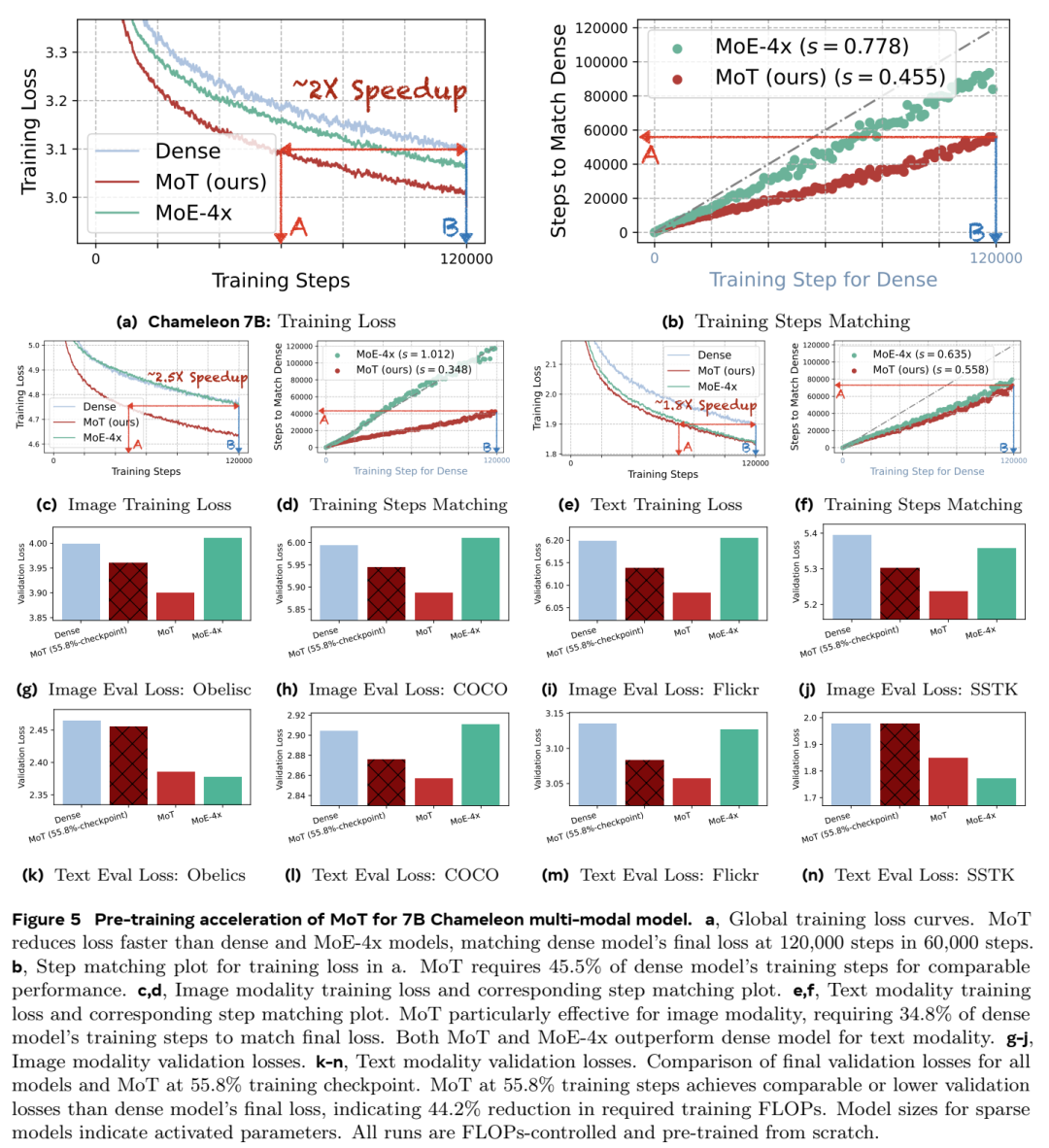
总之,混合 Transformers (MoT) 架构代表了多模态生成 AI 的重大进步。通过将特定模态层与共享注意力机制相结合,MoT 可以在单个模型中高效处理各种数据类型(文本、语音和图像)。这种方法可以最佳地处理每种模态,保留每种数据类型的独特特征,同时实现有意义的跨模态交互。
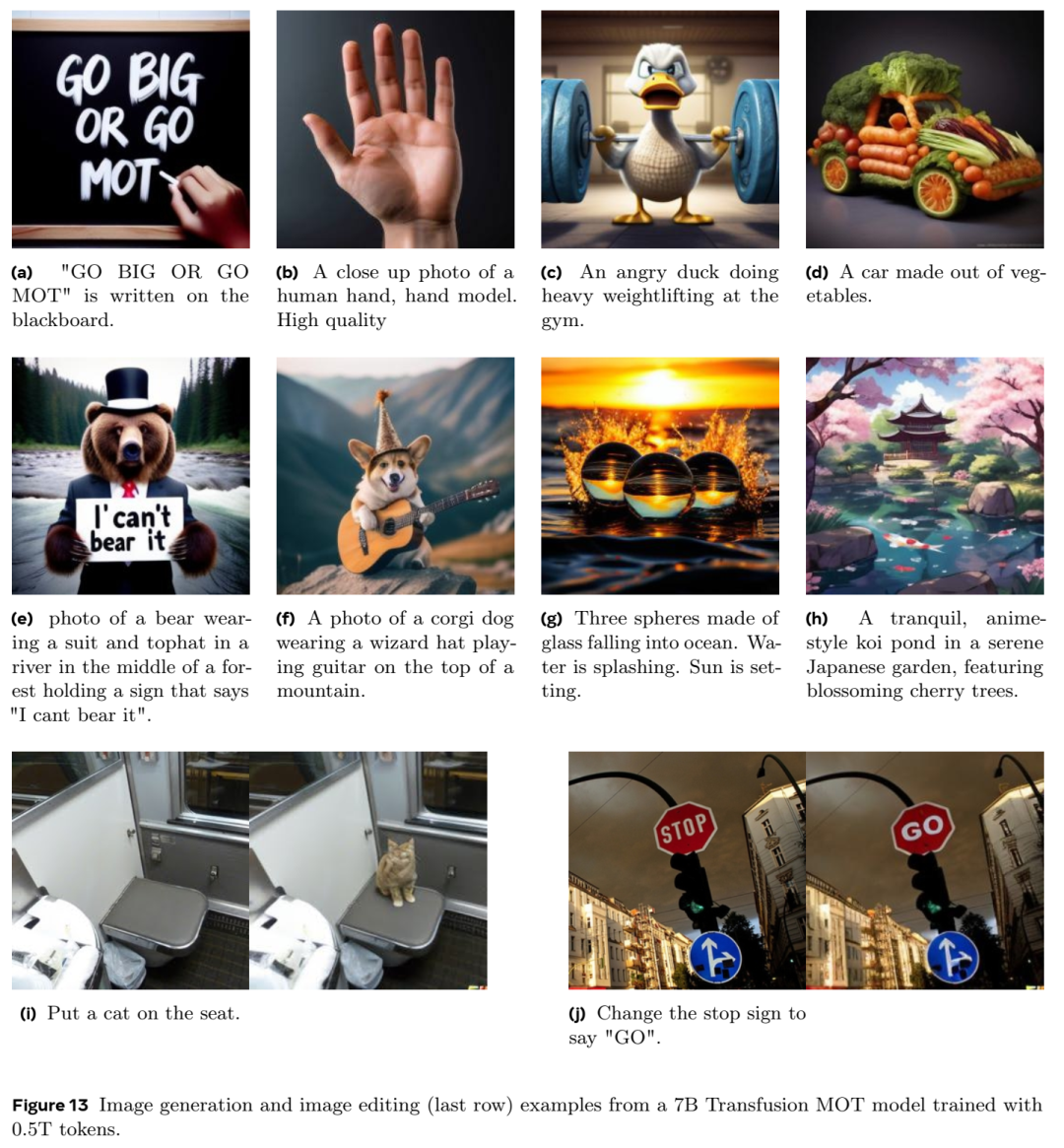
MoT 可以灵活地支持不同的训练目标,例如针对文本的自回归目标和针对图像的基于扩散的目标,这进一步凸显了其多功能性和适应性。凭借其高效、稀疏的设计,MoT 不仅降低了计算要求,还提高了多模态任务的性能,使其成为需要高效率、可扩展性和多模态理解的下一代 AI 模型的有前途的解决方案。

参考
Liang, Weixin, et al. “Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models.” arXiv preprint arXiv:2411.04996 (2024).



